
一张图介绍机器学习中的集成学习算法
导读
机器学习在当下早已成为一项热门的技术,在众多机器学习算法中,除去深度学习和强化学习等最新发展方向,若是谈及经典机器学习算法,那么集成学习算法无论是在效果上还是热度上都是当之无愧的焦点。今天本文就来简要介绍那些经典的集成学习算法。
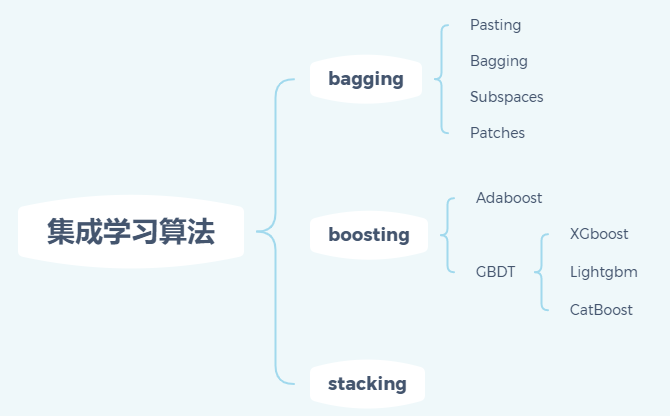
集成学习算法的三大派系
bagging,全称即为bootstrap aggregating,主要是通过并行独立地训练多个基学习器,而后采取投票或加权的方式融合多个学习结果,以期得到更为精准的结果,三个臭皮匠赛过诸葛亮就是这个道理; boosting,翻译过来即为提升的意思,是采取串行的方式逐一提升学习效果的方式,颇有后人站在前面巨人肩膀上的意味; stacking,"stack"是数据结构与算法中栈的英文,用在这里即表达集成的方式其实也隐藏了先后和递进的思想,不同于boosting的是:stacking是将众多基学习器的结果作为输入实现再训练的过程,有些类似于多层神经网络的思想。
仅对样本维度(体现为行采样)进行采样,且采样是有放回的,意味着每个弱学习器的K个采样样本中可能存在重复的样本,此时对应bagging算法,这里bagging=bootstrap aggregating。发现,这个具体算法的名字与bagging流派的名字重合,这并不意外,因为这是bagging中一种经典的采样方式,因而以其作为流派的名字。当然,bagging既是一种算法也是流派名,那就要看是狭义还是广义的bagging来加以区分了 仅对样本维度采样,但采样是无放回的,意味着对于每个弱学习器的K个采样样本是完全不同的,由于相当于是每执行一次采样,则该样本就被舍弃掉(pass),所以此时算法叫做pasting 前两者的随机性均来源于样本维度的随机采样,也就是行方向上,那么对于列方向上进行随机采样是否也可以呢?比如说每个弱学习器都选用所有的样本参与训练,但各学习器选取参与训练的特征是不一致的,训练出的算法自然也是具有随机性的,可以满足集成的要求。此时,对应算法叫做subspaces,中文译作子空间,具体说是特征维度的子空间,名字还是比较传神的 发现,既有样本维度的随机,也有特征维度的随机,那么自然想到有没有兼顾二者的随机呢,也就是说每个弱学习器既执行行采样、也有列采样,得到的弱学习器其算法随机性应该更强。当然,这种算法被称作是patches,比如前文已经提到的随机森林就属于这种。实际上,随机森林才是最为广泛使用的bagging流派集成学习算法。
如果说bagging的基本套路是以多取胜,那么boosting的基本套路则是车轮战!即boosting采取逐个基学习器递进训练的方式进行,通过不断弥补前面基学习器存在的短板和问题,来实现最终整体效果上的提升。这里,针对弥补短板的不同,boosting其实也存在两大方法:
Adaboost:针对前一轮预测错误的样本,不断加强对这些易错样本的权重,具体是通过对各样本分配不同的权重系数来实现。这就好比说一个学生能够针对历次学习考试建立自己的错题集,来实现有的放矢的提高;
GBDT:不断弥补前面训练的差距,实现整体效果上的逼近,具体是将真实值与预测值的差值等效为梯度的方法实现提升。
二者都是针对前一轮训练的弱点,加以针对性的弥补以实现训练得到更好的学习器。方法论是一致的,但当下的发展热门程度则天差地别。目前来看,Adaboost应用场合相对较为有限,并大有逐渐淡出大众视野的趋势,而GBDT的思想则更为火热,并日益衍生更多的迭代改进版本,例如当下最火热的三大集成学习算法就都是基于GBDT的改进提升:
Xgboost,这是对GBDT的第一个改进,源于AI大神陈天齐(本科是上海交大ACM毕业),与GBDT最大的差异在于对目标函数的改进(本质上是taylor一级展开到二级展开的改进),另有一些工程实现上的差异;
Lightgbm,这是在Xgboost的基础上做的进一步改进,源于微软团队。正如其名字中的light一样,lightgbm本质上是在达到与xgboost相近效果的基础上,大幅提高训练速度,这其中得益于三项算法或机制:①数值维度上,进行了基于直方图统计的分箱处理,简化了数据存储和分裂点的选取;②样本维度上,采取了单边梯度采样算法,避免低梯度样本的计算量;③特征维度上,采用了互斥特征捆绑(好吧,这个名字着实拗口),就是对多个稀疏特征进行合并,实现特征数量的降维。此外,Lightgbm与Xgboost的另一个显著区别是采用了leaf-wise的决策树生长策略,确保每次分裂都是有意义的;
Catboost,出道时间要略晚于Lightgbm,源于俄罗斯互联网巨头Yandex,其实也是对Xgboost的改进,最大不同是原生支持Cat型特征而无需转化为数值,另外也支持对缺失值的自动处理。不过在竞赛中的应用并不是很多。
从另一个角度来看,这三种算法也可视做分别源于中、美、俄……好吧,大国之争果真无处不在!
Stacking的思想其实可视为bagging+boosting的混合体,即先并行训练多个基学习器,而后以多个基学习器的训练结果为特征数据,进一步训练第二阶段的学习器,以期得到更为精准的结果。当然,照此流程,其实还可以训练第三波第四波,这就真的好似深度神经网络了……不过,可能也正因为其思想过于贴近于深度神经网络,所以Stacking方式的集成学习其实并未得到广泛应用。
相关阅读: