
上帝视角任意切换:三维重建和图像渲染是怎么结合的?

极市导读
本文介绍了3D图像网站Photo Synth及其前身Photo Tourism,并讲解了它们的两大核心技术——点云重建和图像间的平滑切换。
一. 从PhotoSynth谢幕讲起



二. 14年前的研究项目-Photo Tourism
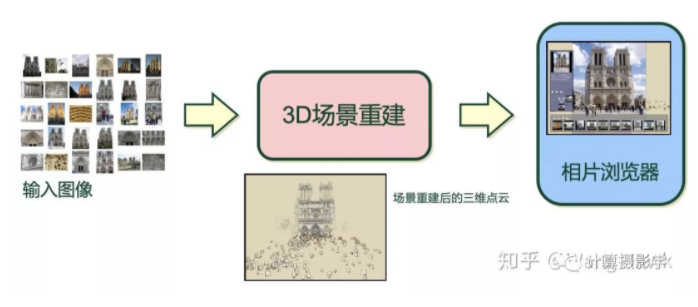
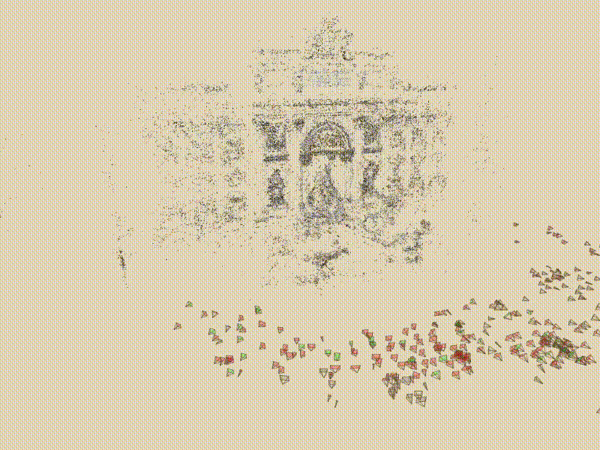