
mongodb-索引
前言
mongo 的索引数据结构是什么
mongo 中支持哪些索引类型
单个索引
复合索引
多键索引
地理空间索引
文本索引
Hashed索引
索引特性
唯一索引
部分索引
稀疏索引
TTL索引
覆盖索引
前缀索引
使用索引的奇淫技巧
组合索引的最佳方式 ESR 原则
合理使用部分索引
后台创建索引
怎么查看我到有没有用到索引?
前言
索引的重要性在数据库中是不言而喻的,mysql 中使用了 B+ 数来当做索引的数据结构,为 mysql 性能提升做了很大的贡献,那么在 mongoDB 中又使用了什么数据结构呢?今天就和大家聊聊 mongoDB 的索引
mongoDB 的索引数据结构是什么? mongoDB 支持哪些索引类型? 索引奇淫技巧 ? 怎么查看我到有没有用到索引?
mongo 的索引数据结构是什么
网上对 mongoDB 的数据结构有很多种说法,有说 B- 树的,有说 B 树的,还有说 B+ 树的
这里先说一个常识性的误区,「没有 B 减树」,B-tree 其实就是 B 树,中间的破折号只是用来连接而已,「只有 B 树和 B+ 树」

官方文档明确说到,在 WiredTiger 存储引擎当中,可以支持 B-Tree 和 LSM 两种结构组织数据,「默认使用 B+ 树」的数据结构在内存中维护表的数据,说 B 树也没错,因为 B+ 树就是 B 树的子集
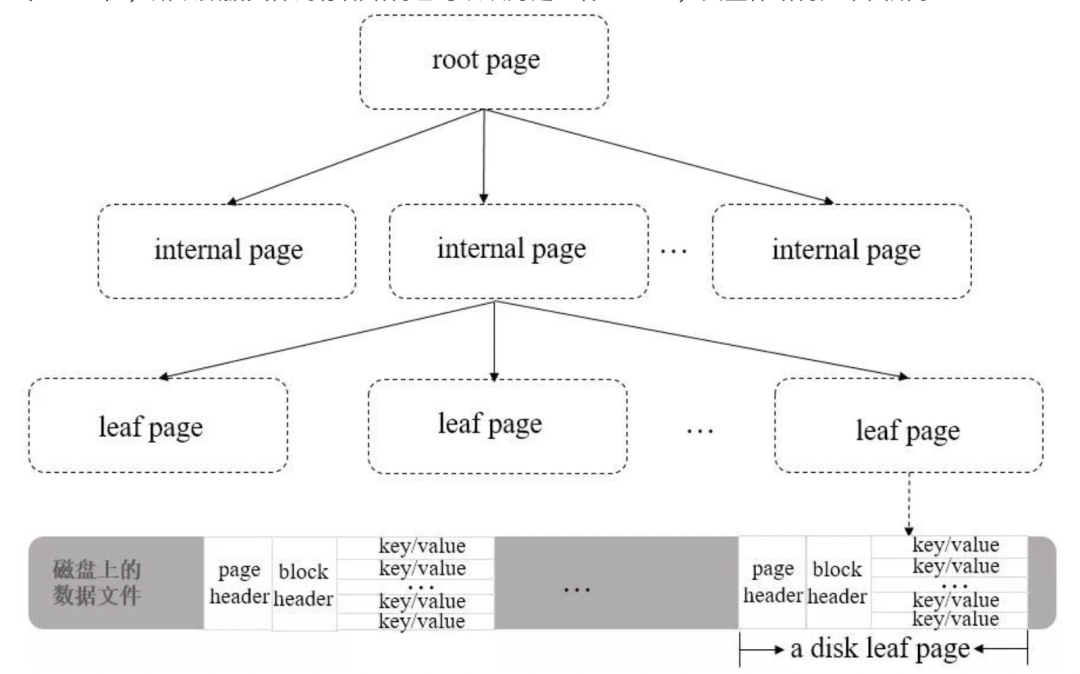
对于 WiredTiger 存储引擎来说,集合所在的数据文件和相应的索引文件都是按 B-Tree 结构来组织的,不同之处在于数据文件对应的 B 树叶子结点上除了存储键名外(keys),还会存储真正的集合数据(values),所以数据文件的存储结构也可以认为是一种 B+Tree
mongo 中支持哪些索引类型
单个索引
简而言之就是单个字段的索引,比如
db.children.createIndex({ age : 1 })
就相当于给 children 表的 age 字段建立了一个升序索引 (升序 ( 1) 或降序 ( -1) )
复合索引
符合索引其实就是多个字段自合成一个索引,比如
db.children.createIndex({ age : 1,height : 1 })
就相当于给 children 表 以 age 字段升序 height 字段升序建立了一个索引
多键索引
在MongoDB中可以「基于数组来创建索引」。MongoDB为数组每一个元素创建索引值。多键索引支持数组字段的高效查询,比如
([{ _id: 1, name: "xiaohong", age: "1", ratings: [ 1, 2, 3 ] })
db.children.createIndex( { ratings: 1 } )
但是对于一个复合多键索引,「每个索引最多可以包含一个数组」。比如以下情况就无法建立索引
([{ _id: 1, name: "xiaohong", age: "1", ratings: [ 1, 2, 3 ],teams:[ 1 , 3 , 4] })
db.children.createIndex( { ratings: 1 ,teams : -1} )
