
原创 | AI顶会论文很多附带源代码?不少是假开源!

作者:林嘉亮 审校:陈之炎 本文约3500字,建议阅读10分钟 相当多的作者没有向用户提供足够详细的文档,导致了一些重要信息的缺失。
看到一篇绝佳的AI论文,非常期待作者能提供源代码,全文搜索HTTP,可惜出来的都不是源代码的链接。好不容易碰到一篇附带源代码的论文,点进去却是大大的404。终于发现某个不是404的源代码仓库,结果只是放上了几句说明,写着“代码coming soon”,然后一等就是一万年......
所以,AI顶会论文中附带源代码的占比究竟有多少?这些代码中有多少已经失效了?这些代码的特点如何?作者是否为读者提供了足够详细的文档来运行这些源代码?
来自厦门大学自然语言处理实验室的团队发文回答了这几个问题,论文信息如图1所示。

图1 本文相关学术论文信息
论文作者设计了一个基于SciBERT的分类方法,分析AI论文内URL所在句子的语义信息,可以准确判断URL是否为所属论文自身附带的源代码仓库链接。该方法的accuracy为0.939,F1-score达0.909。
用这个方法,分析2010至2019年的十个AI顶会:AAAI、ACL、CVPR、ECCV、EMNLP、ICCV、ICLR、ICML、IJCAI和NeurIPS。实验结果表明:共有20.5%的论文被认定是附带源代码的论文,其中只有大约一半的论文被Papers With Code索引到并提取了源代码的链接,证明了该方法的先进性。
作者检查了所有链接的有效性,发现有8.1%的链接已经失效。一些URL因为网站的重构而无法访问。有些则被删除或变成了私有仓库,导致了GitHub中出现404错误。有些是可以正常访问的URL,但并没有提供源代码。
源代码是和被接收的论文一起发布的,论文中附带的源代码也是论文可以被接收的因素之一,因此源代码是论文不可缺少的一部分。删除线上的源代码,实质上等于破坏了论文的完整性。这样的行为应该被禁止。作者应该尽力保持论文中包含源代码仓库URL的可访问性。对于网站重建的情况,应在原始URL上添加重定向链接。
作者同时分析了这些源代码的特点,直接看论文的图表。
AI顶会附带源代码的百分比如图2所示。
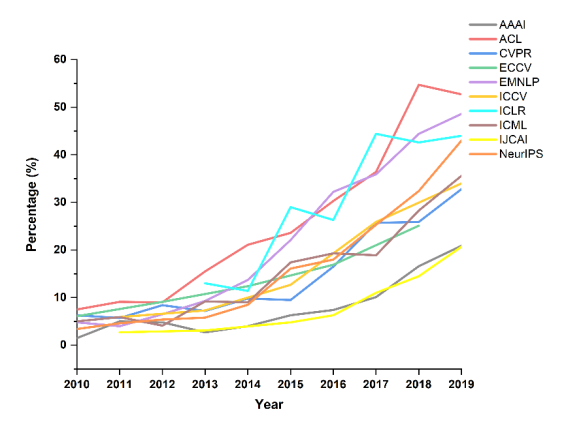
图2 AI顶会附带源代码的百分比
从图2可以看出,从2010年到2019年,所有10个AI顶会论文附带源代码的比例都在增加。前三名的会议是ICLR、ACL和EMNLP。自2018年以来,ACL上附带源代码论文的比例已经超过50%。2019年的EMNLP、ICLR和NeurIPS也超过了40%。NLP类顶会论文附带源代码的比例较高,而CV类顶会论文附带源代码的比例相对较低。AAAI和IJCAI论文附带源代码的比例在排名中处于末两位。
AI顶会论文总数、附带源代码论文数和附带源代码论文比例如图3所示。
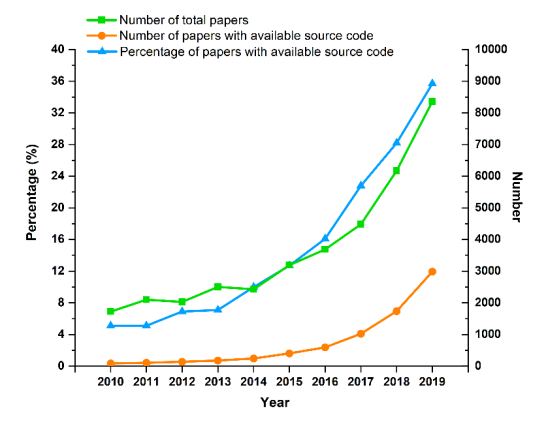
从图3可以看出,过去10年中,论文总数、附带源代码论文数和附带源代码论文比例都在增加。在2019年,论文总数差不多达到8,500篇,附带源代码论文数接近3,000篇。可以看出,附带源代码论文比例在短短10年内从约5%增长到了约35%。在AI顶会上,随论文发布源代码的势头在不断增强。
AI顶会附带源代码的发布平台分布如图4所示。
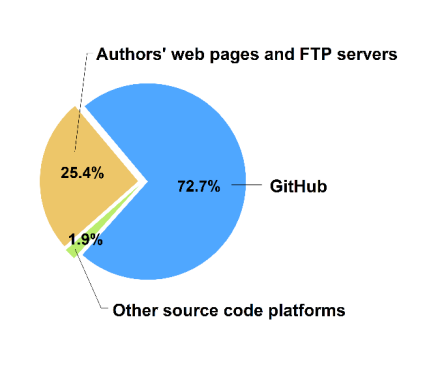
从图4可以看出,大多数作者选择了GitHub作为发布他们源代码的平台。只有少部分作者把他们的代码发布到了其他代码平台。此外,将近三分之一的作者把代码发布在了自己的网页和FTP服务器上。需要特别说明的是,一些这样的网页包含有项目介绍,各类资源和GitHub源代码仓库的链接,这被视为是属于发布在自己网页这类。
GitHub已经成为了AI社区事实上的源代码平台。它允许用户通过一个通用的API访问其源代码仓库的元数据。因此,我们在研究下文的编程语言、star数和fork数时,将GitHub上的源代码仓库作为代表性样本(数据收集时间为2022年1月25日)。
AI顶会附带GitHub源代码的编程语言分布如表1所示。
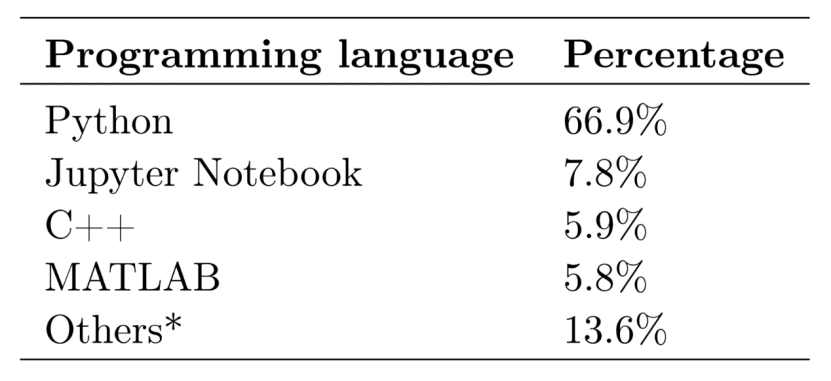
表1 AI顶会附带GitHub源代码的编程语言分布
从表1可以看出,在所有这些源代码仓库所使用的编程语言中,Python是最受欢迎的。Python的书写风格高度简洁,编码高效快捷,也有大量机器学习和分析的包供用户使用。随着深度学习的重要性日益增加,在计算时启用GPU至为关键。在这方面,Python得到了众多框架的支持,例如TensorFlow和PyTorch加速基于GPU的深度学习。以上这些众多优点,使Python成为了AI编程的首选。Jupyter Notebook为第二流行的编程语言(GitHub API提供的元数据将其视为一种编程语言)。事实上,大多数Jupyter Notebook中实际运行的是Python代码。它们之间的区别在于,Jupyter Notebook有更多的交互性。C++排名第三,这种传统语言在速度上有其独到的优势,它经常被用于对速度敏感的项目中。排名第四的是MATLAB,这是一种用于模拟和测试研究思路的著名脚本语言。
AI顶会附带GitHub源代码的star中位数与fork中位数如表2所示。

表2 AI顶会附带GitHub源代码的star中位数与fork中位数
AI顶会论文中star数排名前十的GitHub源代码仓库如表3 所示。

表3 AI顶会论文中star数排名前十的GitHub源代码仓库

图5 AI顶会附带源代码论文中的摘要核心词词云
从图5可以看出,“method”, “dataset”, “approach”和“algorithm”是附带源代码的AI顶会论文摘要中最常见的词。值得注意的是,“method”和“dataset”占据了同样突出的比例。这表明,数据集在AI研究中起着至关重要的作用。大多数AI研究人员将他们的源代码与相关数据集一起发布,这种行为对社区有很大贡献。
为了评估这些源代码的提供者是否有提供足够详细的文档让读者运行代码,作者开发了专门的标注工具,组织团队按八大类别标注了5千多个GitHub源代码仓库的README文件。构造了当前最大的源代码仓库README数据集XMU NLP Lab README Dataset。基于这个数据集,分析了文档中的各个描述项的比例。
XMU NLP Lab README Dataset中各类别占比如表4 所示。
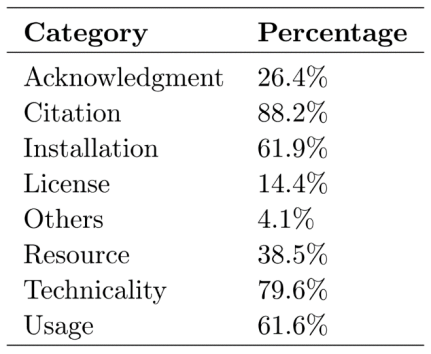
表4 XMU NLP Lab README Dataset中各类别占比
从GitHub平台上的README文件来看,相当多的作者没有向用户提供足够详细的文档,导致了一些重要信息的缺失,例如安装说明和使用教程,而这些内容对于运行源代码是不可或缺的。因此,笔者建议在源代码仓库中提供这些信息应成为标准做法,这可以被认为是评估可复现性的重要标准。
最后,该文的作者呼吁AI论文的作者要确保附带在论文中源代码仓库链接的有效性和真实性,同时提供详细的文档以方便读者可以真正把源代码运行起来,并复现论文中的结果。
论文已经发表在 International Journal of Software Engineering and Knowledge Engineering Vol. 32, No. 07, pp. 947-970 (2022)
arXiv上有作者提交的版本 https://arxiv.org/abs/2209.14155
文中提及的附带源代码论文和他们的源代码链接、README标注工具和XMU NLP Lab README Dataset均在论文中提供了下载地址。
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
未经许可的转载以及改编者,我们将依法追究其法律责任。