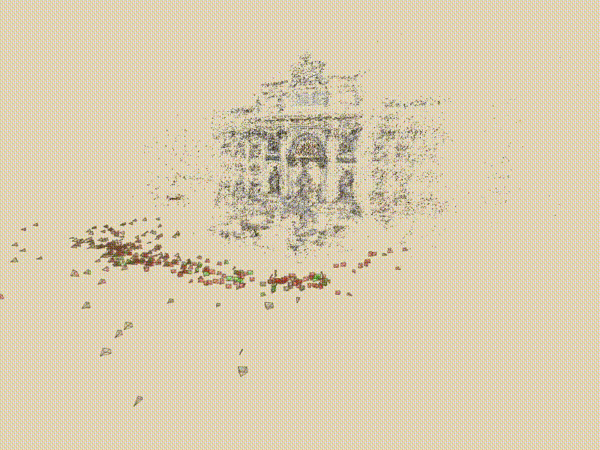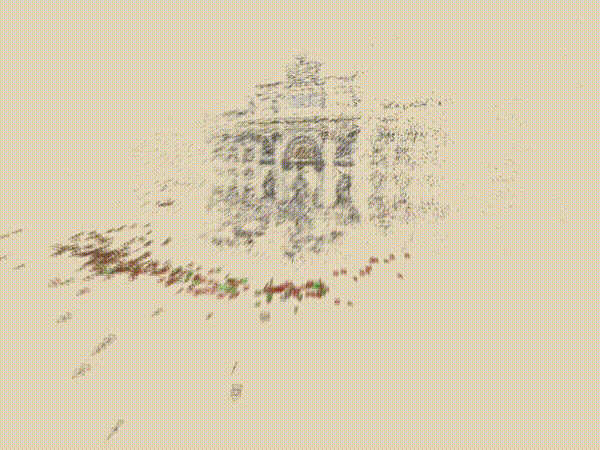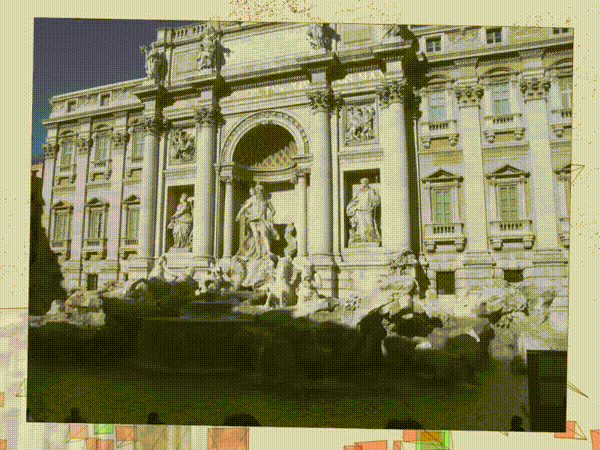








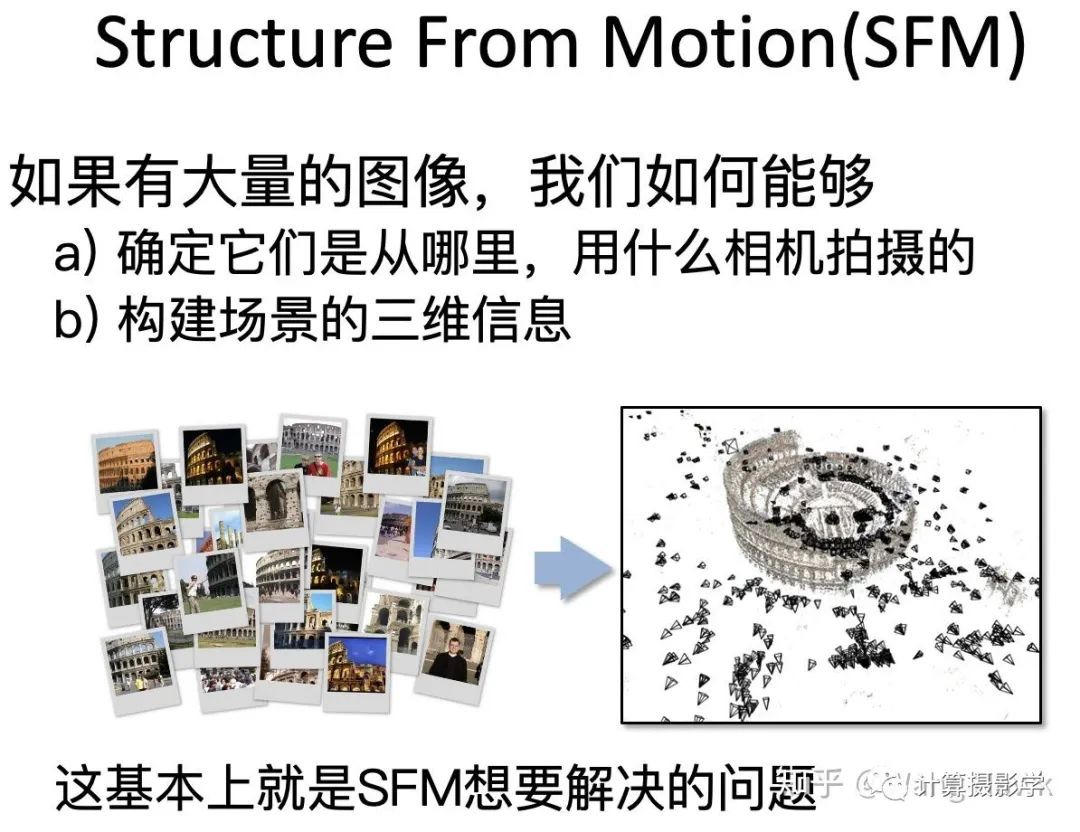
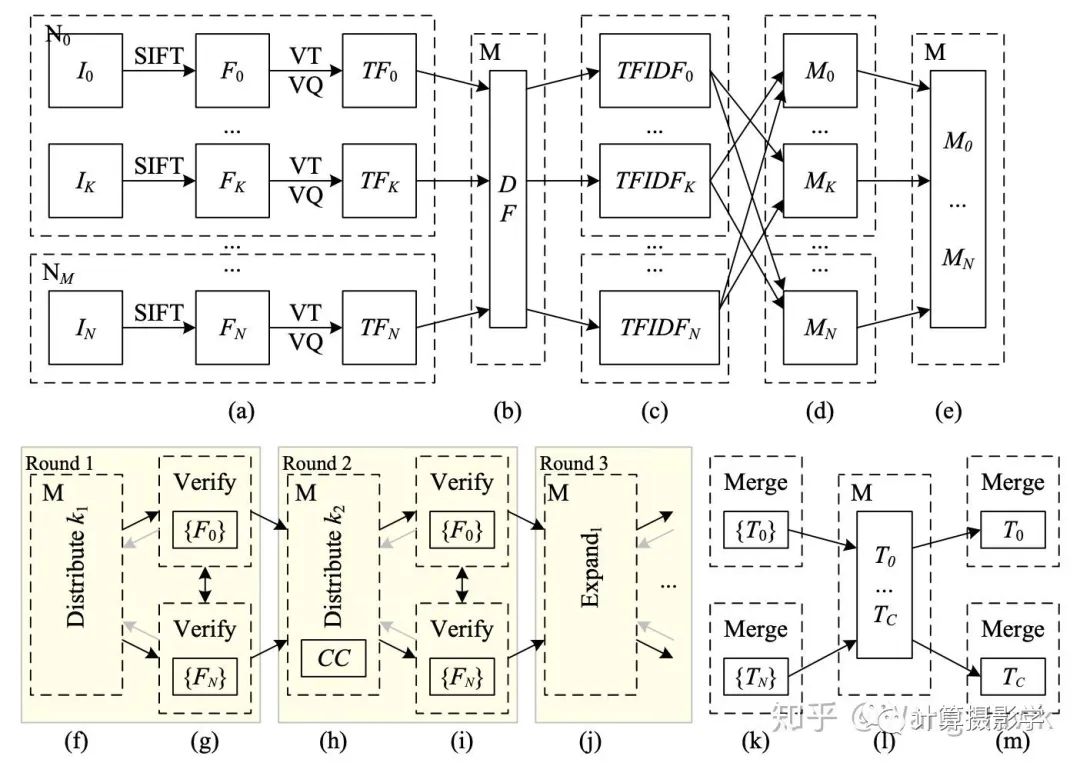
