
ATSS:自动选择样本,消除Anchor based和Anchor free物体检测方法之间的差别
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

导读
本文认为,anchor based和anchor free物体检测方法的本质区别在于如何选择样本,文章通过实验验证了这个想法,并提出了一种自动选取样本的方法,在不引入任何计算量的情况下,提升了效果,并且可以认为是没有任何超参数。

论文:https://arxiv.org/abs/1912.02424
代码:https://github.com/sfzhang15/ATSS
后台回复“ATSS”获取打包好的论文和代码
摘要
文章指出,基于anchor的方法和anchor free的方法的本质区别在于如何定义正负样本。所以,文章提出了一个自适应的样本选择的方法来根据物体的统计特性自适应的选择正负样本,提升了性能,同时显著缩小了anchor based和anchor free方法之间的gap。
anchor free的方法一般有两种:一种是定位可以保卫物体的预定义的特征点,称为keypoint-based方法,另一种是使用物体的中心点或者物体的区域来定义正样本,然后预测该正样本点到4个边的距离,这种称为center-based方法。这两种方法中,keypoint-based方法是follow了特征点检测的方法,和anchor based方法差别较大,而center-based方法则把点看做是样本,这和anchor based方法中把anchor看做是样本是非常相似的。
以RetinaNet和FCOS为例,比较这两种方法的区别:(1)每个空间位置的样本数量不同,RetinaNet的每个位置有好几个anchor,而FCOS每个位置只有一个anchor点。(2)正负样本的定义不同,RetinaNet使用IOU来定义正负样本,FCOS使用空间和尺度约束来选择样本。(3)回归的初始状态不一样,RetinaNet从预设的anchor为起点进行回归,而FCOS的回归起点是该位置的anchor点。从FCOS的论文中可以看到,FCOS的效果要比RetinaNet好的多。所以需要研究一下,这三个不同点,哪个才是决定性的。
本文的贡献点:
指出了anchor based和anchor free方法分本质区别在于如何选择正负样本。 提出了基于物体统计特性自适应的选择正负样本的方法。 指出了在单个空间位置上叠加多个anchor来做物体检测是没什么用的。 没有增加任何的开销,在MS COCO上达到了SOTA。
2.1 去掉不相干的东西
我们使用MS COCO来做实验,我们把只使用了一个正方形anchor的RetinaNet记做RetinaNet(#A=1),这其实和anchor free的FCOS非常接近了。不过,在FCOS的论中,FCOS的效果要比RetinaNet好很多,一个是37.1%,一个是32.5%。FCOS中还用了一些进一步的优化,包括把centerness的预测移动到回归分支中,使用GIoU loss,通过对于的stride对target做归一化,这些方法将FCOS从37.1%提升到37.8%。在FCOS使用的一些优化方法,其实也可以用在RetinaNet中,比如在检测头上加GroupNorm,使用GIoU损失函数,限制groundtruth box的正样本,引入centerness分支,在特征金字塔中引入可训练的尺度参数s。不过,这些都不是两者的根本的区别。我们把这些优化方法一个一个的加入到了RetinaNet(#A=1)中,如表1,performance提升到了37.0%。还是有0.8%的gap。现在,去掉了这些不相干的差别,我们可以来探索一下两者的根本差别在哪里。
2.1 根本的差别
现在,RetinaNet(#A=1)和FCOS只有两个差别了,一个和分类子任务相关,也就是定义正负样本的方法,另一个和回归子任务相关,也就是回归的起点是anchor box还是anchor点。
分类
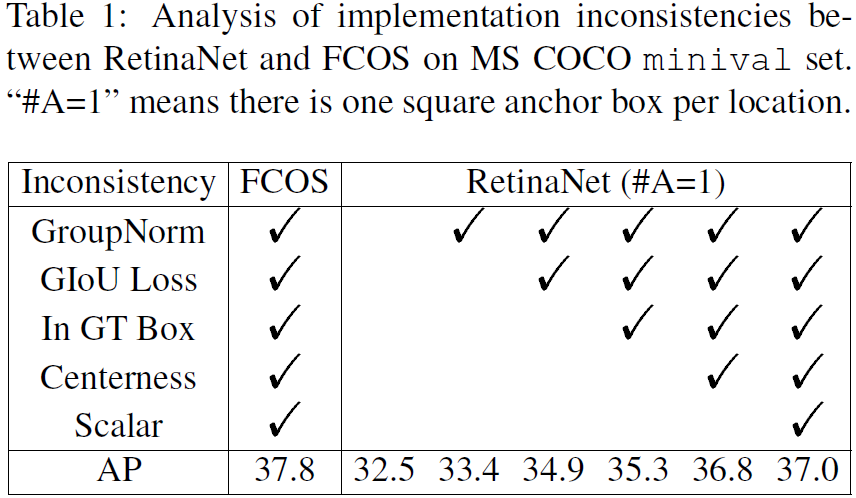
如图1(a),RetinaNet使用IOU将来自不同level的anchor box划分为正负样本,对于每个物体,在IOU>θp的所有anchor box中,选一个最大的作为正样本,所有IOU<θn的都认为是负样本,其他的都忽略掉。如图1(b),FCOS使用空间和尺度约束将anchor点分配到不同的level上,首先将所有在groundtruth box内的anchor点作为候选点,然后基于预先对每个level设置的尺度范围来选择最终的正样本,没有选中的点就是负样本。
