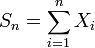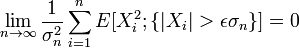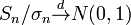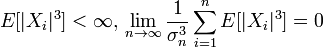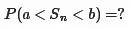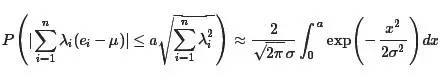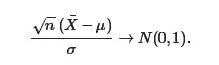日期 : 2021年09月30日
正文共 :10911字
来源 : cnblogs
导言:本文从微积分相关概念,梳理到概率论与数理统计中的相关知识,关于第四节正态分布的部分可以参考小君之前推出的正态分布的前世今生系列文章(彻底颠覆以前读书时大学课本灌输给你的观念,一探正态分布之神秘芳踪,知晓其前后发明历史由来)。相信,每一个学过概率论与数理统计的朋友都有必要了解数理统计学简史,因为,只有了解各个定理.公式的发明历史,演进历程.相关联系,才能更好的理解你眼前所见到的知识,才能更好的运用之。
本文结合高等数学上下册、微积分概念发展史,概率论与数理统计、数理统计学简史等书,对数据挖掘中所需的概率论与数理统计相关知识概念作个总结梳理。
本文篇幅会比较长,简单来说:
第一节、介绍微积分中极限、导数,微分、积分等相关概念;
第二节、介绍随机变量及其分布;
第三节、介绍数学期望.方差.协方差.相关系数.中心极限定理等概念;
第四节、依据数理统计学简史介绍正态分布的前后由来;
第五节、论道正态,介绍正态分布的4大数学推导。
第一节、微积分的基本概念
1.1、极限
极限又分为两部分:数列的极限和函数的极限。
1.1.1、数列的极限
定义 如果数列{xn}与常a 有下列关系:对于任意给定的正数e (不论它多么小), 总存在正整数N , 使得对于n >N 时的一切xn, 不等式 |xn-a |<e都成立, 则称常数a 是数列{xn}的极限, 或者称数列{xn}收敛于a。
1.1.2、函数的极限
设函数f(x)在点x0的某一去心邻域内有定义. 如果存在常数A, 对于任意给定的正数e (不论它多么小), 总存在正数d, 使得当x满足不等式0<|x-x0|<d 时, 对应的函数值f(x)都满足不等式 |f(x)-A|<e , 那么常数A就叫做函数f(x)时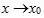 的极限, 记为
的极限, 记为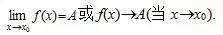
也就是说,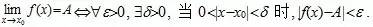
几乎没有一门新的数学分支是某个人单独的成果,如笛卡儿和费马的解析几何不仅仅是他们两人研究的成果,而是若干数学思潮在16世纪和17世纪汇合的产物,是由许许多多的学者共同努力而成。
甚至微积分的发展也不是牛顿与莱布尼茨两人之功。在17世纪下半叶,数学史上出现了无穷小的概念,而后才发展到极限,到后来的微积分的提出。然就算牛顿和莱布尼茨提出了微积分,但微积分的概念尚模糊不清,在牛顿和莱布尼茨之后,后续经过一个多世纪的发展,诸多学者的努力,才真正清晰了微积分的概念。
也就是说,从无穷小到极限,再到微积分定义的真正确立,经历了几代人几个世纪的努力,而课本上所呈现的永远只是冰山一角。
1.2、导数
设有定义域和取值都在实数域中的函数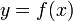 。若
。若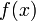 在点
在点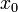 的某个邻域内有定义,则当自变量
的某个邻域内有定义,则当自变量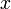 在处取得增量
在处取得增量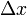 (点
(点 仍在该邻域内)时,相应地函数
仍在该邻域内)时,相应地函数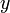 取得增量
取得增量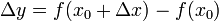 ;如果
;如果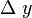 与之比当
与之比当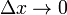 时的极限存在,则称函数
时的极限存在,则称函数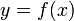 在点处可导,并称这个极限为函数在点处的导数,记为
在点处可导,并称这个极限为函数在点处的导数,记为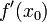 。
。
即:
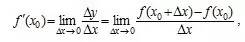
也可记为: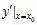 ,
,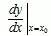 或
或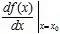 。
。
1.3、微分
设函数在某区间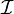 内有定义。对于内一点,当变动到附近的
内有定义。对于内一点,当变动到附近的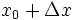 (也在此区间内)时。如果函数的增量可表示为
(也在此区间内)时。如果函数的增量可表示为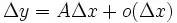 (其中
(其中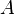 是不依赖于
是不依赖于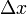 的常数),而
的常数),而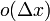 是比高阶的无穷小,那么称函数
是比高阶的无穷小,那么称函数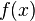 在点是可微的,且
在点是可微的,且 称作函数在点相应于自变量增量的微分,记作
称作函数在点相应于自变量增量的微分,记作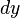 ,即
,即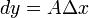 ,是
,是 的线性主部。通常把自变量
的线性主部。通常把自变量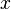 的增量称为自变量的微分,记作
的增量称为自变量的微分,记作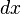 ,即
,即 。
。
实际上,前面讲了导数,而微积分则是在导数的基础上加个后缀,即为: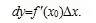 。
。
1.4、积分
积分是微积分学与数学分析里的一个核心概念。通常分为定积分和不定积分两种。
不定积分的定义:
一个函数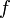 的不定积分,也称为原函数或反导数,是一个导数等于的函数
的不定积分,也称为原函数或反导数,是一个导数等于的函数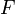 ,即
,即

不定积分的有换元积分法,分部积分法等求法。
定积分的定义
直观地说,对于一个给定的正实值函数,在一个实数区间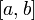 上的定积分:
上的定积分:
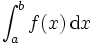
定积分与不定积分区别在于不定积分便是不给定区间,也就是说,上式子中,积分符号没有a、b。下面,介绍定积分中值定理。
如果函数f(x)在闭区间[a,b]上连续, 则在积分区间[a,b]上至少存在一个点,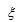 使下式成立:
使下式成立:
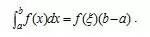
这个公式便叫积分中值公式。
牛顿-莱布尼茨公式
接下来,咱们讲介绍微积分学中最重要的一个公式:牛顿-莱布尼茨公式。
如果函数F (x)是连续函数f(x)在区间[a, b]上的一个原函数, 则
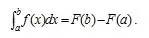
此公式称为牛顿-莱布尼茨公式, 也称为微积分基本公式。这个公式由此便打通了原函数与定积分之间的联系,它表明:一个连续函数在区间[a, b]上的定积分等于它的任一个原函数在区间[a, b]上的增量,如此,便给定积分提供了一个有效而极为简单的计算方法,大大简化了定积分的计算手续。
下面,举个例子说明如何通过原函数求取定积分。
如要计算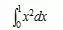 ,由于
,由于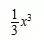 是
是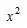 的一个原函数,所以
的一个原函数,所以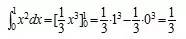 。
。
1.5、偏导数
对于二元函数z = f(x,y) 如果只有自变量x 变化,而自变量y固定 这时它就是x的一元函数,这函数对x的导数,就称为二元函数z = f(x,y)对于x的偏导数。定义 设函数z = f(x,y)在点(x0,y0)的某一邻域内有定义,当y固定在y0而x在x0处有增量时,相应地函数有增量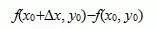 ,
,
如果极限
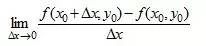
存在,则称此极限为函数z = f(x,y)在点(x0,y0)处对 x 的偏导数,记作:
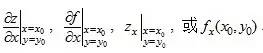
例如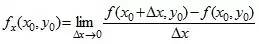 。类似的,二元函数对y求偏导,则把x当做常量。
。类似的,二元函数对y求偏导,则把x当做常量。
第二节、离散.连续.多维随机变量及其分布
2.1、几个基本概念点
(一)样本空间
定义:随机试验E的所有结果构成的集合称为E的 样本空间,记为S={e},称S中的元素e为样本点,一个元素的单点集称为基本事件.
(二)条件概率
- 条件概率就是事件A在另外一个事件B已经发生条件下的发生概率。条件概率表示为P(A|B),读作“在B条件下A的概率”。
- 联合概率表示两个事件共同发生的概率。A与B的联合概率表示为
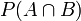 或者
或者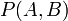 。
。 - 边缘概率是某个事件发生的概率。边缘概率是这样得到的:在联合概率中,把最终结果中不需要的那些事件合并成其事件的全概率而消失(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率)。这称为边缘化(marginalization)。A的边缘概率表示为P(A),B的边缘概率表示为P(B)。
在同一个样本空间Ω中的事件或者子集A与B,如果随机从Ω中选出的一个元素属于B,那么这个随机选择的元素还属于A的概率就定义为在B的前提下A的条件概率。从这个定义中,我们可以得出P(A|B) = |A∩B|/|B|分子、分母都除以|Ω|得到
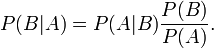 。
。
假设{ Bn : n = 1, 2, 3, ... } 是一个概率空间的有限或者可数无限的分割,且每个集合Bn是一个可测集合,则对任意事件A有全概率公式:
所以,此处Pr(A | B)是B发生后A的条件概率,所以全概率公式又可写作:
在离散情况下,上述公式等于下面这个公式: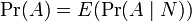 。但后者在连续情况下仍然成立:此处N是任意随机变量。这个公式还可以表达为:"A的先验概率等于A的后验概率的先验期望值。 贝叶斯定理(Bayes' theorem),是概率论中的一个结果,它跟随机变量的条件概率以及边缘概率分布有关。在有些关于概率的解说中,贝叶斯定理(贝叶斯更新)能够告知我们如何利用新证据修改已有的看法。通常,事件A在事件B(发生)的条件下的概率,与事件B在事件A的条件下的概率是不一样的;然而,这两者是有确定的关系,贝叶斯定理就是这种关系的陈述。贝叶斯定理实际上是关于随机事件A和B的条件概率和边缘概率的一则定理。
。但后者在连续情况下仍然成立:此处N是任意随机变量。这个公式还可以表达为:"A的先验概率等于A的后验概率的先验期望值。 贝叶斯定理(Bayes' theorem),是概率论中的一个结果,它跟随机变量的条件概率以及边缘概率分布有关。在有些关于概率的解说中,贝叶斯定理(贝叶斯更新)能够告知我们如何利用新证据修改已有的看法。通常,事件A在事件B(发生)的条件下的概率,与事件B在事件A的条件下的概率是不一样的;然而,这两者是有确定的关系,贝叶斯定理就是这种关系的陈述。贝叶斯定理实际上是关于随机事件A和B的条件概率和边缘概率的一则定理。
如上所示,其中P(A|B)是在B发生的情况下A发生的可能性。在贝叶斯定理中,每个名词都有约定俗成的名称:
- P(A)是A的先验概率或边缘概率。之所以称为"先验"是因為它不考虑任何B方面的因素。
- P(A|B)是已知B发生后A的条件概率(直白来讲,就是先有B而后=>才有A),也由于得自B的取值而被称作A的后验概率。
- P(B|A)是已知A发生后B的条件概率(直白来讲,就是先有A而后=>才有B),也由于得自A的取值而被称作B的后验概率。
- P(B)是B的先验概率或边缘概率,也作标准化常量(normalized constant)。
按这些术语,Bayes定理可表述为:后验概率 = (相似度*先验概率)/标准化常量,也就是說,后验概率与先验概率和相似度的乘积成正比。另外,比例P(B|A)/P(B)也有时被称作标准相似度(standardised likelihood),Bayes定理可表述为:后验概率 = 标准相似度*先验概率。”综上,自此便有了一个问题,如何从从条件概率推导贝叶斯定理呢?根据条件概率的定义,在事件B发生的条件下事件A发生的概率是
这个引理有时称作概率乘法规则。上式两边同除以P(B),若P(B)是非零的,我们可以得到贝叶斯定理:
2.2、随机变量及其分布
2.2.1、何谓随机变量
何谓随机变量?即给定样本空间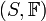 ,其上的实值函数
,其上的实值函数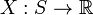 称为(实值)随机变量。如果随机变量
称为(实值)随机变量。如果随机变量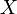 的取值是有限的或者是可数无穷尽的值,则称为离散随机变量(用白话说,此类随机变量是间断的)。
的取值是有限的或者是可数无穷尽的值,则称为离散随机变量(用白话说,此类随机变量是间断的)。
如果由全部实数或者由一部分区间组成,则称为连续随机变量,连续随机变量的值是不可数及无穷尽的(用白话说,此类随机变量是连续的,不间断的):
也就是说,随机变量分为离散型随机变量,和连续型随机变量,当要求随机变量的概率分布的时候,要分别处理之,如:- 针对离散型随机变量而言,一般以加法的形式处理其概率和;
- 而针对连续型随机变量而言,一般以积分形式求其概率和。
再换言之,对离散随机变量用求和得全概率,对连续随机变量用积分得全概率。这点包括在第4节中相关期望.方差.协方差等概念会反复用到,望读者注意之。2.2.2、离散型随机变量的定义
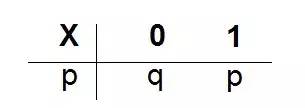
定义:取值至多可数的随机变量为离散型的随机变量。概率分布(分布律)为
且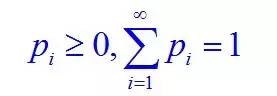
同时,p+q=1,p>0,q>0,则则称X服从参数为p的0-1分布,或两点分布。
二项分布是n个独立的是/非试验中成功的次数的离散概率分布,其中每次试验的成功概率为p。这样的单次成功/失败试验又称为伯努利试验。举个例子就是,独立重复地抛n次硬币,每次只有两个可能的结果:正面,反面,概率各占1/2。
与此同时, Poisson分布(法语:loi de Poisson,英语:Poisson distribution),即泊松分布,是一种统计与概率学里常见到的离散概率分布,由法国数学家西莫恩·德尼·泊松(Siméon-Denis Poisson)在1838年时发表。
Poisson分布(法语:loi de Poisson,英语:Poisson distribution),即泊松分布,是一种统计与概率学里常见到的离散概率分布,由法国数学家西莫恩·德尼·泊松(Siméon-Denis Poisson)在1838年时发表。
有一点提前说一下,泊松分布中,其数学期望与方差相等,都为参数λ。 在二项分布的伯努力试验中,如果试验次数n很大,二项分布的概率p很小,且乘积λ= n p比较适中,则事件出现的次数的概率可以用泊松分布来逼近。事实上,二项分布可以看作泊松分布在离散时间上的对应物。证明如下。
上述过程表明:Poisson(λ) 分布可以看成是二项分布 B(n,p) 在 np=λ,n→∞ 条件下的极限分布。 给定n个样本值ki,希望得到从中推测出总体的泊松分布参数λ的估计。为计算最大似然估计值, 列出对数似然函数:
解得λ从而得到一个驻点(stationary point):
检查函数L的二阶导数,发现对所有的λ 与ki大于零的情况二阶导数都为负。因此求得的驻点是对数似然函数L的极大值点:
证毕。OK,上面内容都是针对的离散型随机变量,那如何求连续型随机变量的分布律呢?请接着看以下内容。2.2.3、随机变量分布函数定义的引出
- 对于离散型随机变量而言,其所有可能的取值可以一一列举出来,
- 可对于非离散型随机变量,即连续型随机变量X而言,其所有可能的值则无法一一列举出来,
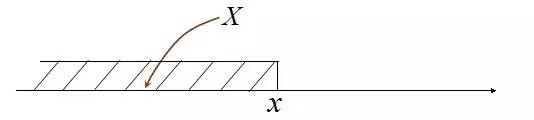
故连续型随机变量也就不能像离散型随机变量那般可以用分布律来描述它,那怎么办呢(事实上,只有因为连续,所以才可导,所以才可积分,这些东西都是相通的。当然了,连续不一定可导,但可导一定连续)? 既然无法研究其全部,那么我们可以转而去研究连续型随机变量所取的值在一个区间(x1,x2] 的概率:P{x1 < X <=x2 },同时注意P{x1 < X <=x2 } = P{X <=x2} - P{X <=x1},故要求P{x1 < X <=x2 } ,我们只需求出P{X <=x2} 和 P{X <=x1} 即可。 针对随机变量X,对应变量x,则P(X<=x) 应为x的函数。如此,便引出了分布函数的定义。 定义:随机变量X,对任意实数x,称函数F(x) = P(X <=x ) 为X 的概率分布函数,简称分布函数。 且对于任意实数x1,x2(x1<x2),有P{x1<X<=x2} = P{X <=x2} - P{X <= x1} = F(x2) - F(x1)。
2.2.4、连续型随机变量及其概率密度
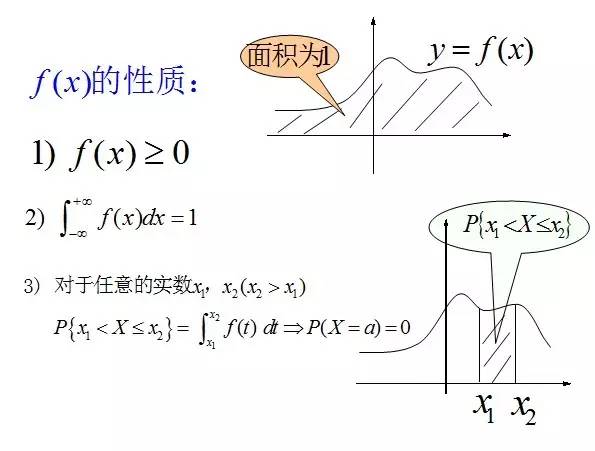
定义:对于随机变量X的分布函数F(x),若存在非负的函数f(x),使对于任意实数x,有:
则称X为连续型随机变量,其中f(x)称为X的概率密度函数,简称概率密度。连续型随机变量的概率密度f(x)有如下性质: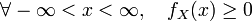 ;
;
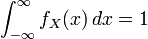 ;
;
- 在上文第1.4节中,有此牛顿-莱布尼茨公式:如果函数F (x)是连续函数f(x)在区间[a, b]上的一个原函数, 则;
- 在上文2.2.3节,连续随机变量X 而言,对于任意实数a,b(a<b),有P{a<X<=b} = P{X <=b} - P{X <= a} = F(b) - F(a);
且如果概率密度函数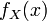 在一点上连续,那么累积分布函数可导,并且它的导数:
在一点上连续,那么累积分布函数可导,并且它的导数: 。如下图所示: 接下来,介绍三种连续型随机变量的分布,由于均匀分布及指数分布比较简单,所以,一图以概之,正态分布可以查阅之前推出的文章。
。如下图所示: 接下来,介绍三种连续型随机变量的分布,由于均匀分布及指数分布比较简单,所以,一图以概之,正态分布可以查阅之前推出的文章。
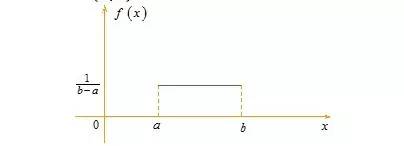
则称X 在区间(a,b)上服从均匀分布,记为X~U(a,b)。
易知,f(x) >= 0,且其期望值为(a + b)/ 2。
其中λ>0为常数,则称X服从参数为λ的指数分布。记为
在各种公式纷至沓来之前,我先说一句:正态分布没有你想的那么神秘,它无非是研究误差分布的一个理论,因为实践过程中,测量值和真实值总是存在一定的差异,这个不可避免的差异即误差,而误差的出现或者分布是有规律的,而正态分布不过就是研究误差的分布规律的一个理论。 OK,若随机变量服从一个位置参数为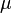 、尺度参数为
、尺度参数为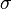 的概率分布,记为:
的概率分布,记为:
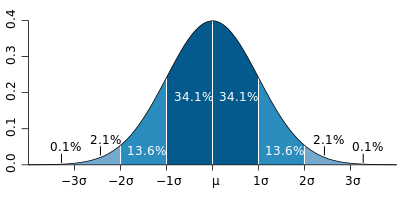
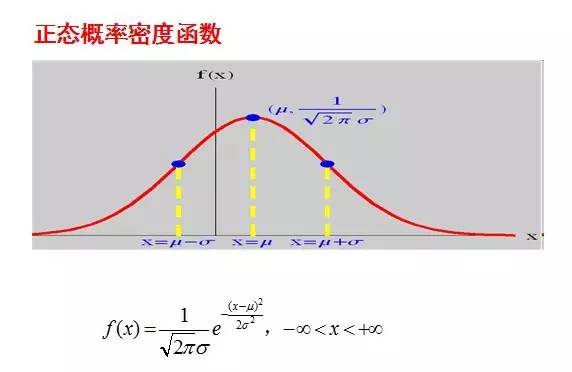
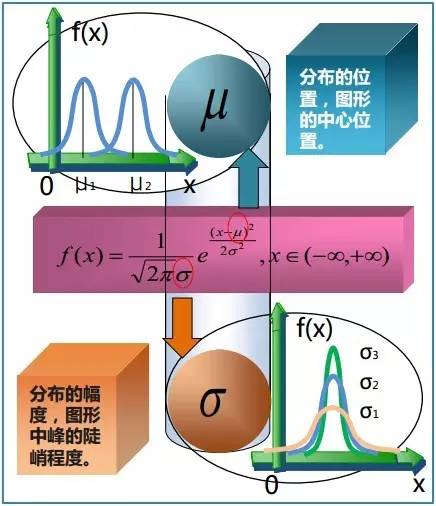