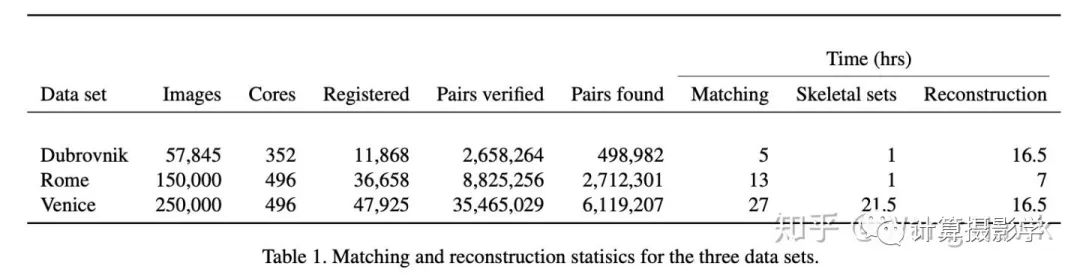
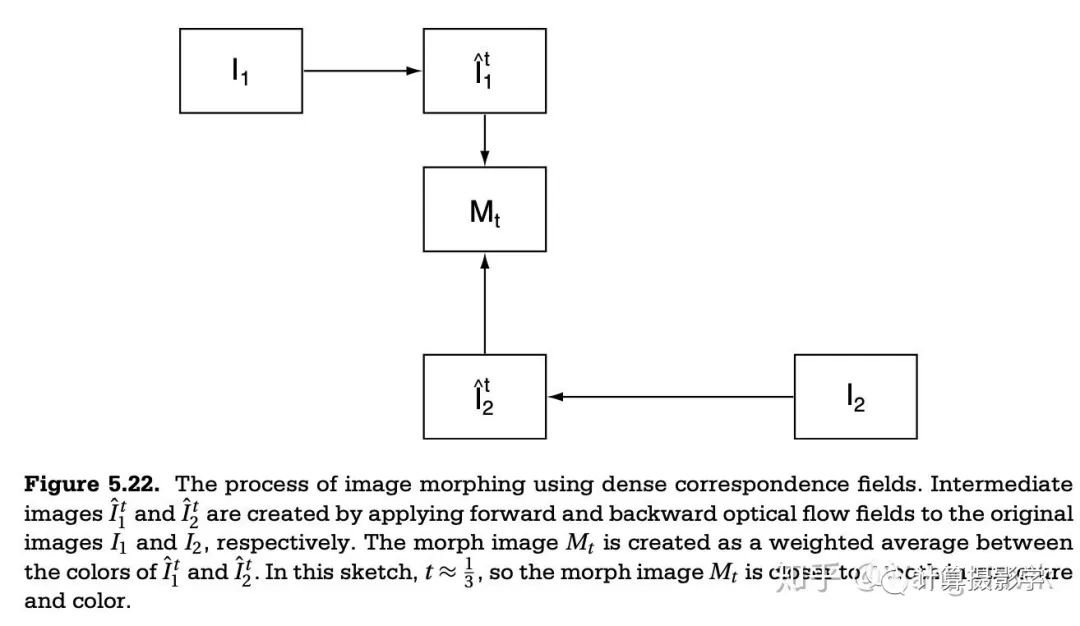
三. 核心技术简介
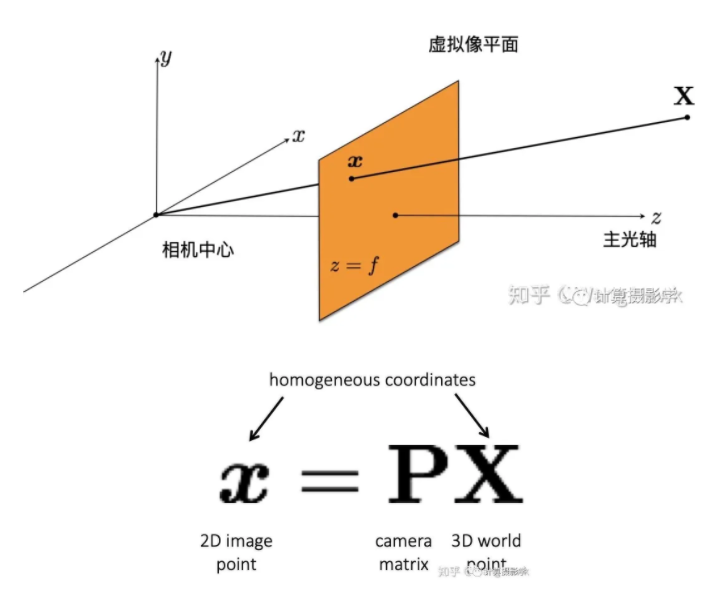
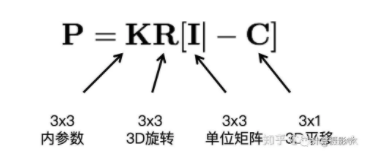
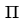 来表示),那么我们可以重新把Xi投影到三幅图像上。这些重新投影回图像的角点,和原来我们在图像上观察到的角点之间可能有一些误差,你可以看到X1实际上投影到了右边这幅图的绿色点上,和原来的红色角点之间就有了误差。
来表示),那么我们可以重新把Xi投影到三幅图像上。这些重新投影回图像的角点,和原来我们在图像上观察到的角点之间可能有一些误差,你可以看到X1实际上投影到了右边这幅图的绿色点上,和原来的红色角点之间就有了误差。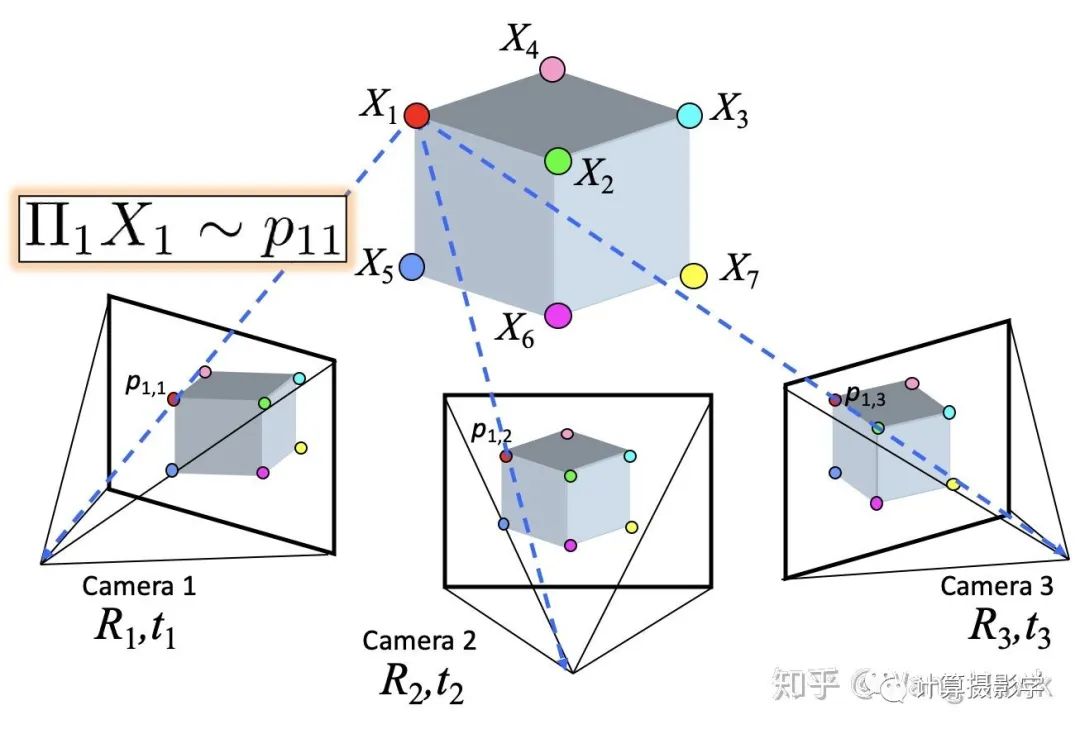