这两种不同的方案最终的到了不同的正负样本。见表2,如果在RetinaNet(#A=1)使用空间和尺度约束的方式来代替IOU来选择正负样本,RetinaNet(#A=1)的performance可以提升到37.8%。而对于FCOS,如果使用IOU的策略在选择正负样本,那么performance会降到36.9%。这表明了正负样本的选择策略才是这两种方法的根本区别。

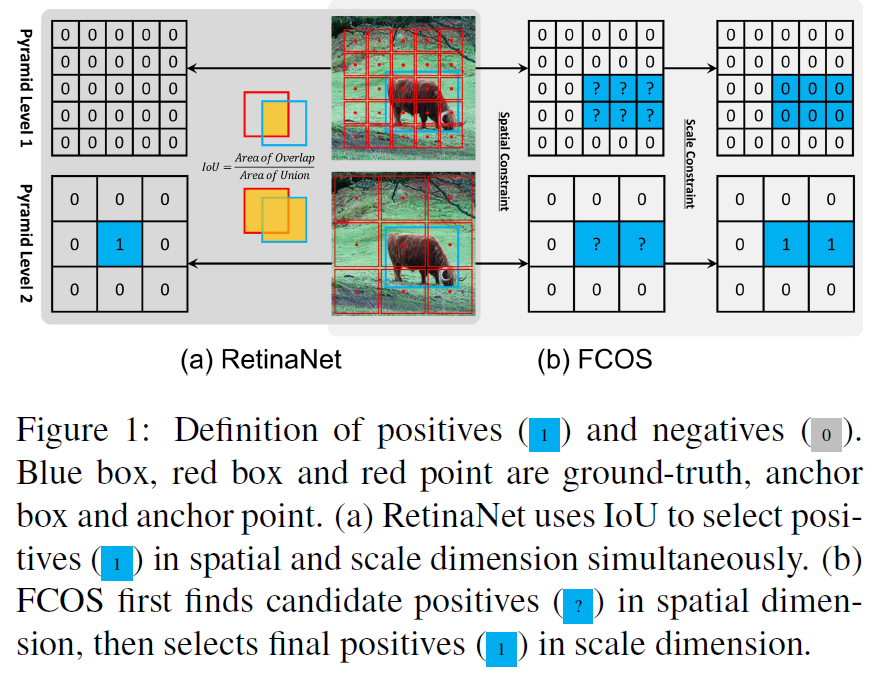
回归
在正负样本确定了之后,需要对正样本进行物体位置的回归。如果图2,RetinaNet回归的是anchor box和groundtruth的4个offset,而FCOS回归的是anchor点到4条边的距离。这表明RetinaNet的回归起点是一个框,而FCOS的回归起点是一个点。而表2中可以看到,当RetinaNet和FCOS使用相同的正负样本选择策略的时候,两者并没有明显的差别,这表明回归的起点并不是两个方法的本质区别。
结论 从上面的实验可以得出结论,一阶段的anchor based物体检测方法和center-based anchor free的物体检测方法的本质区别在于正负样本的选取策略上。
3. 自适应样本选择
3.1 描述
之前的样本选择策略都是有一些敏感的超参数的,比如anchor based方法中有IOU的阈值,anchor free的方法中有尺度范围。我们提出的自适应的方法,通过物体的统计特性,自动的区分正负样本,不需要任何超参数。
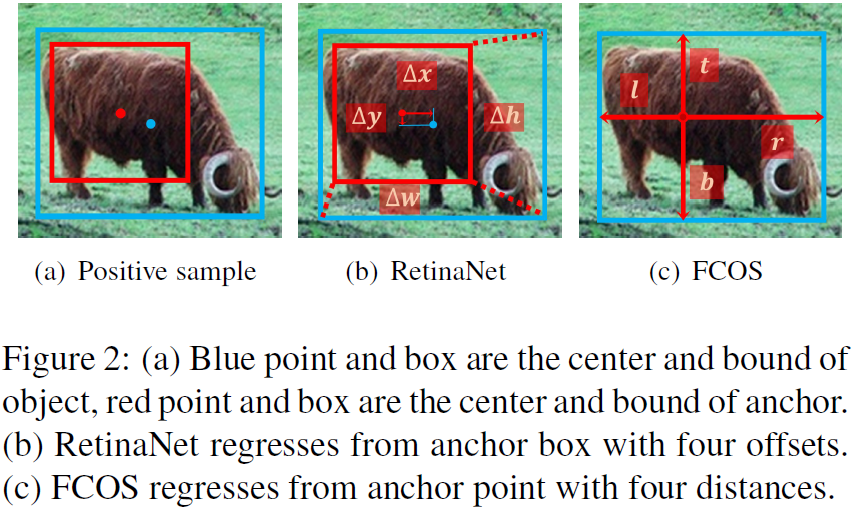
对于每个groundtruth box g,我们首先找到它的候选正样本。在每个level上,我们选择k个anchor box,它们的中心点和g的中心点的距离是最近的。假设有L的特征level,groundtruth box g就可以得到k×L个候选正样本,然后,我们计算这些候选正样本与g的IOU,这些IOU的均值和方差记为mg和vg,得到IOU的阈值tg=mg+vg,然后,我们在这些候选正样本中选择IOU大于等于阈值tg的作为最终的正样本。我们还特别的对正样本的中心做了限制,必须落在物体内部,另外,如果某个anchor box匹配到了多个groundtruth box上,只选择IOU最高的那个作为最终的匹配。其余的都是负样本。算法流程如下:

基于中心距离来选择候选正样本
对于RetinaNet,anchor box和groundtruth box的中心点越接近,IOU会越大,对于FCOS,anchor点和物体中心越接近,产生的检测的质量越高。因此,越靠近物体中心的anchor是更好的候选正样本。
使用均值和方差的和作为IOU的阈值
IOU的均值是这个物体和anchor box的匹配度的度量,mg越大表示候选正样本的质量越高,那么IOU的阈值可以设置的高一些。mg越小表示候选正样本的质量越低,阈值应该设置的小一些。vg是哪些特征level与这个物体相匹配的度量,vg高,表明对于这个物体,有一个非常匹配的特征level,可以使用较大的阈值只从哪个最匹配的层中选择正样本,而vg低,表明好几个特征level都可以和这个物体匹配,设置一个较小的阈值可以广泛的从这几个合适的层中都选出样本来作为正样本。见图3。
正样本中心的限制
anchor的中心点在物体外面的候选正样本是不好的正样本,这些正样本由物体外面的特征预测,在训练的时候应该去掉。
在不同的物体之间保持公平
根据统计理论,有16%的样本在[mg+vg, 1]的置信区间,虽然候选样本的IOU的分布并不是标准的正太分布,统计结果表明对于每个物体,有大约0.2×kL个正样本,这个对于尺度,比例,位置具有不变性,而对于RetinaNet和FCOS的策略,大的物体会趋向于有更多的正样本,这导致了不同尺度物体之间的不公平性。
几乎不需要超参数
这里只有一个超参数k,后面的实验表明了实验结果对于这个超参数其实并不敏感,所以可以认为是不需要超参数。
3.2 验证
Anchor based RetinaNet
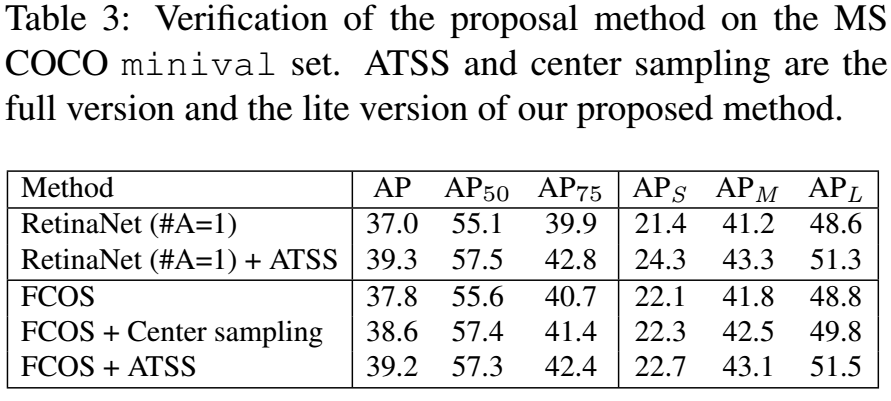
为了验证ATSS的有效性,我们用这个策略替换了RetinaNet(#A=1)中的策略,效果见表3。
Anchor Free FCOS
将ATSS方法用到FCOS中有两个版本,一个是lite版本,一个是full版本,对于lite版本,我们把ATSS的方法用到了FCOS中,替换了其中的样本选择的方法。FCOS把anchor点看做是候选样本点,这导致了大量的低质量的候选样本点,我们的方法在每个特征level中为每个GT选择了k=9个候选样本点。lite版本已经作为center sampling合并到了FCOS的官方代码中,将FCOS从37.8%提升到了38.6%。但是,尺度范围的超参数依然是存在的。
