
C语言,把指针按地上摩擦,爽
不要陷在指针里面,最好的方法是跳出指针,我们从最终结果来思考问题。于是我的解题思路总是很偏,但是直指本质。
我们写一段代码:

编译,反编译,反编译这里我们用objdump -d hello >1.txt,如果你是用IDA,会发现出来的汇编不一样,因为各种格式的汇编,有不同的写法,这里主要就是Intel和AT&T,GNU遵循的是AT&T的写法。
在里面找到我们的add 和main
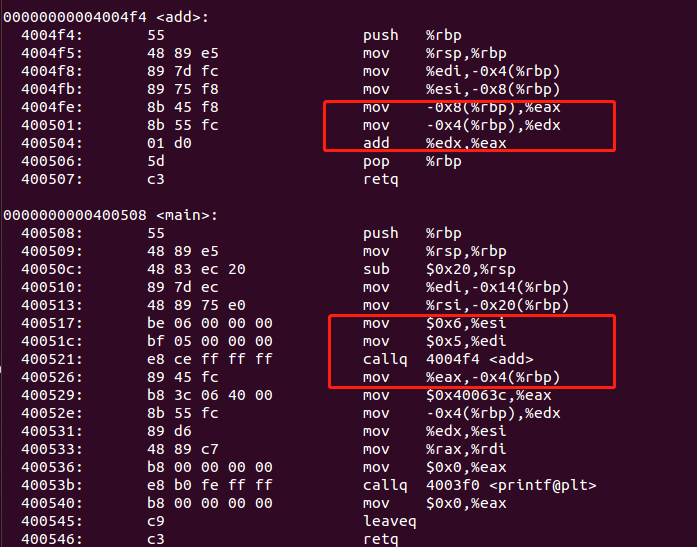
这里我不会展开去讲AT&T,这个玩意就是查表,我这里主要讲几个内容,这个非常重要。汇编语言中自己要关注堆栈平衡,再一个就是寄存器的保存与恢复,第三个就是调用参数约定。
举例来说,add %edx,%eax ,这个的结果在哪里?这个都是指令直接就决定的,也就是我们的CPU设计时候,它的这条指令执行完,数据会放在哪里。
我们看到的main方法中的
mov $0x6,%esi
mov $0x5,%edi
这两个就是我们add方法执行的两个参数,它赋值到这两个寄存器,那么在用这两个寄存器,是不是要把寄存器当前的值保存下来呢?所以你能看到紧挨着上面的就是保存动作。
然后callq 调用add方法,这里我们看紧跟着的 mov %eax ,-0x4(%rbp) ,我们刚才说了add方法执行后,eax里面是结果。
这里将%eax的值放到了 %rbp寄存器-0x4的地方,这个地方是什么?是栈,具体到代码中,就是sum的位置。
int sum =add(5,6);的执行过程就是这样的。我这里分享一个图,主要说的是传参的约定,我们知道调用函数时候是有参数的约定,其实二进制这里也是有的,这个叫做System V ABI 。

我一般是怎么掌握这些规则,去写汇编,一般就是用C写一些,编译,反汇编来看,这个大家可以参考一本书,

我们编译完的程序,是没有sum这个变量,在执行的代码中,都是变成了具体的位置,这里简单说下就是堆还是栈,局部变量是在栈上面,局部静态变量是在堆上面。
全局数据分两类,一类是初始化的全局变量,一类是未初始化的,未初始化的运行时候系统会默认给初始化为0(但是不要以为它就必须是0,这个就是跟运行机制有关,我们写代码一定记住,不要去尝试依赖外部不确定的因素)
全局数据区分为 data rodata 和 bss ,rodata这个就是read only,只读区域这个是由加载器加载程序进入进程时候,会对这个数据区域的page,做设定,设定只读,如果后续在这里写入数据,就会报错。
data就是我们常规的数据,举例就是 int a=100;这类全局变量会放在data区域。而我们如果是int a;这个全局变量,就会放置到bss,这个区域叫做全局未初始化区域,这个跟data的区别在于,这个bss在程序中不占用大小,只是在加载时候会在内存中占用大小。
text区域就是代码段。
说到这里,我这里再说一个内容,我们在看到代码时候,发现printf这个函数,后面有个plt。
我们来说下这个plt。plt的意思是,这个方法不在这个程序里面,是在外面的,而对应的位置,这里就是4003f0,这个位置是什么?我们知道printf是在glibc.so ,这里用的动态库。
我们程序要跑起来,是要补全这里的printf的执行块的,系统的做法就是,先放置一个占位位置,然后程序加载的时候,加载器知道这里需要一个printf的真实地址,这些需要放置地址的区域,统一在plt这个区域里面,在这个位置放入真正的printf的入口点。
听起来很绕,我们用一个例子,你就能明白了。但是这里的例子,估计又牵扯进来新的概念,大家先理解下吧。