地理空间索引
为了支持对地理空间坐标数据的高效查询,MongoDB提供了两个特殊的索引:在返回结果时使用平面几何的2d索引和使用球面几何返回结果的2dsphere索引。有关地理空间索引的高级介绍,请参见2d Index Internals。
文本索引
MongoDB提供了一种文本索引类型,它支持搜索集合中的字符串内容。这些文本索引不存储特定于语言的停止词(例如**“the”,“a”,“or”**),并且在一个集合中只存储根词的词干。有关文本索引和搜索的更多信息,请参见文本索引。
Hashed索引
为了支持基于Hashed的分片,MongoDB提供了Hashed索引类型,该索引类型对字段值的Hashed进行索引。这些索引在其范围内具有更随机的值分布,但只支持相等匹配,而不支持基于范围的查询。
索引特性
唯一索引
在创建集合期间,MongoDB 在_id字段上创建唯一索引,这也是默认的唯一索引。该索引主要是为了区分文档并且不能删除。创建方式就是加上 unique: true
db.children.createIndex( { age : 1 }, { unique: true } )
部分索引
部分索引仅索引集合中符合指定过滤器表达式的文档。
比如 children 表中,将 age 大于 5 数据创建一个升序索引
db.children.createIndex(
{age:1},
{partialFilterExpression: {age: {$gt:5}}})
建立部分索引可以节省存储空间,提升索引查询效率。比如该文档 2000 年前的数据为垃圾数据,不常用,那就可以根据时间大于 2000 年创建索引
稀疏索引
索引的稀疏属性可确保索引仅包含具有索引字段的文档的条目。索引会跳过没有索引字段的文档。创建方式就是加上 sparse: true
db.children.createIndex( { "age": 1 }, { sparse: true } )
TTL索引
TTL 索引是 MongoDB 可以使用的特殊索引,它可以在一定时间后自动从集合中删除文档。
db.children.createIndex( { "lastModifiedDate": 1 }, { expireAfterSeconds: 5 } )
以上案例就是设置 5 秒后过去,使用方式只需要创建索引时加上 expireAfterSeconds: 5
覆盖索引
所有需要查询的数据都在索引当中,不需要从数据页中再去寻找数据
比如我此时为 children 表的时间创建了一个索引
db.children.createIndex({ age : 1 })
在此时我查找年龄为两岁的孩子时,就不需要从数据页中去寻找数据了
db.children.find({ age : 2 })
前缀索引
所有的前缀索引都可以被这条索引所覆盖,不需要再去针对这些前缀建立额外的索引,避免额外的开销
比如我此时为 children 表的时间创建了「一个复合索引(多字段索引)」
db.children.createIndex({ age : 1,name : 1,address : 1})
