
索引数据结构
数据库索引,是数据库管理系统中一个排序的数据结构,主要有
B树索引、Hash索引两种
一:B树索引
先来看下B树索引结构实列
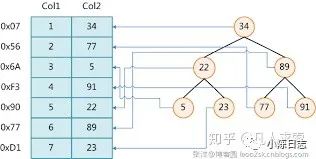
关于图的说明如下:
左边表示的是某个数据库的数据表,一共有两列七条记录,最左边的是数据记录的物理地址(就是在硬盘的存储位置)。为了加快对Col2这一列的查找,可以创建一个如右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在O(log2n)的复杂度内获取到相应数据。
举例子来看下,比如这样的一个查询
select * from tablename where Col2=5
这时候会先从Col2=34的根节点开始找,因为5小于34,会进入到左边的编号位22的子节点,依次向下推,就会找到Col2=5,这样就比用5和Col2中的每个数字来对比下要快的多了。
其实关于B树,大多数用的是B树的变种,主要有B-,B+树,关于这两个介绍,我帮大家找了两篇以漫画形式解释这两个概念的,比较容易理解,保证你看完后不会有这样的感觉

两篇通俗易懂的文章:
漫画:什么是B-树?
漫画:什么是B+树?
二:理解Hash树索引
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,这时疑问就来了,既然 Hash 索引的效率要比 B-Tree 高很多,为什么大家不都用 Hash 索引而还要使用 B-Tree 索引呢?任何事物都是有两面性的,Hash 索引也一样,虽然 Hash 索引效率高,但是 Hash 索引本身由于其特殊性也带来了很多限制和弊端,主要有以下这些。
1.Hash索引只支持等值比较,例如使用=,IN( )和<=>。对于WHERE price>100并不能加速查询
如果是等值查询,那么哈希索引明显有绝对优势,因为只需要经过一次算法即可找到相应的键值;当然了,这个前提是,键值都是唯一的。如果键值不是唯一的,就需要先找到该键所在位置,然后再根据链表往后扫描,直到找到相应的数据;
由于 Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
2.Hash 索引无法被用来避免数据的排序操作
由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash 运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
3.Hash 索引不支持多列联合索引的最左匹配规则
对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。
4.Hash索引在任何时候都不能避免表扫描
前面已经知道,Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash 表中,由于不同索引键存在相同 Hash 值,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash 索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
B+树索引的关键字检索效率比较平均,不像B树那样波动幅度大,在有大量重复键值情况下,哈希索引的效率也是极低的,因为存在所谓的哈希碰撞问题。
补充:
什么情况下会使用索引呢?
主键自动建立唯一索引
频繁作为查询条件的字段应该创建索引
查询中于其他表关联的字段,外键关系建立索引
频繁更新的字段不适合建立索引,因为每次更新不单单时更新了记录还会更新索引
where 条件里用不到的字段不创建索引
查询中排序的字段,排序的字段若通过索引去访问将会大大提高排序速度
查询中统计或者分组的字段
哪些情况不需要创建索引
表记录太少
经常增删改的表
如果某个数据列包含许多重复的内容,为它建立索引
就没有太多太大实际效果
关于这篇文章,希望大家能够多理解几遍,把索引的概念给吃透。