
(附论文&代码)ContNet:为什么不同时使用卷积和变压器


摘要
比起与最近提出的基于变压器模型(例如,维特,DeiT)敏感hyper-parameters和极其依赖一堆数据扩增在中型从头训练数据集(例如,ImageNet1k),可以优化ConTNet回旋网像正常(如ResNet)和保持一个优秀的鲁棒性。值得指出的是,给定相同的强数据增强,ConTNet的性能改进比ResNet更显著。作者展示了它在图像分类和下游任务上的优越性和有效性。例如,作者的ConTNet在ImageNet上达到81:8%的top-1精度,与DeiT-B相同,但计算复杂度低于40%。在COCO2017数据集上,ConTNet-M作为Faster-RCNN和Mask-RCNN的骨干,表现也优于ResNet50(分别领先2:6%和3:2%)。作者希望ConTNet能够成为CV任务的骨干,并为模型设计带来新的思路。
代码链接:https://github.com/yan-hao-tian/ConTNet

简而言之,这项工作的贡献有三方面。
1)据作者所知,作者提出的ConTNet是第一次探索建立一个神经网络与标准变压器编码器(STE)和空间卷积。
2)与最近流行的视觉转换器相比,ConTNet更容易优化。除了鲁棒性,ConTNet在图像识别方面表现出色。
3)实验结果表明,该方法具有良好的迁移学习效果。这些结果表明,ConTNet提供了一种新的基于转换变压器的模式来扩大模型的接收场。

框架结构
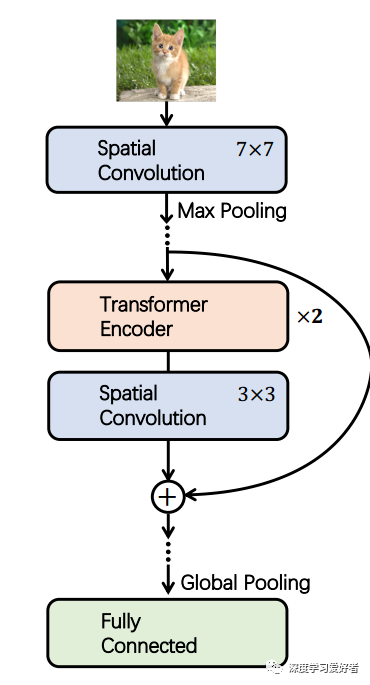
建议的ConTNet框架的说明
ConTNet包含多个contt块,由两个变压器编码器层和一个卷积层组成。
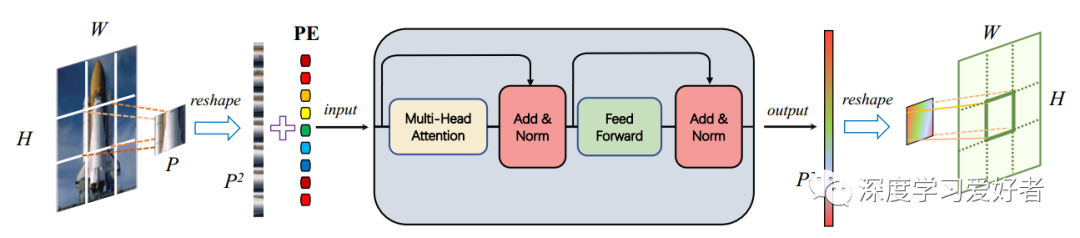
ConTNet中的一个补丁式标准变压器编码器(STE)
PE表示位置编码。H和W分别为输入和输出图像的高度和宽度。P为patch的大小。p2为STE输入输出序列的长度。
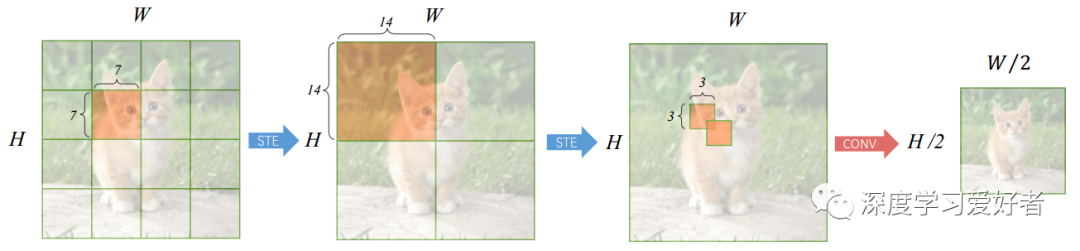
信息流在一个ConT块
对于被橙色阴影覆盖的区域,蓝色箭头表示每个空间位置的输出值是从整个覆盖区域通过分段STE计算出来的。红色箭头是一个conv层,核大小为3,步幅为2,只计算整个覆盖区域中心位置的输出值。
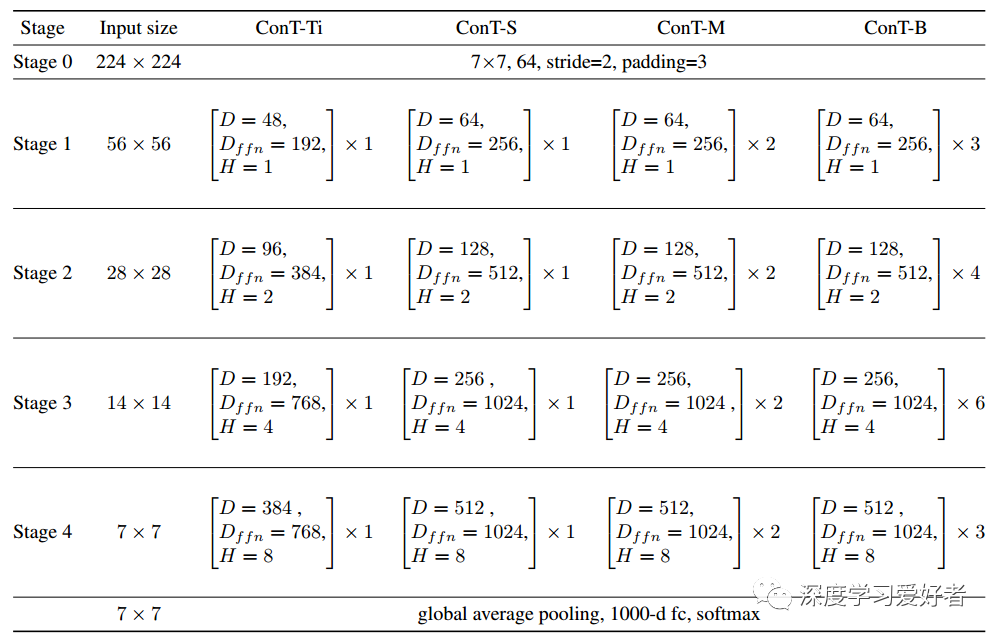
ConTNet系列详细设置
在括号内,作者列出了每个ConTBlock的超参数。D为MHSA的嵌入维数,Dffn为FFN的维数,H为MHSA的头数。托架外,显示了舞台上堆叠块的数量。在每一阶段,最后一个conv层进行降采样并增加维数。

