
HBase 优化 | 移动云使用 JuiceFS 支持 Apache HBase 增效降本的探索

📖 作者简介:
陈海峰,移动云数据库 Apache HBase 开发人员,对 Apache HBase、RBF、Apache Spark 有浓厚兴趣。
本文主要介绍了移动云使用 JuiceFS 接入对象存储优化 Apache HBase 的方案选型思考、验证,供大家参考。
背景
Apache HBase(下文简称 HBase) 是 Apache Hadoop 生态体系中的大规模、可扩展、分布式的数据存储服务。同时它还是 NoSQL 数据库。它的设计初衷是为包含了数百万列的数十亿行记录提供随机的、强一致性的实时查询。默认情况下,HBase 的数据会保存在 HDFS 上,HBase 为 HDFS 做了很多优化来保证稳定性与性能。但是维护 HDFS 本身一点也不轻松,要不断进行监控、运维、调优、扩容、灾难恢复等一系列事情,而且在公有云上搭建 HDFS 的费用也是相当高的。为了节省费用、降低维护成本,一些用户使用 S3(或其他对象存储)存储 HBase 的数据。使用 S3 省去了监控运维的麻烦,同时还实现了存储计算分离,让 HBase 的扩容缩容都变得更加容易。
然而,HBase 数据接入对象存储却不是一件容易的事儿。对象存储一方面因为自身特性,功能和性能有限,一旦数据被写入对象存储后,数据对象即不可改变,另一方面使用文件系统语义访问块存储有天然局限性。在使用 Hadoop 原生的 AWS 客户端来访问对象存储时,目录重命名操作会遍历整个目录下文件进行拷贝和删除,性能非常低下。另外重命名操作也会导致原子性问题,即原本的重命名操作分解为拷贝和删除两个操作,在极端情况下易产生用户数据视图不一致情况。类似的还有查询目录所有文件的总大小,原理是通过遍历迭代依次获取某个目录的所有文件信息。如果目录下的子目录和文件数量庞大的话,查询目录所有文件总大小复杂度更大,性能更差。
方案选型
经过大量方案调研和社区问题跟踪,目前移动云 HBase 数据接入对象存储有三种方案。
第一种是 HBase 使用 Hadoop 原生 AWS 客户端来访问对象存储,即 S3AFileSystem。HBase 内核代码只需要稍加改动即可使用 S3AFileSystem。这种 HBase 直接对接对象存储的方案一个需要解决的痛点问题,即目录的 rename。HBase 在 Hlog 文件管理、MemStore Flush、表创建、region compaction 和 region split 时都会涉及目录的 rename。社区对 StoreFIle 进行了优化,解决了一部分的 rename 性能问题。完全解决目录操作性能问题需要对 HBase 内核源码进行大刀阔斧地变动。
第二个方案是引入 Alluxio 作为缓存加速,不仅大大提升读写性能,而且引入文件元数据管理,彻底解决了目录操作性能低下问题。看似圆满的结局,背后却有很多限制条件。当 Alluxio 配置仅仅使用内存时,对目录操作耗时才是 ms 级别。如果配置 Alluxio 的 UFS,Alluxio 中的元数据操作有两个步骤:第一步是修改 Alluxio master 的状态,第二步是向 UFS 发送请求。可以看到,元数据操作仍然不是原子的,当操作正在执行或发生任何故障时,其状态是不可预测的。Alluxio 依赖 UFS 来实现元数据操作,比如重命名文件操作会变成复制和删除操作。HBase 中数据必定是需要落盘的,Alluxio 解决不了目录操作性能问题。
第三种方案是在 HBase 与对象存储之间引入 JuiceFS 共享文件系统。使用 JuiceFS 存储数据,数据本身会被持久化在对象存储(例如,移动云 EOS),相对应的元数据可以按需持久化在 Redis、MySQL 等多种数据库中。此方案中对目录操作完成是在 Metadata Engine 中完成,与对象存储无交互,操作耗时在 ms 级别,可以解决 HBase 数据接入对象存储的痛点问题。但是由于 JuiceFS 内核采用 Go 语言编写,对后期性能调优和日常维护带来一定挑战。
权衡上述三个方案利弊,最终采用 JuiceFS 作为移动云 HBase 支持对象存储的解决方案。下面着重讨论 JuiceFS 在移动云 HBase 支持对象存储中的实践以及性能调优。
方案介绍
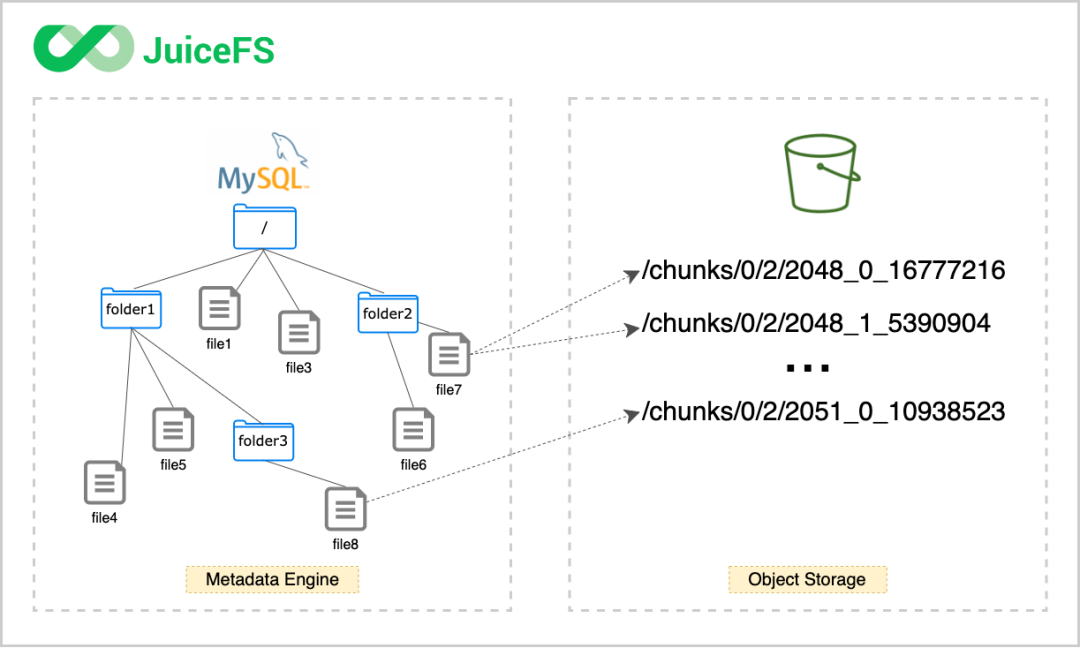
首先介绍下 JuiceFS 的架构。JuiceFS 由两个主要部分组成:JuiceFS 元数据(Metadata)服务和对象存储。JuiceFS Java SDK 完全兼容 HDFS API,同时也提供基于 FUSE 的客户端挂载,完全兼容 POSIX。作为文件系统,JuiceFS 会分别处理数据及其对应的元数据,数据会被存储在对象存储中,元数据会被存储在元数据引擎中。在数据存储方面,JuiceFS 支持几乎所有的公有云对象存储,同时也支持 OpenStack Swift、Ceph、MinIO 等支持私有化部署的开源对象存储。在元数据存储方面,JuiceFS 采用多引擎设计,目前已支持 Redis、TiKV、MySQL/MariaDB、PostgreSQL、SQLite 等作为元数据服务引擎。

任何存入 JuiceFS 的文件都会被拆分成固定大小的 "Chunk",默认的容量上限是 64 MiB。每个 Chunk 由一个或多个 "Slice" 组成,Slice 的长度不固定,取决于文件写入的方式。每个 Slice 又会被进一步拆分成固定大小的 "Block",默认为 4 MiB。最后,这些 Block 会被存储到对象存储。与此同时,JuiceFS 会将每个文件以及它的 Chunks、Slices、Blocks 等元数据信息存储在元数据引擎中。

使用 JuiceFS,文件最终会被拆分成 Chunks、Slices 和 Blocks 存储在对象存储。因此,对象存储平台中找不到存入 JuiceFS 的源文件,存储桶中只有一个 chunks 目录和一堆数字编号的目录和文件。
HBase 组件使用 JuiceFS 需要以下配置。首先将编译好的客户端 SDK 置于 HBase classpath 内。其次将 JuiceFS 相关配置写入配置文件 core-site.xml,如下表所示。最后使用 JuiceFS 客户端格式化文件系统。
| 配置项 | 默认值 | 描述 |
| fs.jfs.impl | io.juicefs.JuiceFileSystem | 指定要使用的存储实现,默认使用 jfs:// |
| fs.AbstractFileSystem.jfs.impl | io.juicefs.JuiceFS | |
| juicefs.meta | 指定预先创建好的 JuiceFS 文件系统的元数据引擎地址。 |
在元数据存储方面,使用 MySQL 作为元数据存储。格式化文件系统命令如下。可见,格式化文件系统需要提供以下信息:
•
--storage:设置存储类型,比如移动云 EOS;•
--bucket:设置对象存储的 Endpoint 地址;•
--access-key:设置对象存储 API 访问密钥 Access Key ID;•
--secret-key:设置对象存储 API 访问密钥 Access Key Secret。
juicefs format --storage eos \--bucket https://myjfs.eos-wuxi-1.cmecloud.cn \--access-key ABCDEFGHIJKLMNopqXYZ \--secret-key ZYXwvutsrqpoNMLkJiHgfeDCBA \mysql://username:password@(ip:port)/database NAM
方案验证与优化
介绍完 JuiceFS 使用方法后,开始进行测试工作。测试环境中选用了一台 48 核、187G 内存的服务器。在 HBase 集群中,分别有一个 HMaster、一个 RegionServer 和三个 zookeeper。在 Metadata engine 选用主从复制的三节点 MySQL。对象存储则使用移动云对象存储 EOS,网络策略走公网。JuiceFS 配置 chunk 大小为 64M,物理存储块大小为 4M,无 cache,MEM 使用 300M。我们搭建了两套 HBase 集群,一套是 HBase 直接落盘到移动云对象存储上,另一套是在 HBase 和移动云对象存储之间引入 JuiceFS。顺序写和随机读是 HBase 集群两个关键性能指标,使用 PE 测试工具测试这两个性能指标。测试读写性能如下表所示。
| 集群环境 HBase-JuiceFS-EOS (row/s) | 集群环境 HBase-EOS (row/s) | |
| 顺序写 | 79465 | 33343 |
| 随机读 | 6698 | 6476 |
根据测试结果,采用 JuiceFS 方案,集群顺序写性能提升非常明显,随机读性能却没有提升。究其原因,写请求写入 Client 内存缓冲区即可返回,因此通常来说 JuiceFS 的 Write 时延非常低(几十微秒级别)。JuiceFS 在处理读请求时,一般会按照 4M Block 对齐的方式去对象存储读取,实现一定的预读功能,同时,读取到的数据会写入本地 Cache 目录,以备后用。在顺序读时,这些提前获取的数据都会被后续的请求访问到,Cache 命中率非常高,因此也能充分发挥出对象存储的读取性能。但是在随机读取时,JuiceFS 的预先缓存效率不高,反而会因为读放大和本地 Cache 的频繁写入与驱逐使得系统资源的实际利用率降低。
为了提升随机读性能,两个方向可以考虑。一个是尽可能提升缓存的整体容量,以期达到能几乎完全缓存所需数据的效果,在海量数据的使用场景下,这个优化方向不太可行。
另一个方向是深耕 JuiceFS 内核,优化读数据逻辑。目前我们所做的优化包括:1)关闭预读机制和缓存功能,简化读数据逻辑;2)尽可能避免缓存整个块数据,更多地使用 Range HTTP 请求数据;3)设置较小的 block 大小;4)尽可能提高对象存储的读取性能。经研发环境测试,经优化后随机读性能提升大约 70%。
结合前期测试工作,移动云 HBase 在使用 JuiceFS 结合对象存储的方案后,在获得与数据存储在 HDFS 差不多读写性能基础上,用户花费却只有数据存储在 HDFS 的一半以下,由此可以看出移动云 HBase 支持对象存储是鱼与熊掌兼得的一次研发实践。
开源社区贡献指南
JuiceFS 已于 2021 年 1 月开源,开源软件的发展离不开每一个人的支持,一篇文章、一页文档、一个想法、一个建议、报告或修复一个 Bug,这些贡献不论大小都是推动开源项目不断发展的动力,欢迎来 JuiceFS 的社区参与以上贡献。(https://github.com/juicedata/juicefs)
👇 扫码加群 👇
👇 关注「Juicedata」,看更多技术干货 👇