
手把手教你Python下载视频的三种姿势
点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
乘兴南游不戒严,九重谁省谏书函。
大家好,我是才哥。
咱们交流群的成员小王同学给我投稿了他的第一篇文章,希望大家多多支持啦!
相加交流群的可以在文末扫码小编微信添加,回复 加群 可以拉你进群哈!

今天和大家分享下我近段时间get的新技能,用单线程、多线程和协程三种方式爬取并下载梨视频的小视频,话不多说,我们开始叭。冲鸭冲鸭!

目标

将梨视频上的科技相关的视频资源下载保存到电脑本地
工具
Python3.9
Pycharm2020
需要用到的第三方库
1) requests # 发送请求
2) parsel # 解析数据(支持re, xpath, css)
3) fake_useragent # 构建请求头
4) random # 生成随机数
5) os # 操作路径/生成文件夹
6) json # 处理json数据
7) concurrent # 处理线程池
8) asyncio, aiohttp, aiofiles # 处理协程
分析并使用单线程下载视频
我们需要将梨视频网站上的视频资源下载到电脑本地,那必不可少的两个元素必然是视频名称和视频资源url。获取视频资源url后,针对视频资源的url发起请求,得到响应,再将响应内容以视频名称为名保存到电脑本地即可。
起始页:科技热点资讯短视频_科技热点新闻-梨视频官网-Pear Video
URL地址:https://www.pearvideo.com/category_8
1.分析起始页
F12对起始页刷新抓包,拿到数据请求接口
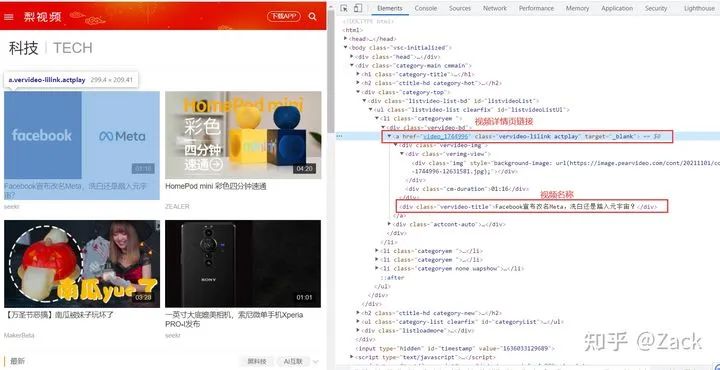 梨视频(科技)主页
梨视频(科技)主页
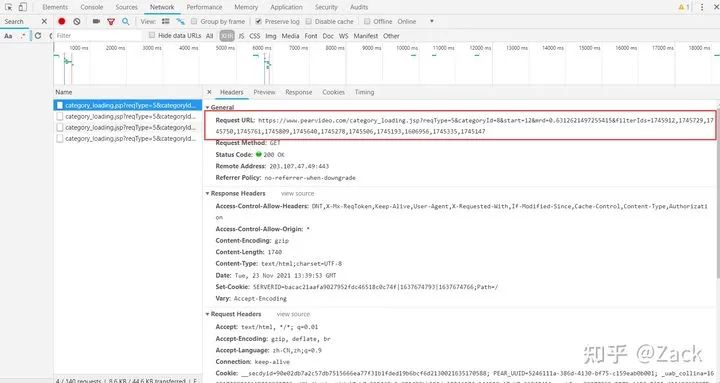
对比观察抓包获取到的url:
https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=12&mrd=0.6312621497255415&filterIds=1745912,1745729,1745750,1745761,1745809,1745640,1745278,1745506,1745193,1606956,1745335,1745147
https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=24&mrd=0.9021185727219558&filterIds=1745912,1745729,1745750,1745254,1745034,1744996,1744970,1744646,1744743,1744838,1744567,1744308,1744225,1744727,1744649