typedef int (*operate)(int a,int b);这个定义了一个类型,类型是一个有两个参数,一个返回值的函数类型。我们平时的类型就是int,这里是一个函数的类型。
然后声明一个列表,把add,和sub放进来,我们直接调用即可。这里就想给大家说,这个是可以放置一个函数名的,等下我们继续操作,就能够更深入的理解这个函数名。
那么看到这里,我们开始真正进入指针的世界,我们来理解指针。我的操作就是,编译,反汇编,我们先看下代码:
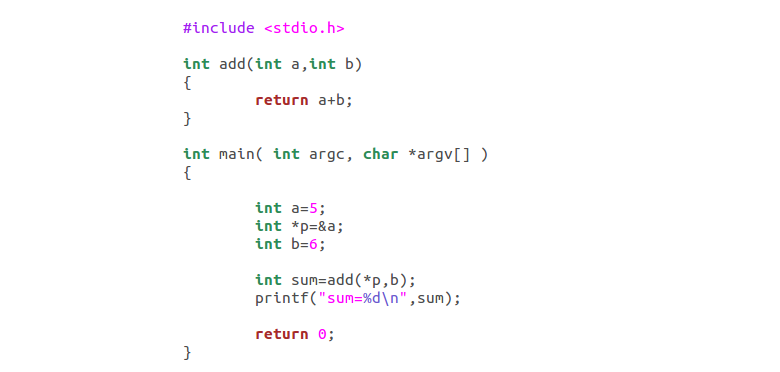
这里我们引入了指针p,储存了变量a的地址,然后*p代表拿出p地址里面的内容,我们看下反编译汇编,分析下这个过程。
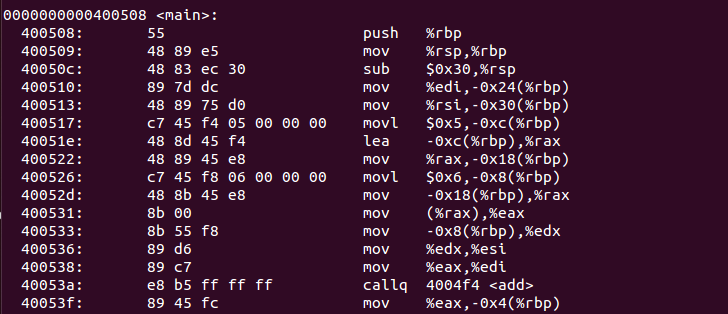
这里mov $0x5,-0xc(%rbp)将5放入rbp-0xc的位置。lea -0xc(%rbp),%rax mov %rax,-0x18(%rbp) 这两句话的意思是,拿到 -0xc(%rbp)的地址,放入 -0x18(%rbp)位置,也就是指针p的位置。
这里的mov (%rax),%eax 指的意思是,将rax里面的值读出来,找到这个值对应的地址的内容,存储到%eax里面,这里可以用c语言写就是,int c=*p;
从这里面我想说的就是,我们的指针,这些,在汇编形态下,不过是两种类型,一个是读取寄存器的值,一个是读取把寄存器中的值当做地址对应位置的值。
我们只要这样子去理解,基本上就能清晰的了解指针,指针所存储的值,我们一般都是用它所指向的地址内容,它本身的地址只是途径,类似于我们在图书馆查出来书的序号A-1-303,我们真正要的是这个位置的那本书。
当我们理解了这个,这里的add函数就是个地址,我们这么来看下。

我们直接用void *p=add;然后把这个p让编译器按照add对应的参数,返回类型去调用,这样子就可以用到add函数。
int 这类我们就能理解了,那么我们再来说下int[];这个看完汇编语句,一下子就明白了。我们说过一点,就是在真实的计算机上面,执行的是指令,指令理解就两类,一个是值,一个是地址,也可以理解成直接引用,间接引用。
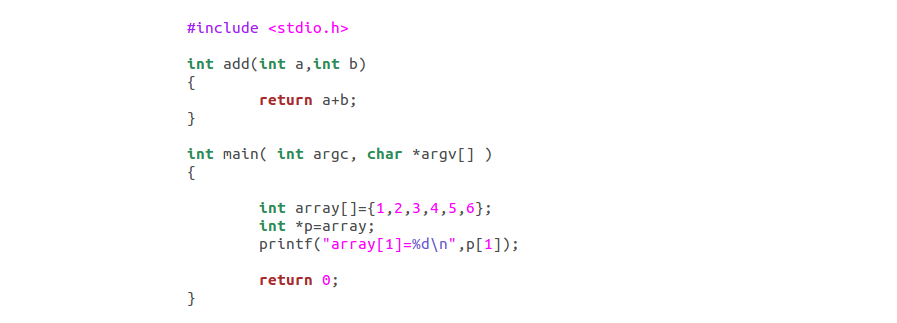
这里想说的是,array在编译器里面,就是理解成一个指针,指向了一个int数组。我们把array赋值到p指针,发现p[1]跟array[1]是一样的。我们看反汇编代码:打印语句改成printf("p[1]=%d,array[1]=%d\n",p[1],array[1]);,来比对下。
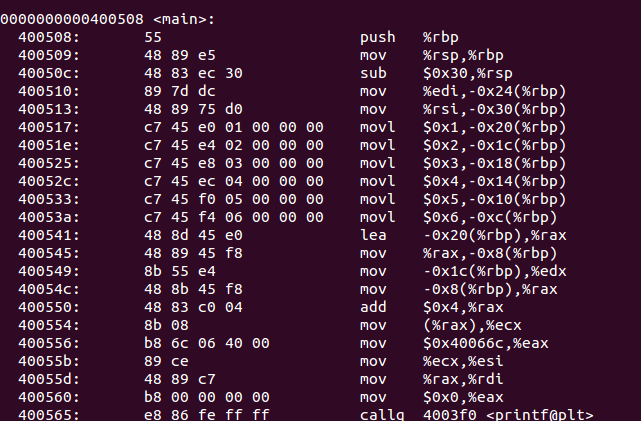
这里数组的取值,直接被优化了,直接用的mov -0x1c(%rbp),%edx 从上面的存储可以看到,这个位置直接就是array[1],具体指令是movl $0x2,-0x1c(%rbp),我们指针的获取,这里很明确,拿到数组起始地址,用add %0x4,%rax,进行了偏移,找到了p[1]位置。
这里分享下,地址的+1,指的是地址所指向的内容的大小,进行偏移。理解了这个,再去理解数组,就很好理解了。
我们把代码改成
long *p=array;
printf("p[1]=%d,array[1]=%d\n",(int)(p[1]),array[1]);
打印出来就不一样了,原因就是p+1,是加的sizeof(long) 的大小,也就是它所指向的内容所代表的大小。所以我们再来说下,
int array[3][5]={1,2,3,4,5,
6,7,8,9,10,
11,12,13,14,15};
然后 int (*p)[5] =array; 那么p[1][0]是多少呢?我们前面说了,p+1是依据它指向的大小,这里就是 int [5] 的大小,所以就是输出的6。这里也就是array实际就是一个指向一行五个int的一个数组指针。
核心一句话,指针的+1是根据指向的数据大小决定,同时在指令级别去看,只有两种解析,就是值和地址。
这一节有可能讲的太晦涩,后面我们再来讲一通。建议学习下x86汇编的寻址,再一个就是计算机组成原理,或许后面我们再讲一次指针,再花费一些力气把这块讲下。下一节我来说下,静态库和动态库怎么使用,两者的本质区别,以及设计的逻辑是什么。