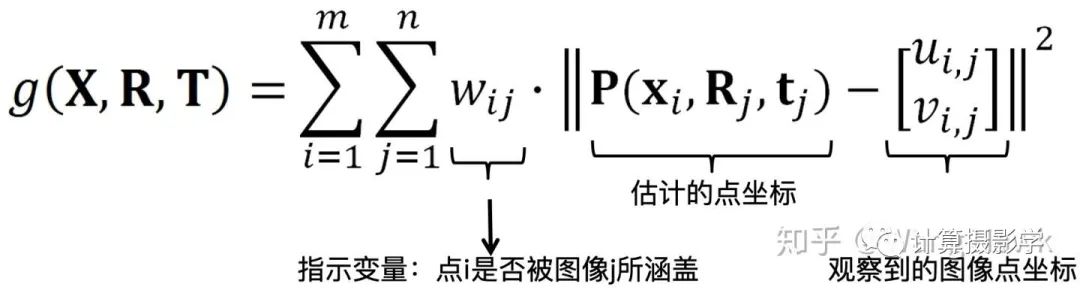


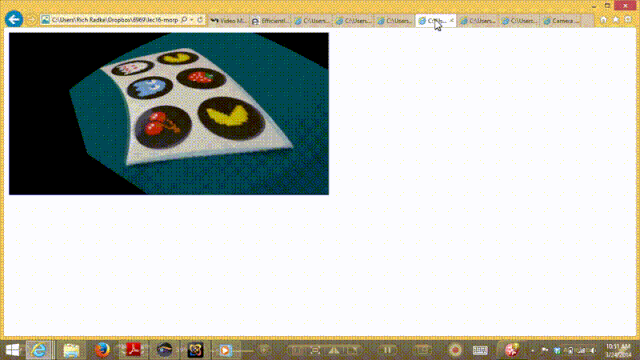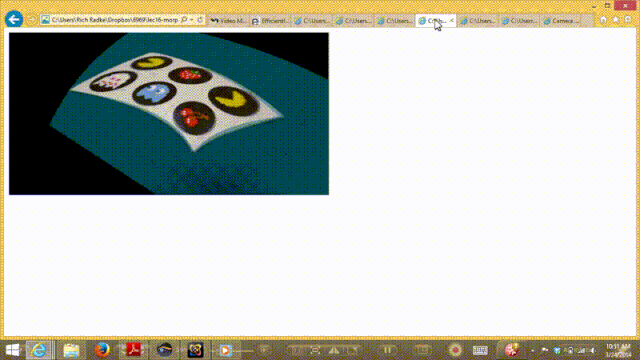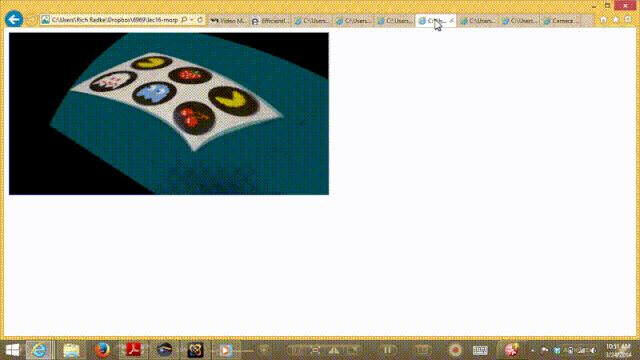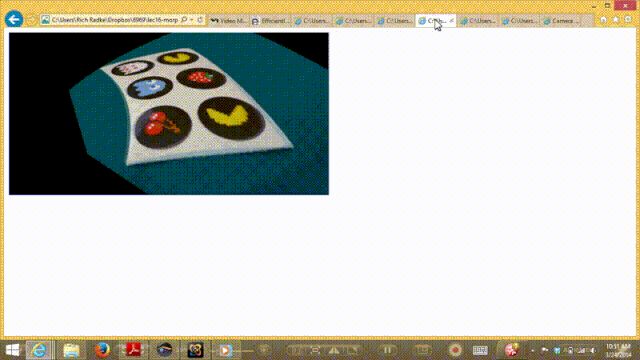
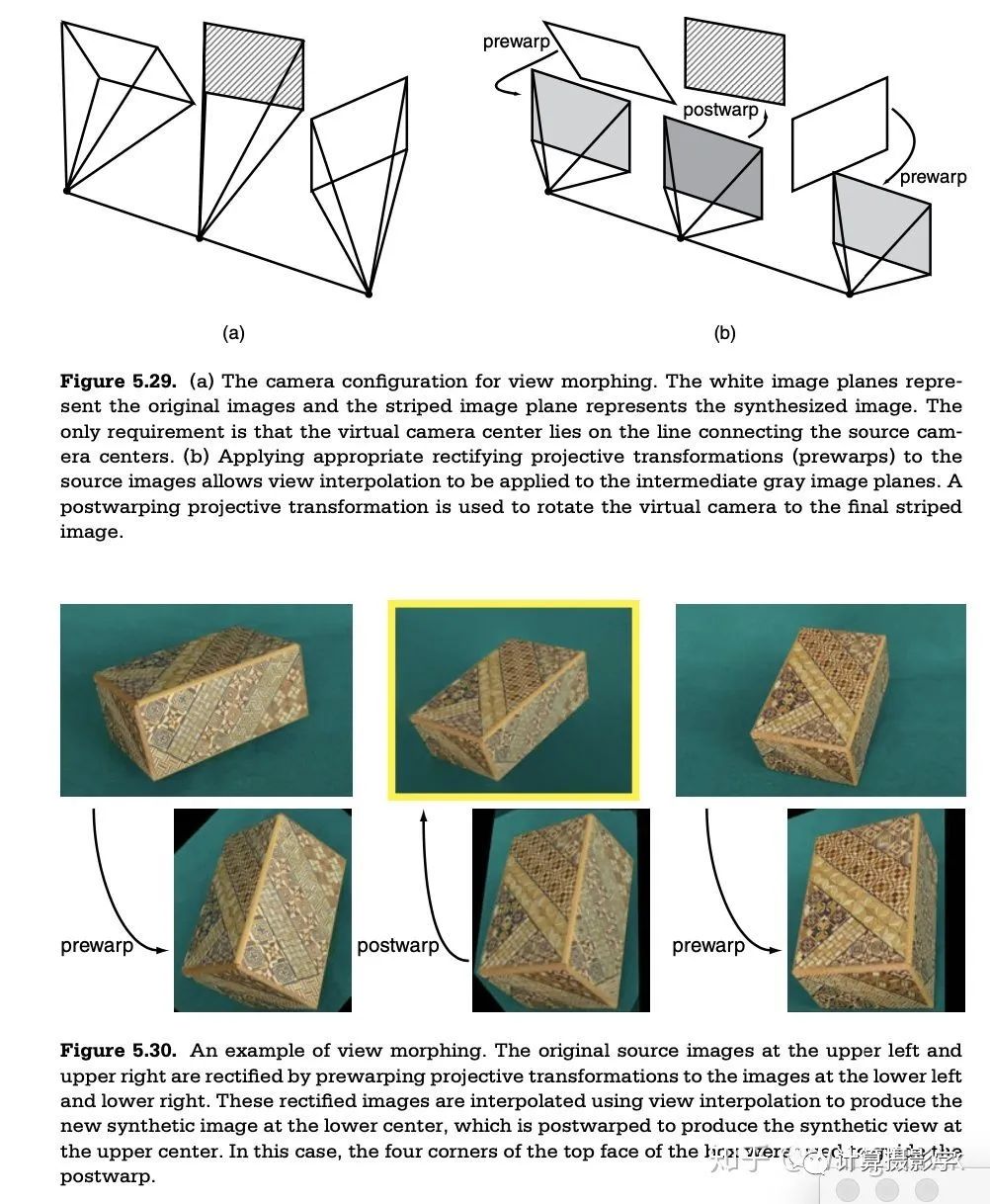
四. 总结
CMU 2017 Fall Computational Photography Course 15-463, Lecture 20
Photo Tourism项目页面上的视频、论文
Finding Paths through the World's Photos项目页面上的视频、论文
Rome in a day项目页面上的视频、论文
Computer Vision for Visual Effects主页上的视频,以及书籍本身
推荐阅读

评论