https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=36&mrd=0.6598737970838424&filterIds=1745912,1745729,1745750,1744642,1744353,1744377,1744291,1744127,1744055,1744106,1744126,1744040,1743939,1743997,1744012
对比上方三个url可见,除了其中的start, mrd以及filterIds不同之外,其余部分均为https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=。其中start每次增长为12,即每次加载12段视频;mrd为一个随机数,filterIds即为视频资源的cid号。
2. 发送起始页请求
我们可以根据抓包获取到的信息构建请求,获取响应内容。全文将模仿scrapy框架的写法,将代码封装在一个类之中,再定义不同的函数实现各个阶段的功能。
# 导入需要用到的模块
import requests
from parsel import Selector
from fake_useragent import UserAgent
import random
import json
import os
创建类并定义相关函数、属性
class PearVideo:
def __init__(self, page):
self.headers = {
"User-Agent": UserAgent().chrome, # 构建谷歌请求头
}
self.page = page # 设置要爬取的页数
self.base_url = "https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start="
def start_request(self):
for page in range(self.page):
start_url = self.base_url + str(page * 12) # 拼接起始页url
res = requests.get(start_url, headers=self.headers)
if res.status_code == 200:
# 将获取到的请求转换成一个parsel.selector.Selector对象,之后方便解析文本;
# 类似scrapy框架中的response对象,可直接调用re(), xpath()和css()方法。
selector = Selector(res.text)
self.parse(selector)
获取到响应之后就可以解析响应文本了,在响应文本中我们可以提取到视频的详情页url及视频名称,代码如下:
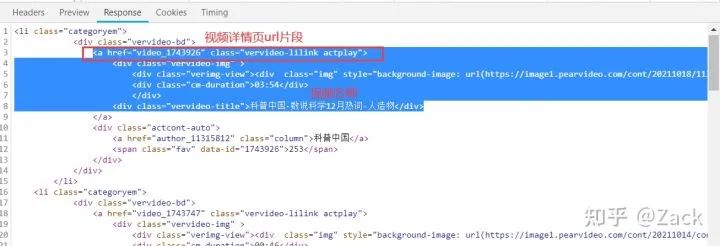
3. 解析起始页响应获取视频名称、视频详情页url
def parse(self, response):
videos = response.xpath("//div[@class='vervideo-bd']")
for video in videos:
# 拼接视频详情页url
detail_url = "https://www.pearvideo.com/" + video.xpath("./a/@href").get()
# 提取视频名称
video_name = video.xpath(".//div[@class='vervideo-title']/text()").get()
# 将视频详情页url和视频名称传递给parse_detail方法,对详情页发送请求获取响应。
self.parse_detail(detail_url, video_name)
在浏览器中打开视频详情页,按F12观察浏览器渲染之后的代码可见视频资源的url, 如下图所示:
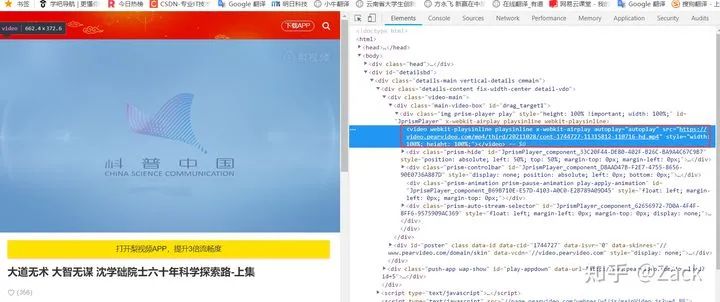 此处的视频资源url为:
此处的视频资源url为:
https://video.pearvideo.com/mp4/third/20211028/cont-1744727-11315812-110716-hd.mp4
但是实际获取视频详情页响应后,并没有找到视频资源的url,能找到的只有一张视频图片预览的url,如下图所示(可在浏览器视频详情页,鼠标右键查看网页源代码获取):

于是,我们再次针对视频详情页抓包,找到视频资源url的相关请求和响应内容,如下图所示:
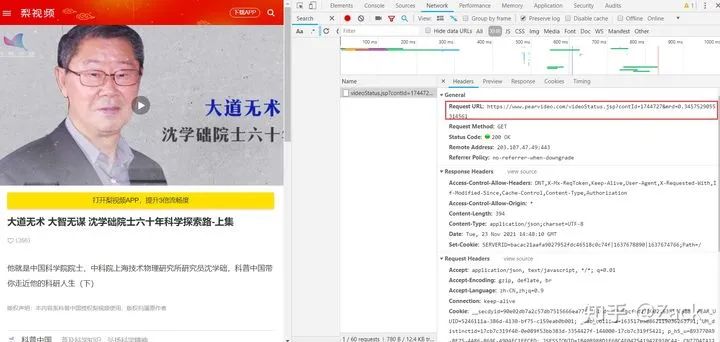
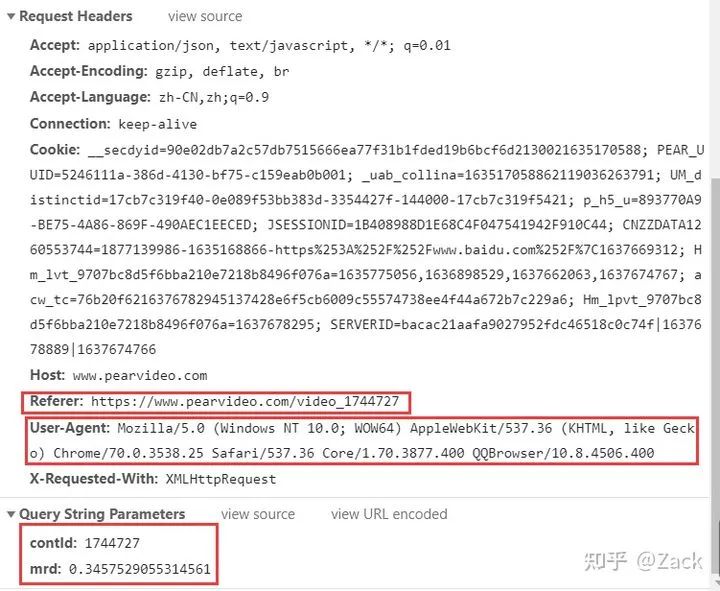
其中的contId即为详情页响应的data-cid属性值(详见下文),而mrd为一个随机值,可通过random.random()生成,在发送请求的时候Referer必不可少,否则将无法获取到正确的响应内容。
点击preview,可以查看请求的响应结果,如下图所示:
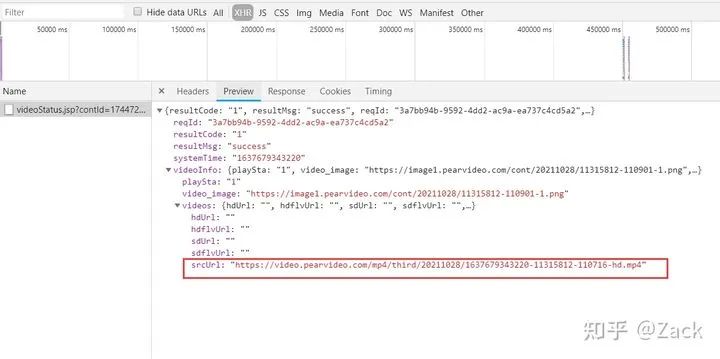
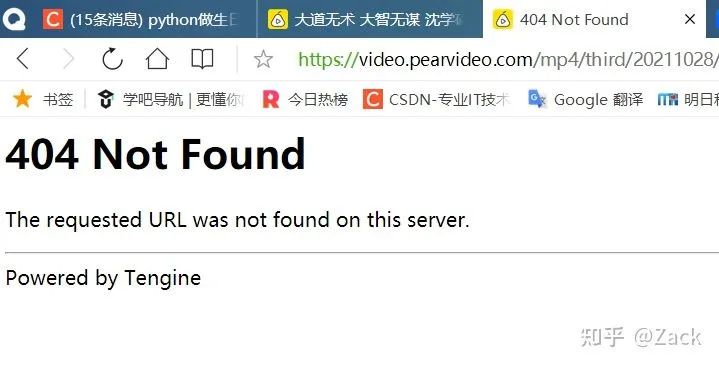
在图中,我们可以得到一个后缀为mp4的srcUrl链接,这看起来像是我们需要的视频资源url,但是如果直接使用这个链接发送请求,将会提示如下错误:
对比观察浏览器渲染之后的视频资源url和抓包获取的视频资源url:
浏览器渲染:
https://video.pearvideo.com/mp4/third/20211028/cont-1744727-11315812-110716-hd.mp4
抓包获取:
https://video.pearvideo.com/mp4/third/20211028/1637679343220-11315812-110716-hd.mp4
通过观察可得出,除了上文加黑标粗的部分不同外,其余部分均相同;而其中的1744727即为视频资源的data-cid属性值。
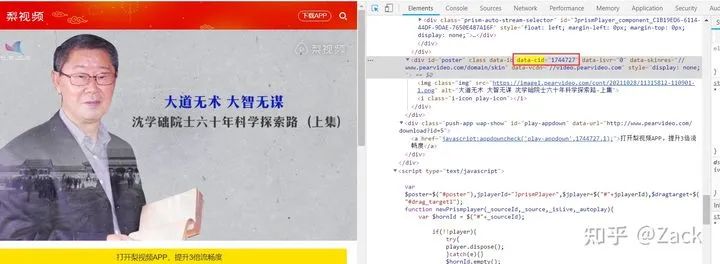 浏览器视频详情页中获取
浏览器视频详情页中获取
于是我们可以将抓包所获取到的假的视频资源url中的1637679343220替换为cont-1744727(即视频data-cid属性值),即可获取到真正的视频资源url, 从而下载视频资源!
经过漫长的分析之后,终于可以着手写代码啦!
4. 针对视频详情页url发送请求,获取响应
def parse_detail(self, detail_url, video_name):
detail_res = requests.get(detail_url, headers=self.headers)
detail_selector = Selector(detail_res.text)
init_cid = detail_selector.xpath("//div[@id='poster']/@data-cid").get() # 提取网页中data-cid的属性值(初始cid)
mrd = random.random() # 生成随机数,构建mrd
ajax_url = f"https://www.pearvideo.com/videoStatus.jsp?contId={init_cid}&mrd={mrd}"
global ajax_header # 将ajax_header设置为全局变量,以便在后续的函数中调用
ajax_header = {"Referer": f"https://www.pearvideo.com/video_{init_cid}"}
self.parse_ajax(ajax_url, init_cid, video_name)
5. 对视频详情页抓包,获取假的视频资源url
def parse_ajax(self, ajax_url, init_cid, video_name):
ajax_res = requests.get(ajax_url, headers=ajax_header)
fake_video_url = json.loads(ajax_res.text)["videoInfo"]["videos"]["srcUrl"] # 获取假的视频资源url
fake_cid = fake_video_url.split("/")[-1].split("-")[0] # 从假的视频资源url中抽取假的cid
real_cid = "cont-" + init_cid # 真的cid等于cont-加上初始的cid
# 将假的视频资源url中假的cid(fake_cid)替换为真的cid(real_cid)即可得到真正的视频资源url啦!!!
# 这段代码,你品,你细品...
real_video_url = fake_video_url.replace(fake_cid, real_cid)
self.download_video(video_name, real_video_url)
6. 对视频资源url发送请求,获取响应
有了视频名称和视频资源url,就可以下载视频啦!!!
def download_video(self, video_name, video_url):
video_res = requests.get(video_url, headers=ajax_header)
video_path = os.path.join(os.getcwd(), "单线程视频下载")
# 如果不存在则创建视频文件夹存放视频
if not os.path.exists(video_path):
os.mkdir(video_path)
with open(f"{video_path}/{video_name}.mp4", "wb") as video_file:
video_file.write(video_res.content)
print(f"{video_name}下载完毕")
最后,定义一个run()方法作为整个类的入口,调用最开始的start_request()函数即可!(套娃,一个函数套另一个函数)
def run(self):
self.start_request()
if __name__ == '__main__':
pear_video = PearVideo(3) # 先获取它三页的视频资源
pear_video.run()
在公众号回复955在梨视频文件夹即可获取完整代码。
使用线程池下载视频
线程池这部分的代码总体和单线程类似,只是将其中的视频名称和视频资源url单独抽取出来,作为全局变量。获取视频名称和视频资源url这部分仍为单线程,仅在下载视频资源这部分才用了线程池处理,可以同时针对多个视频资源url发送请求获取响应。
主要代码如下:
class PearVideo:
def __init__(self, page):
self.headers = {
"User-Agent": UserAgent().chrome,
}
self.page = page
self.base_url = "https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start="
self.video_list = [] # 新增了video_list为全局变量,用来保存视频名称和视频资源url
1.获取真正的视频资源url代码
def parse_ajax(self, ajax_url, init_cid, video_name):
ajax_res = requests.get(ajax_url, headers=ajax_header)
fake_video_url = json.loads(ajax_res.text)["videoInfo"]["videos"]["srcUrl"]
fake_cid = fake_video_url.split("/")[-1].split("-")[0]
real_cid = "cont-" + init_cid
real_video_url = fake_video_url.replace(fake_cid, real_cid)
# video_dict每次请求都会刷新,最终保存到video_list中
video_dict = {
"video_url": real_video_url,
"video_name": video_name
}
self.video_list.append(video_dict)
2. 多线程下载视频资源代码
def download_video(self, video_dict): # 此处传递的是一个字典而非video_list这个列表
video_res = requests.get(video_dict["video_url"], headers=ajax_header)
video_path = os.path.join(os.getcwd(), "线程池视频下载")
if not os.path.exists(video_path):
os.mkdir(video_path)
with open(f"{video_path}/{video_dict['video_name']}.mp4", "wb") as video_file:
video_file.write(video_res.content)
print(f"{video_dict['video_name']}下载完毕")
3. 启动多线程
if __name__ == '__main__':
pear_video = PearVideo(2)
pear_video.run()
pool = ThreadPoolExecutor(4) # 此处的4表示每次只开启4个线程下载视频资源
# 此处的map方法和Python自带的map(x,y)含义类似,即将可迭代对象y中的每一个元素执行函数x。
pool.map(pear_video.download_video, pear_video.video_list)
在公众号回复955在梨视频文件夹即可获取完整代码。
使用协程下载视频
使用协程下载视频资源中最为重要的三个库为asyncio(创建协程对象),aiohttp(发送异步请求),aiofiles(异步保存文件)。
重点:
1)在函数前加上async关键字,函数即被创建为一个协程对象;
2)协程对象中所有需要io耗时操作的部分均需使用await将任务挂起;
3)协程对象不能直接运行,需要创建一个事件循环(类似无限循环),然后再运行协程对象。
注意:
1)不能使用requests发送异步请求,需要使用aiohttp或httpx;
2)不能直接使用open()保存文件,需要使用aiofiles进行异步操作保存。
主要代码如下
# 将视频资源url和视频名称作为全局变量
self.video_urls = []
self.video_names = []
1.定义协程对象下载视频
# 下载视频信息
async def download_videos(self, session, video_url, video_name, video_path):
# 发送异步请求
async with session.get(video_url, headers=ajax_header) as res:
# 获取异步响应,前面必须加上await,表示挂起
content = await res.content.read()
# 异步保存视频资源到电脑本地
async with aiofiles.open(f"{video_path}/{video_name}.mp4", "wb") as file:
print(video_name + " 下载完毕...")
await file.write(content)
2. 创建main()运行协程对象
async def main(self):
video_path = os.path.join(os.getcwd(), "协程视频下载")
if not os.path.exists(video_path):
os.mkdir(video_path)
async with aiohttp.ClientSession() as session: # 创建session,保持会话
# 创建协程任务,每一个视频资源url即为一个协程任务
tasks = [
asyncio.create_task(self.download_videos(session, url, name, video_path))
for url, name in zip(self.video_urls, self.video_names)
]
# 等待所有的任务完成
done, pending = await asyncio.wait(tasks)
3. 调用整个类并运行协程对象
if __name__ == '__main__':
pear_video = PearVideo(3)
pear_video.run()
loop = asyncio.get_event_loop() # 创建事件循环
loop.run_until_complete(pear_video.main()) # 运行协程对象在公众号回复955在梨视频文件夹即可获取完整代码。
补充
在保存视频的时候,如果视频名称中含有"\", "/", "*", "?", "<", ">", "|"在内的非法字符,视频将无法保存,程序将报错,可用如下代码过滤视频名称:
def rename(self, name):
stop = ["\\", "/", "*", "?", "<", ">", "|"]
new_name = ""
for i in name:
if i not in stop:
new_name += i
return new_name
在使用多线程和协程下载视频资源这部分代码中都是使用单线程和线程池/协程结合,均是在获取到视频名称和视频资源url后再针对视频资源发送请求,获取响应,此部分代码仍有待优化,如使用生产者/消费者模式一边生产视频资源url,一边根据url下载视频;而协程部分也可将其它需要发送网络请求的部分修改为协程模式,从而提高下载速度。
总结
下载梨视频的视频资源难点在于破解真正的视频资源url, 先后需要对视频起始页(主页)发送请求,再对视频详情页发送请求,然后再对视频详情页抓包获取真正的视频资源url,最后再针对视频资源url发送请求,下载视频资源。其中线程池和协程的部分仍有待优化,以便更好地提高下载效率。
最后,感谢大家阅读此文呀!我们下次再见!!!拜拜~

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~