实验结果

城市景观验证集上PSPNet分割结果的可视化比较
每一列是来自验证集的一组样本,上面两行是原始图像及其相应的ground truth。下面两行分别表示具有ResNet50骨干和contm骨干的PSPNet的结果。黄色的边界框标记了分割结果呈现显著差异的区域。
 结论
结论
城市景观验证集上PSPNet分割结果的可视化比较。每一列是来自验证集的一组样本,上面两行是原始图像及其相应的ground truth。下面两行分别表示具有ResNet50骨干和contm骨干的PSPNet的结果。黄色的边界框标记了分割结果呈现显著差异的区域。
ConTNet通过标准变压器编码器(STE)和空间卷积交替叠加,将变压器和卷积结合起来。作者引入一个权重共享的补丁方式STE来建模大型内核。一系列实验表明,ConTNet的性能优于ResNet,在较低的计算复杂度下达到了与流行视觉转换器相当的精度。作者验证了利用ConTNet骨干实现下游任务的有效性主要来源于聚合更多的上下文信息。此外,作者还演示了ConTNet与ConNets(例如ResNet)一样健壮。换句话说,ConTNet的性能不依赖于强大的数据增强和花哨的训练技巧,也不敏感的超参数。最后,在ConTNet中作者使用了普通的卷积和变压器,如果用最近改进的卷积和变压器来替代,将会有更好的性能。希望作者的工作能为模型设计带来一些新的思路。
论文链接:https://arxiv.org/pdf/2104.13497.pdf
双一流高校研究生团队创建 ↓
专注于目标检测原创并分享相关知识 ☞
整理不易,点赞三连!