
即插即用模块 | CompConv卷积让模型不丢精度还可以提速(附论文下载)


为了降低CNN的计算成本,本文提出了一种新的卷积设计:CompConv。它利用分治法策略来简化特征图的转换。即插即用!可直接替换普通卷积,几乎不牺牲性能,极致压缩CNN结构!
作者单位:浙江大学, 香港中文大学
1简介
卷积神经网络(CNN)在各种计算机视觉任务中取得了显著的成功,但其也依赖于巨大的计算成本。为了解决这个问题,现有的方法要么压缩训练大规模模型,要么学习具有精心设计的网络结构的轻量级模型。在这项工作中,作者仔细研究了卷积算子以减少其计算负载。特别是,本文提出了一个紧凑的卷积模块,称为CompConv,以促进高效的特征学习。通过分治法的策略,CompConv能够节省大量的计算和参数来生成特定维度的特征图。
此外,CompConv将输入特征集成到输出中以有效地继承输入信息。更重要的是CompConv是一个即插即用模块,可以直接应用于CNN结构,无需进一步设计即可替换普通卷积层。大量的实验结果表明,CompConv可以充分压缩baseline CNN结构,同时几乎不牺牲性能。
本文主要贡献
提出了一种紧凑的卷积模块CompConv,它利用了分治法策略和精心设计的相同映射大大降低了CNN的计算代价。
通过研究递归计算对学习能力的影响,对所提出的CompConv进行了详尽的分析。进一步提出了一个切实可行的压缩率控制方案。
作为传统卷积层的方便替代作者将CompConv应用于各种benchmark。结果表明,CompConv可以大幅节省计算负载,但几乎不牺牲模型在分类和检测任务上的性能的情况下,CompConv方法优于现有的方法。
2本文方法
2.1 动机何在?
卷积可以被视为一种将特征从一个空间映射到另一个空间的操作。在某种程度上,这个过程类似于离散傅里叶变换(DFT),将信号序列从时域映射到频域。快速傅里叶变换(FFT)被广泛用于提高DFT的计算速度。所以本文通过分治策略来压缩普通的卷积模块:CompConv。
回顾一下FFT的公式。在时域对
个信号序列
进行DFT时,FFT提出将其分割成2个
个子序列,分别记为
和
,并对每个子序列进行DFT。这里
和
分别代表“偶”和“奇”。据此,由中间变换结果
和
得到频域的最终结果
:
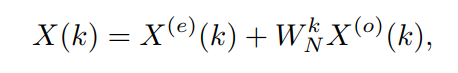
其中
是一个乘数。在此基础上,可将分解后的结果
和
进一步划分为更小的分组,形成递归计算的方式。
2.2 CompConv核心单元
在FFT的启发下,作者将分治策略引入到卷积模块中以提高其计算效率。通过类比,将由CNN生成的中间特征映射视为通道轴的序列。更具体地说,要开发带有C通道的特性映射
,可以选择开发2个特性映射
和
,每个特性映射都使用
个通道,然后将它们组合在一起:
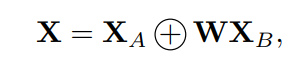
其中+表示沿通道轴的拼接操作,W是用于变换特征映射的可学习参数。
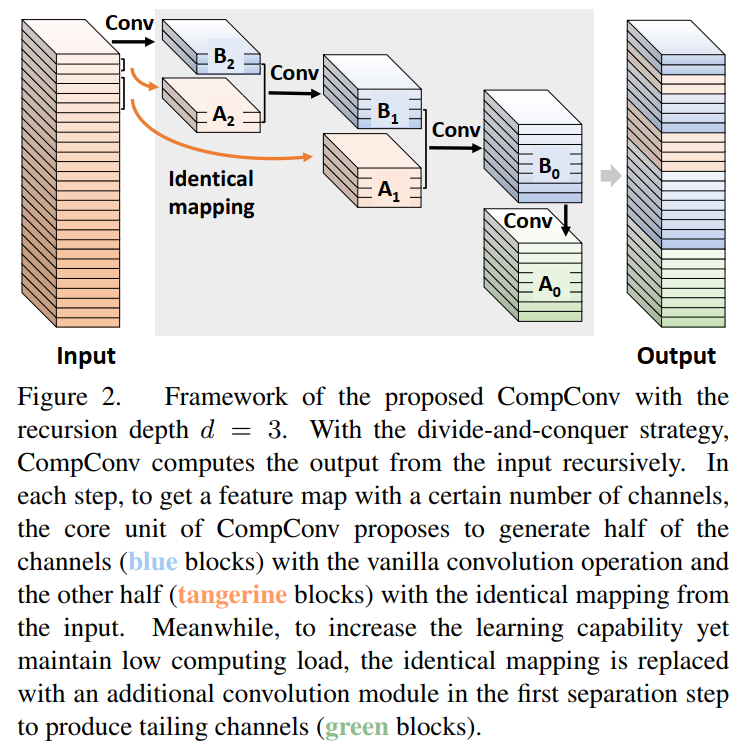
上式体现了CompConv的核心思想。具体来说,CompConv的核心单元由2部分实现,如图2所示。其中一个部分(即
)从输入通道的子集完全映射过来,它能够轻松地从输入中继承信息。另一部分(即
)通过卷积模块从输入特征转化而来。
2.3 递归计算
根据式(2)中的公式,将
进一步分解为2部分,可递归计算出CompConv:
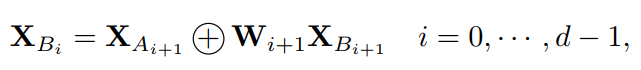
其中d为递归深度。
Tailing Channels
将第1个分离步骤
与其他步骤区别对待,如图2所示。具体来说,
不是直接从输入中来的,而是从
转化而来的。
这样做主要有2个原因:
一方面,在所有相同的部件
中,
的通道最多。如果直接将一些输入通道复制为
,那么输入特征映射和输出特征映射之间会有过多的冗余,严重限制了该模块的学习能力。
另一方面,除了从
转换之外,还有一些其他方法可以获得
,例如从整个输入特征映射或构建另一个递归。其中,从
开发
是计算成本最低的一种方法。同时,
的推导已经从输入特征中收集了足够的信息,因此学习能力也可以保证。
整合递归结果
为了更好地利用递归过程中的计算,最终的输出不仅通过分组两个最大的子特征得到
,并综合了所有中间结果,如图2所示。这样就可以充分利用所有的计算操作来产生最终的输出。此外,在这些特征映射的连接之后会添加一个shuffle block。
2.4 Adaptive Separation策略
CompConv采用分治策略进行高效的特征学习。因此,如何对通道进行递归分割是影响通道计算效率和学习能力的关键。这里分别用
和
表示输入通道数和输出通道数。
为图2中d=3时最小计算单元的通道数,如
。考虑到递归计算过程中通道数的指数增长,可以预期:
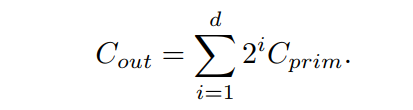
可以很容易得到以下结果:
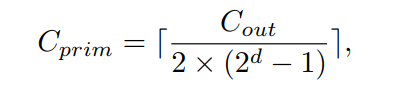
其中[]表示使
为整数的上限函数。如果所有单元的通道之和大于
,就简单地放入最后一些通道
以确保输出特征具有适当的尺寸。
递归计算深度的选择
由式(5)可知
高度依赖于递归深度d,这是CompConv模块中的一个超参数。较大的d对应较高的压缩率,其中d=0表示没有压缩。针对现代神经网络不同的结构和不同的模型尺度,作者提出了一种自适应的深度选择策略:
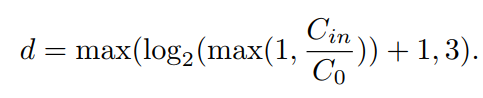
在这里,
是一个特定于模型的设计选择,由目标压缩率和模型大小决定([32;64;128;256;512;···])。从直觉上看,
越大,d越小,压缩越轻。从这个角度来看,
可以用来控制计算效率和学习能力之间的权衡。
值得注意的是,递归深度d与Eq.(6)中输入通道的数量
有关,这意味着自适应策略会在不同层动态调整计算深度。同时,为了保证最小单元有足够的学习能力,要给它分配了足够的通道。换句话说,
不能太小。从Eq.(5)可以看出,当d=3时,
只占输出通道的约8%。因此,作者将深度d限定为最大值3。
推荐配置
对于最受欢迎的CNN网络,如VGG和ResNet,建议设置
=128。作者将此配置表示为CompConv128。
2.5 复杂度分析
假设输入和输出特征图的分辨率都是H×W,那么普通卷积和CompConv的计算复杂度分别是:
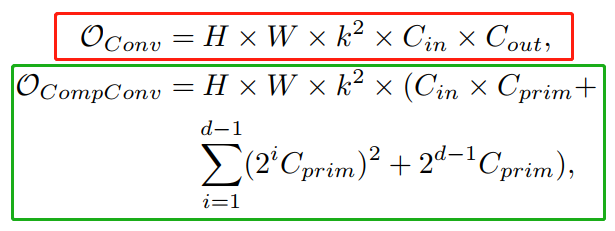
其中k为卷积核的大小。
在
和d=3的配置下,与传统卷积相比,CompConv只需要约20%的计算资源就可以开发具有相同通道数的输出特征。
3实验
3.1 ImageNet分类
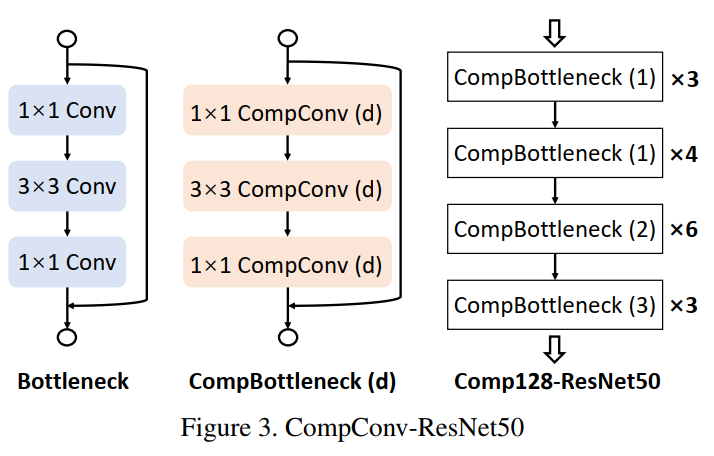
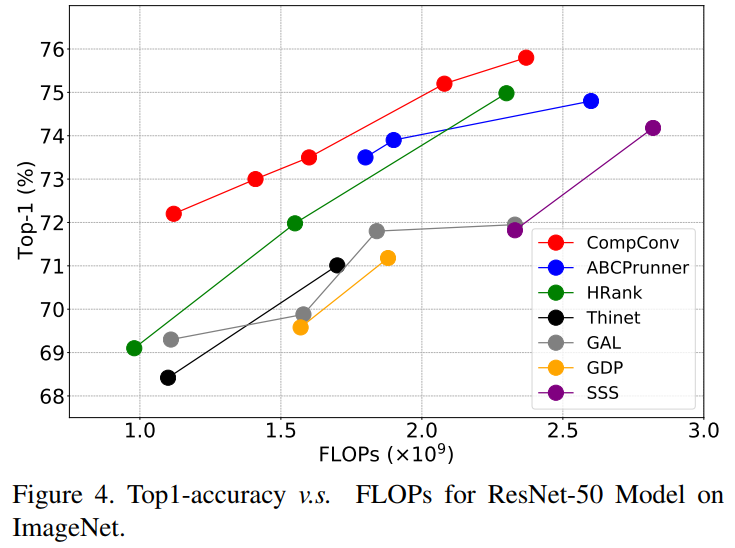
模型结构为使用CompConv替换普通CNN的ResNet50模型,实验结果如下:
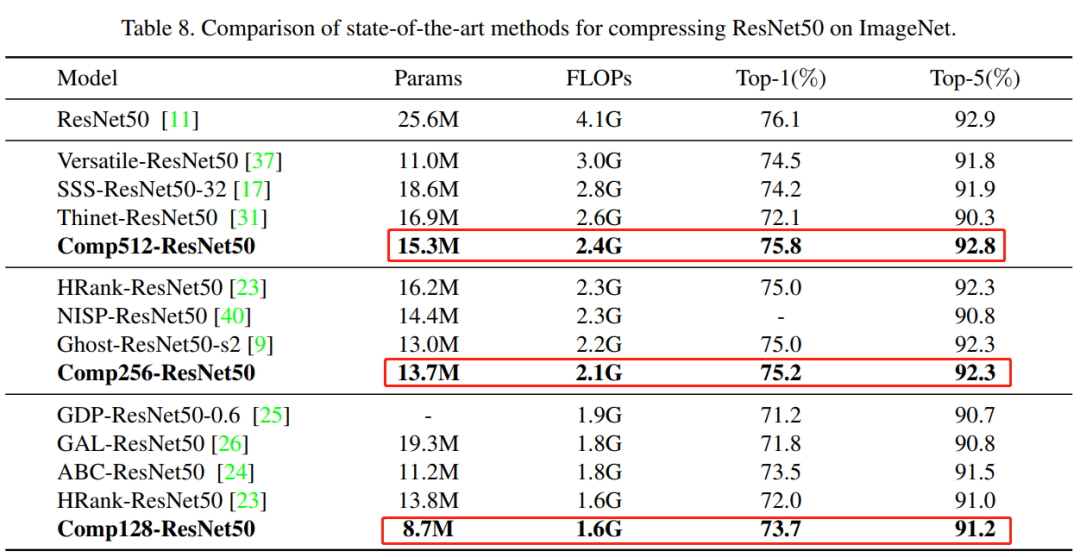
可以看出,性价比很高的!!!
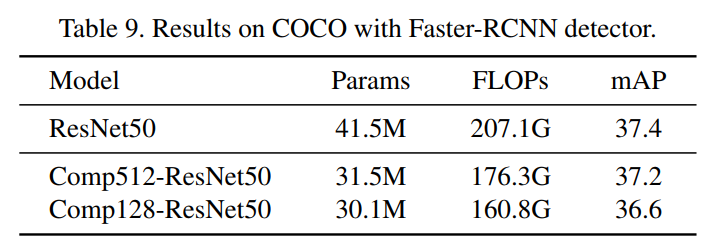
3.2 COCO目标检测
4参考
[1].CompConv: A Compact Convolution Module for Efficient Feature Learning
5推荐阅读

详细解读Google新作 | 教你How to train自己的Transfomer模型?

CVPR2021 GAN详细解读 | AdaConv自适应卷积让你的GAN比AdaIN更看重细节(附论文下载)

全新激活函数 | 详细解读:HP-x激活函数(附论文下载)
本文论文原文获取方式,扫描下方二维码
回复【CompConv】即可获取论文
长按扫描下方二维码添加小助手并加入交流群,群里博士大佬云集,每日讨论话题有目标检测、语义分割、超分辨率、模型部署、数学基础知识、算法面试题分享的等等内容,当然也少不了搬砖人的扯犊子
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