对于full版本,我们将FCOS中的anchor点变为使用8S尺度的anchor box来定义正负样本,但是仍然和anchor点一样进行回归。结果见表3。这两个版本具有相同的选择候选正样本的策略,差别在于在尺度维度选取最终正样本的方法。从表3可以看到,full版本要好于lite版本,这表明,自适应选择最终正样本的方法要比固定选择最终正样本的方法要好。
3.3 分析
在训练的时候,现在只有一个超参数k和相关的anchor box的设置。下面分别分析:
超参数k
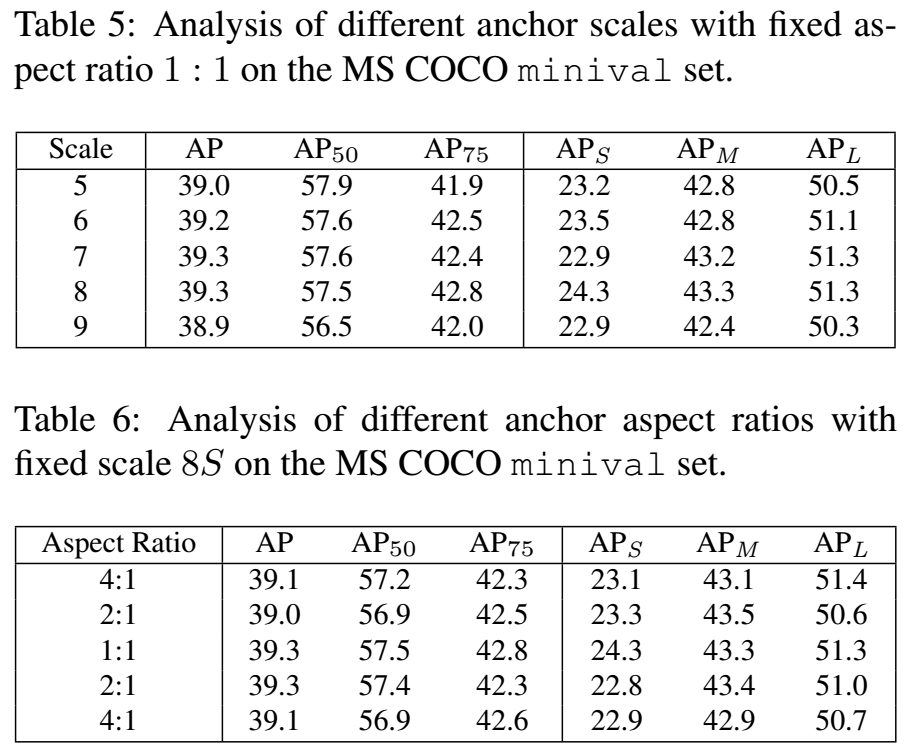
我们做了几个实验来验证超参数k的鲁棒性,见表4,我们使用了不同的k,发现了k的值在7~19的范围内对结果变化不大,太大的k导致了太多的低质量的候选样本反而会导致AP下降,k太小也会导致AP下降,因为太少的候选正样本会导致统计量不稳定。总的来说,超参数k是非常鲁棒的。

Anchor尺寸
在之前的实验中,使用的是一个8S(S表示该特征level的stride size)的正方形anchor,我们实验了不同尺度的正方形anchor,见表5,发现差别不大。另外,我们还实验了不同比例的anchor,见表6,也没什么差别。这表明该方法对于anchor的设置是不敏感的。
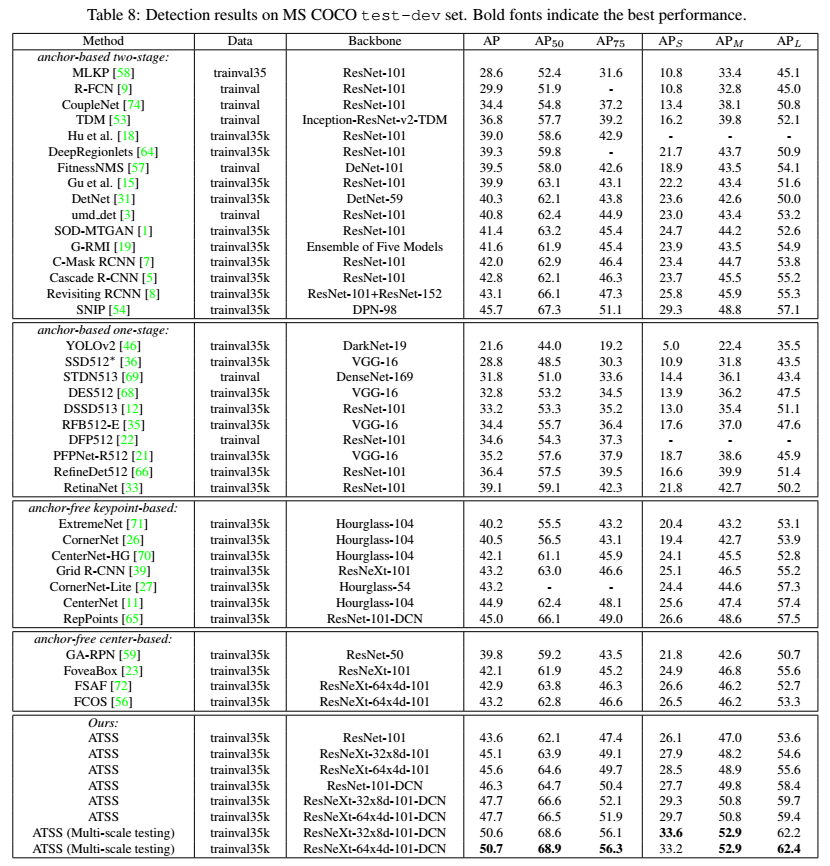
3.4 对比
和其他方法的对比。
3.5 讨论
之前的实验使用的是RetinaNet,每个位置只使用了一个anchor,对于anchor based和anchor free方法,其实还有一个区别,就是每个位置的anchor的数量,实际上,原始的RetinaNet每个位置有9个anchor,3个尺度和3个比例,我们记为RetinaNet (#A=9) ,从表7中可以看到,AP为36.3%,通用的优化方法也可以用在RetinaNet (#A=9) 上,将AP提升到了38.4%,这要比RetinaNet (#A=1) 要好,这说明,在传统的IOU based正负样本选择策略下,更多的anchor可以取得更好的效果。
但是,使用了我们的方法之后,RetinaNet (#A=9) 和RetinaNet (#A=1)的performance几乎一样。换句话说,只要样本选取的合理,每个位置选取多少anchor都是无所谓的。因此,我们认为,每个位置上的多个anchor是没有必要的。
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~