
吃透Redis系列:琳琅满目的数据类型(下篇,文末彩蛋)
欢迎关注微信公众号: 互联网全栈架构
上一篇文章我们介绍了Redis的五种基本数据类型,详细内容请参见:吃透Redis系列:琳琅满目的数据类型(上篇)。除了这几种基本的数据类型外,Redis还提供了五种扩展数据类型,从使用频率上来讲,它可能不如基本数据类型那么高,但对于某些特定应用场景,它们能很好地满足,所以也有必要进行学习和了解,以便有备无患。 在文章的最后,我们用一张图来总结这十种数据类型的含义(毕竟,一图胜千言,更方便记住)。为了方便阅读,还是把这张数据类型的思维导图放出来: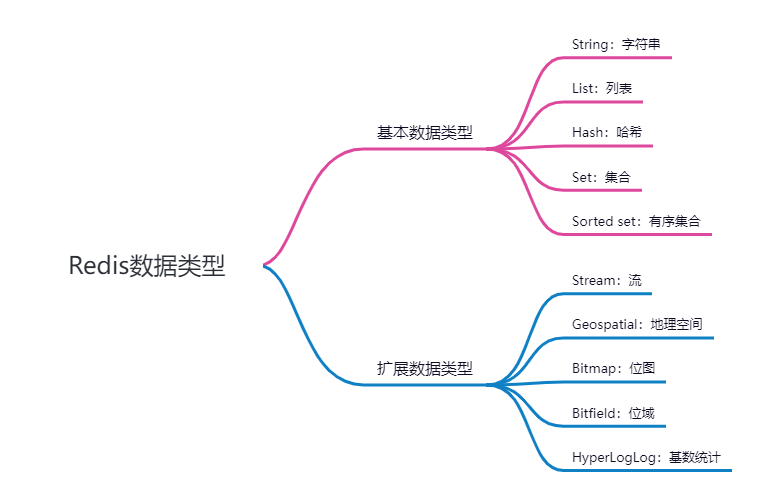
1
Stream
Stream是流的意思,它类似于一个日志追加(append-only)的数据结构,在实际应用中,它主要用于实现消息队列的功能,也可以用于记录和处理各种事件,或者作为一个通知系统,把消息推送给用户或者其他系统。 在Stream中,每条数据都被赋予唯一的一个序列号,可以使用这个序列号来获取关联的数据,或者处理Stream中后面的数据,这个序列号是随着时间顺序递增的。
Stream的一些常用操作(更详细的说明请参考官方网站):
#用于向Stream中添加消息
XADD key <* | id > field value [field value ...]
#从Stream中读取消息
XREAD [COUNT count] STREAMS key [key ...] id [id ...]
#获取指定范围内的消息
XRANGE key start end [COUNT count]
#返回消息的数量
XLEN key
示例:
127.0.0.1:6379> XADD mystream * name Tom age 23 height 178
"1709386483610-0"
127.0.0.1:6379> XREAD COUNT 1 STREAMS mystream 0
1) 1) "mystream"
2) 1) 1) "1709386483610-0"
2) 1) "name"
2) "Tom"
3) "age"
4) "23"
5) "height"
6) "178"
127.0.0.1:6379> XRANGE mystream - +
1) 1) "1709386483610-0"
2) 1) "name"
2) "Tom"
3) "age"
4) "23"
5) "height"
6) "178"
127.0.0.1:6379> XLEN mystream
(integer) 1
2
Geospatial
翻译过来是地理空间的意思,它可以用来保存坐标并进行搜索。对于地理位置和距离计算的需求,这种数据结构非常适合。地理位置使用经度和纬度来表示。 向key中添加地理位置的命令如下(其它命令参见官网):
#将一个或者多个位置添加到key中。其中longtitude是经度,latitude是纬度,member是地理位置的名称
GEOADD key longitude latitude member [longitude latitude member ...]
3
Bitmap
Bitmap就是位图,它不是一个真正意义上的数据结构,而是对于字符串类型的一些位操作,通过最小的单位bit来进行0和1的设置。使用它进行存储非常节省空间且运行效率高,比较适合活跃用户统计、登录天数计算、过滤器等应用场景。
Bitmap的一些常用操作:
#设置或者清除某一位上的值
SETBIT key offset value
#获取某一位上的值
GETBIT key offset
#统计1的数量
BITCOUNT key [start end [BYTE | BIT]]
示例:
# 比如统计登录天数,第一天在线,第三天在线,最后统计出来一共两天在线
127.0.0.1:6379> SETBIT user-login 1 1
(integer) 0
127.0.0.1:6379> SETBIT user-login 3 1
(integer) 0
127.0.0.1:6379> GETBIT user-login 3
(integer) 1
127.0.0.1:6379> BITCOUNT user-login
(integer) 2
4
Bitfield
Bitfield(位域),它把字符串当成位数组进行处理,它 可以操作任意位长度的整数,从无符号的1位整数到有符号的63位整数。 这些值是使用二进制编码的Redis字符串来存储的。 bitfield结构支持原子的读、写和增加操作,使它们成为管理计数器和类似数值的好选择。
5
HyperLogLog
HyperLogLog,它是用来做基数统计的,所谓基数,是指集合中不同元素的个数,而基数统计是指在允许误差的情况下估算出一组数据的基数。它经常用于统计网站的ip访问量、页面的uv数等场景。
HyperLogLog的一些常用操作:
#将任意数量的元素添加到HyperLogLog
PFADD key [element [element ...]]
#返回一个或者多个key的近似基数
PFCOUNT key [key ...]
#将多个HyperLogLog合并为一个HyperLogLog
PFMERGE destkey [sourcekey [sourcekey ...]]
示例:
127.0.0.1:6379> PFADD web-view "Tom" "John" "Tony"
(integer) 1
127.0.0.1:6379> PFCOUNT web-view
(integer) 3
127.0.0.1:6379> PFADD web-view2 "John"
(integer) 1
127.0.0.1:6379> PFMERGE web-view web-view2
OK
127.0.0.1:6379> PFCOUNT web-view
(integer) 3
6
总结
本文介绍了五种扩展数据类型,包括流、地理空间、位图、位域、基数统计等,它们对于一些互联网相关的业务需求非常适合,与传统的实现方案相比(比如采用关系型数据库),这些数据结构可能更有针对性、效率更高,使用起来也更为简便 。
为了方便记忆和理解,我们用一张示例图来总结这十种数据类型的含义:

创作不易,烦请点个在看、点个赞,非常感谢!
推荐阅读: