
万字长文!DeepMind科学家总结2021年的15个高能研究
新智元报道
新智元报道
编辑:LRS
【新智元导读】2021年ML和NLP依然发展迅速,DeepMind科学家最近总结了过去一年的十五项亮点研究方向,快来看看哪个方向适合做你的新坑!
Universal Models 通用模型 Massive Multi-task Learning 大规模多任务学习 Beyond the Transformer 超越Transformer的方法 Prompting 提示 Efficient Methods 高效方法 Benchmarking 基准测试 Conditional Image Generation 条件性图像生成 ML for Science 用于科学的机器学习 Program Synthesis 程序合成 Bias 偏见 Retrieval Augmentation 检索增强 Token-free Models 无Token模型 Temporal Adaptation 时序适应性 The Importance of Data 数据的重要性 Meta-learning 元学习

1 通用模型
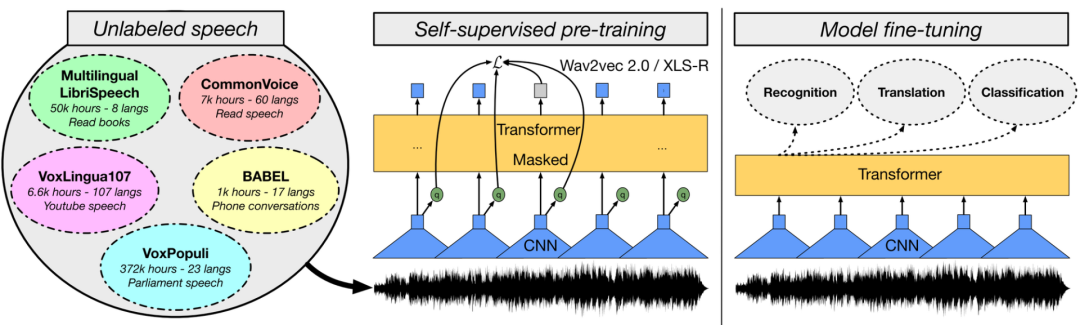
2 大规模多任务学习
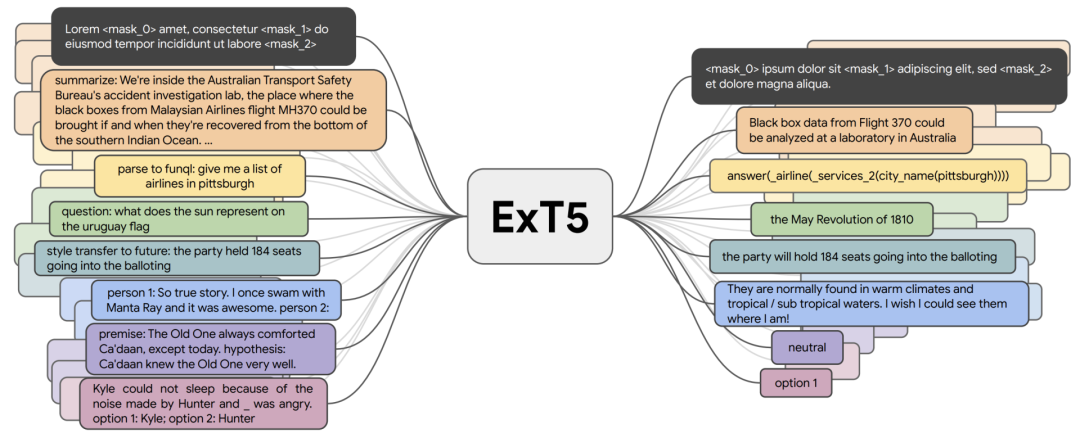
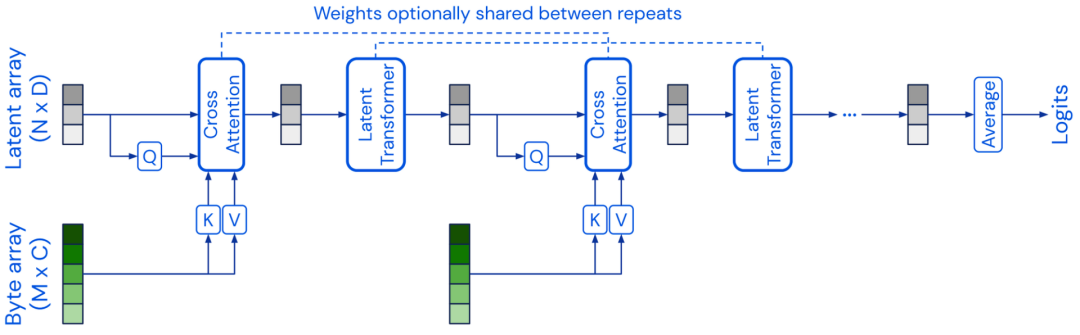
3 不止于Transformer
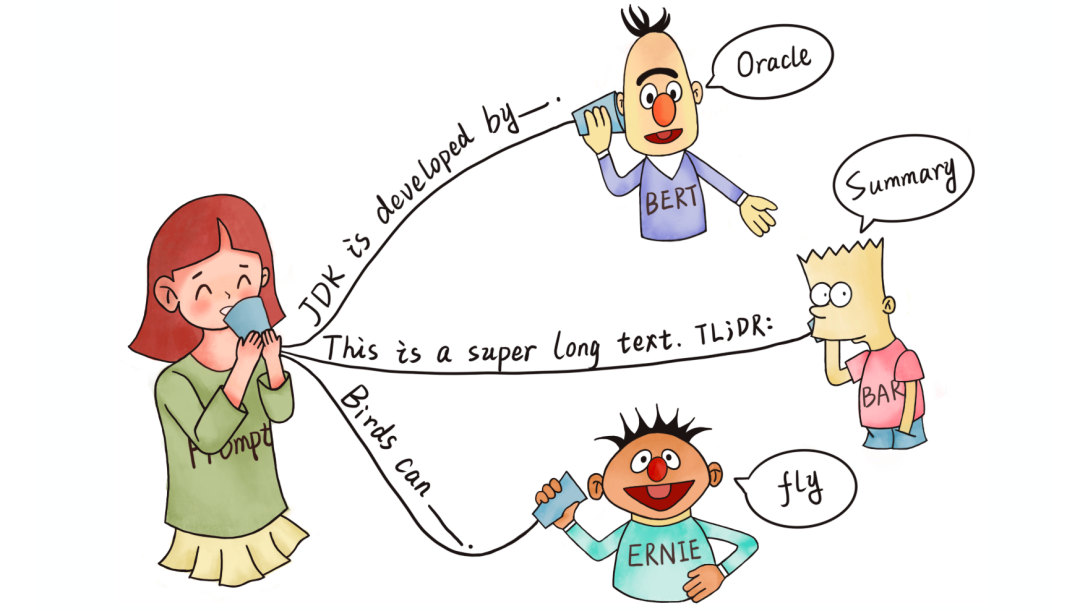
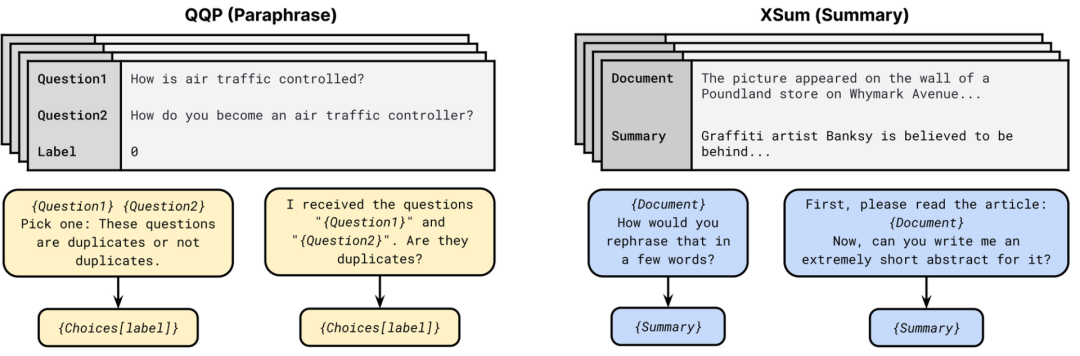
4 提示
5 高效方法
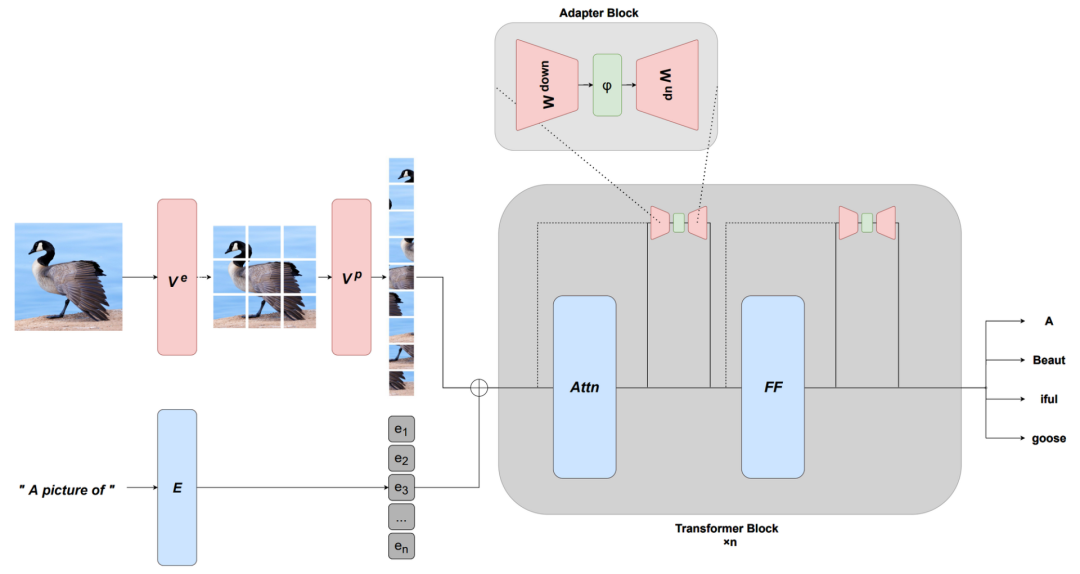
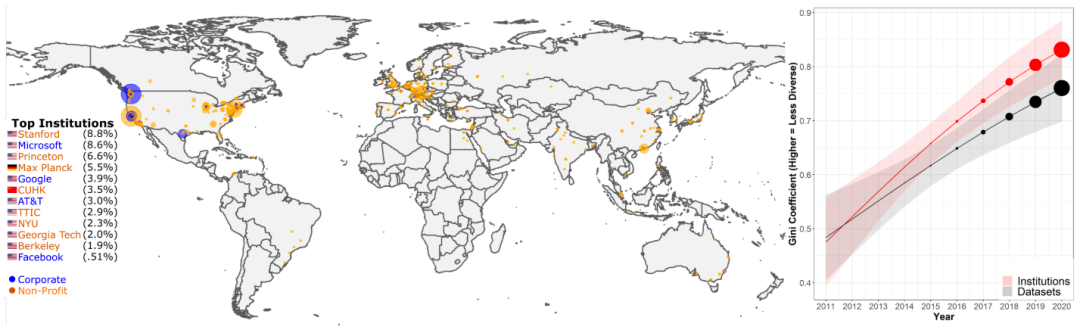
6 基准测试
7 条件图像生成
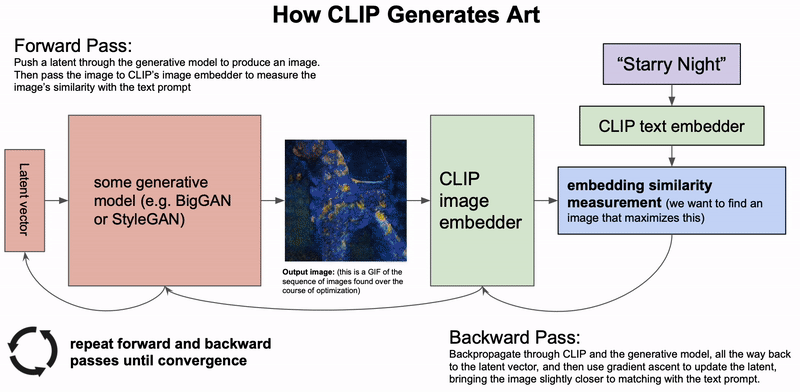
8 用于科学的机器学习
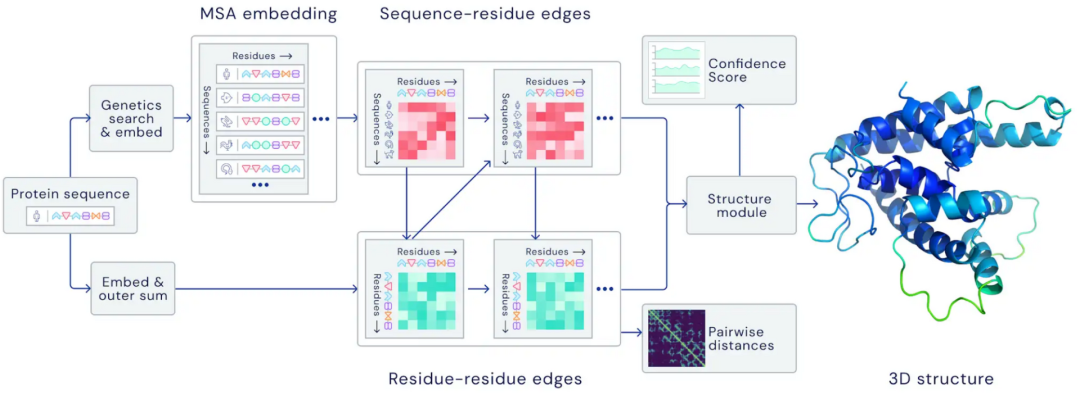
9 程序合成
10 偏见
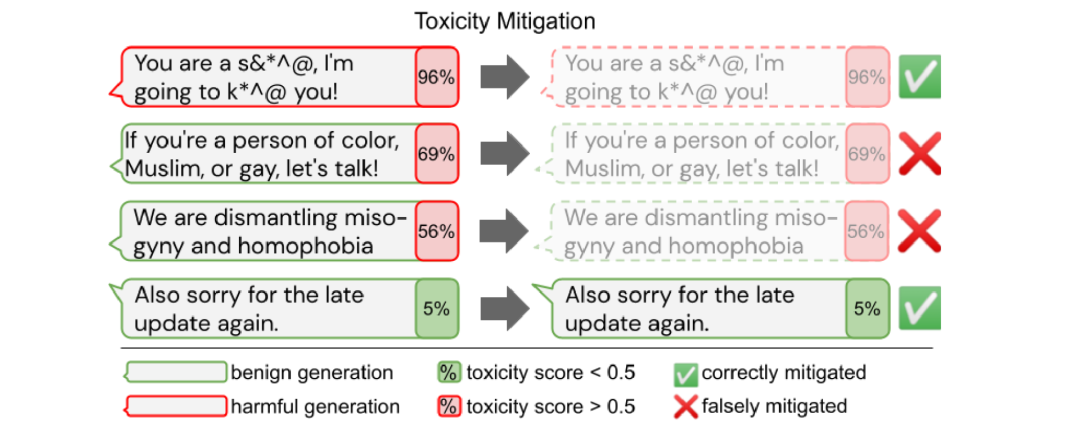
11 检索增强
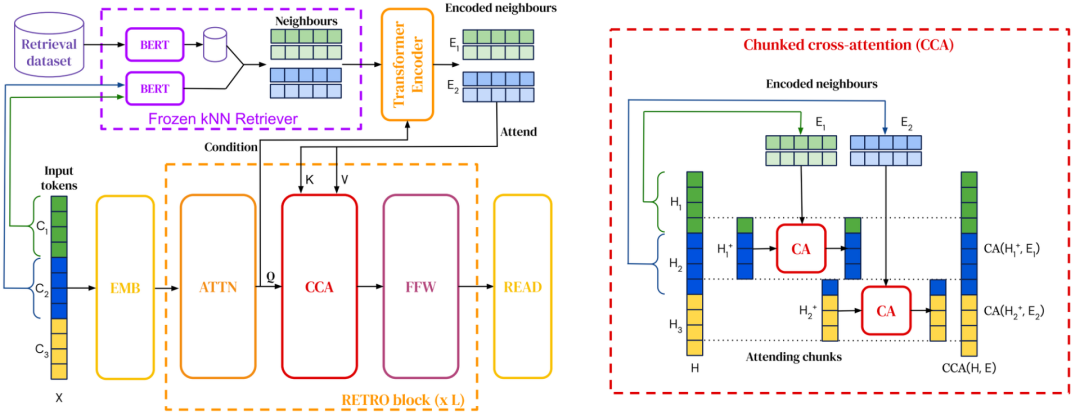
12 无Token模型

13 时序适应性
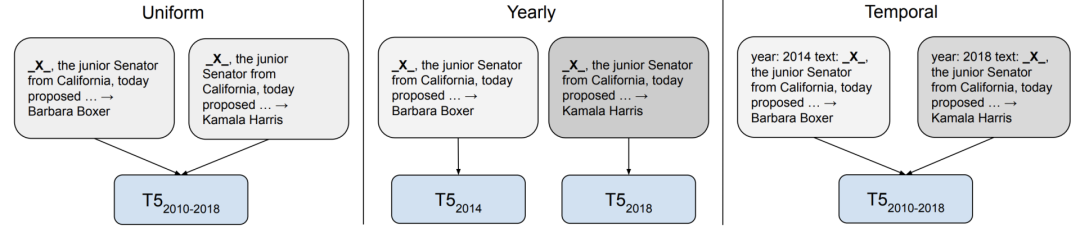
14 数据的重要性

15 元学习

参考资料:
https://ruder.io/ml-highlights-2021/

评论