「那么其实这条索引等价于三条索引」,分别是
db.children.createIndex({ age : 1 })
db.children.createIndex({ age : 1,name : 1 })
db.children.createIndex({ age : 1,name : 1,address : 1})
使用索引的奇淫技巧
组合索引的最佳方式 ESR 原则
1.精准匹配(Equal)的放前面 2.排序(Sort)的放中间 3.范围匹配(Range)的方最后
比如一条查询语句
db.largeClass.find({className:"a",age:{$gte:5}}).sort(time:1)
最好的索引建立就应该是
{className:1,time:1,age:1}
E 放在最前面大家应该都能理解,用等值匹配去过滤掉大量数据,「那为什么是 ESR 不是 ERS 呢?」
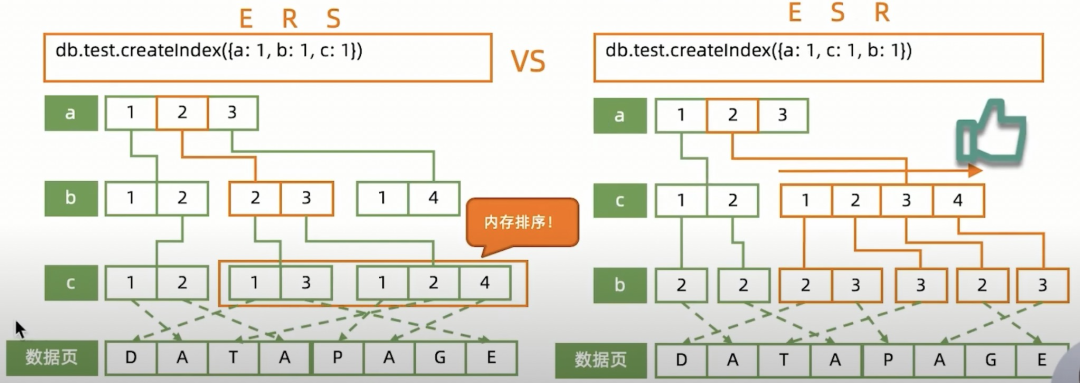
原因就是因为如果范围匹配放在中间,那么后续我们排序的时候只能进行「内存排序」,而内存排序又是很消耗资源的,数据量大时可能会「面对着多次的磁盘读取刷内存操作」,非常的消耗时间
合理使用部分索引
对于有些比较大的文档,可能很多数据都是无用的,比如文档中有三年的数据,但是业务只需要最近一年的数据,那么就可以只根据时间对最近一年的数据建立索引
后台创建索引
记得在创建索引时加上 {background: true},在后台创建索引,防止影响 mongoDB 的正常工作,让其自动调配创建时间
怎么查看我到有没有用到索引?
在 mongoDB 中提供了 「explain 执行计划」,可以清晰的看到你当前的查询语句时候有使用到索引,使用方式也很简单,只要在查询语句右面加上 .explain 就可以了,有几个「比较重要的属性」在这里说下
「executionTimeMillis」:指的是我们这条语句的执行时间
「docsExamined」:文档扫描数
「totalDocsExamined」:文档扫描条目
「totalKeysExamined」:索引扫描条目
「stage」:扫描类型,主要有
COLLSCAN:全表扫描
IXSCAN:索引扫描
FETCH:根据索引去检索指定document
SHARD_MERGE:将各个分片返回数据进行merge
SORT:表明在内存中进行了排序
LIMIT:使用limit限制返回数
SKIP:使用skip进行跳过
IDHACK:针对_id进行查询
SHARDING_FILTER:通过mongos对分片数据进行查询
COUNT:利用db.coll.explain().count()之类进行count运算
COUNTSCAN:count不使用Index进行count时的stage返回
COUNT_SCAN:count使用了Index进行count时的stage返回
SUBPLA:未使用到索引的$or查询的stage返回
TEXT:使用全文索引进行查询时候的stage返回
PROJECTION:限定返回字段时候stage的返回
所以当 「stage 为 IXSCAN」 的时候就是使用到了索引扫描