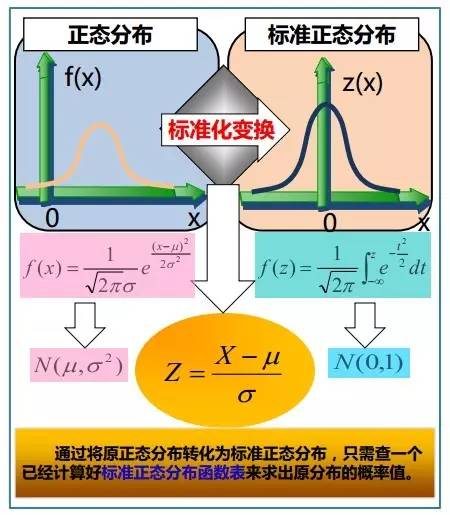
正态分布的数学期望值或期望值等于位置参数,决定了分布的位置;其方差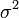 的开平方,即标准差等于尺度参数,决定了分布的幅度。正态分布的概率密度函数曲线呈钟形,因此人们又经常称之为钟形曲线。它有以下几点性质,如下图所示:
的开平方,即标准差等于尺度参数,决定了分布的幅度。正态分布的概率密度函数曲线呈钟形,因此人们又经常称之为钟形曲线。它有以下几点性质,如下图所示:
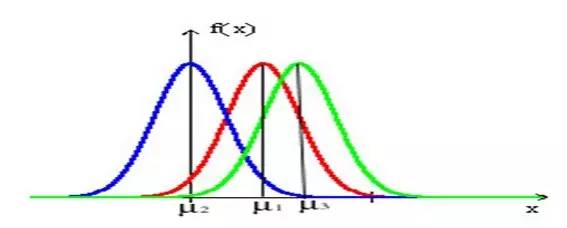
当固定尺度参数,改变位置参数的大小时,f(x)图形的形状不变,只是沿着x轴作平移变换,如下图所示:
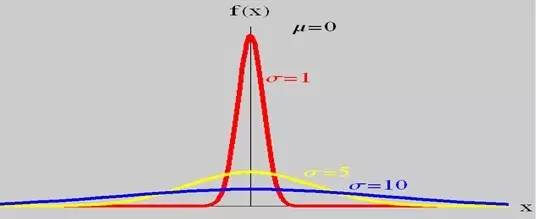
而当固定位置参数,改变尺度参数的大小时,f(x)图形的对称轴不变,形状在改变,越小,图形越高越瘦,越大,图形越矮越胖。如下图所示:
故有咱们上面的结论,在正态分布中,称μ为位置参数(决定对称轴位置),而 σ为尺度参数(决定曲线分散性)。同时,在自然现象和社会现象中,大量随机变量服从或近似服从正态分布。 而我们通常所说的标准正态分布是位置参数 , 尺度参数
, 尺度参数 的正态分布,记为:
的正态分布,记为:
相关内容如下两图总结所示(来源:大嘴巴漫谈数据挖掘):2.2.5、各种分布的比较
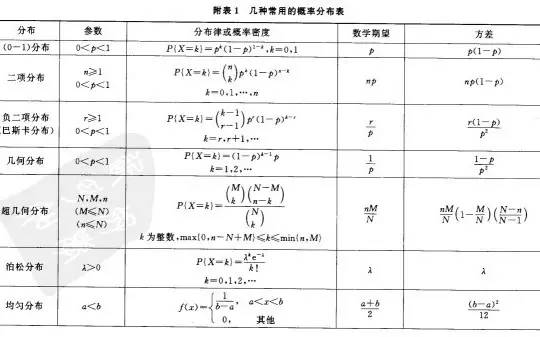
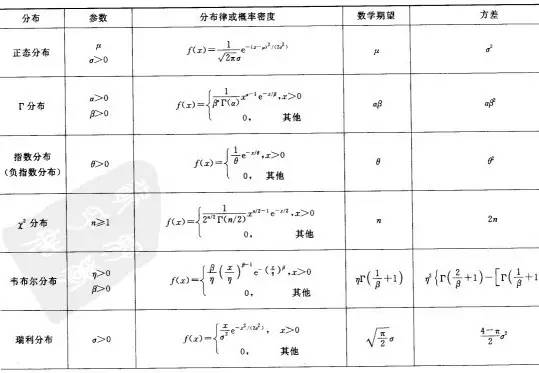
上文中,从离散型随机变量的分布:(0-1)分布、泊松分布、二项分布,讲到了连续型随机变量的分布:均匀分布、指数分布、正态分布,那这么多分布,其各自的期望.方差(期望方差的概念下文将予以介绍)都是多少呢?虽说,还有不少分布上文尚未介绍,不过在此,提前总结下,如下两图所示(摘自盛骤版的概率论与数理统计一书后的附录中):第三节、从数学期望、方差、协方差到中心极限定理
3.1、数学期望、方差、协方差
3.1.1、数学期望
如果X是在概率空间(Ω, P)中的一个随机变量,那么它的期望值E[X]的定义是:
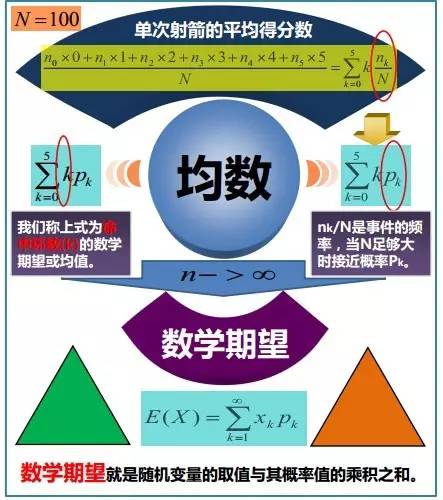
并不是每一个随机变量都有期望值的,因为有的时候这个积分不存在。如果两个随机变量的分布相同,则它们的期望值也相同。 在概率论和统计学中,数学期望分两种(依照上文第二节相关内容也可以得出),一种为离散型随机变量的期望值,一种为连续型随机变量的期望值。- 一个离散性随机变量的期望值(或数学期望、或均值,亦简称期望)是试验中每次可能结果的概率乘以其结果的总和。换句话说,期望值是随机试验在同样的机会下重复多次的结果计算出的等同“期望”的平均值。
例如,掷一枚六面骰子,得到每一面的概率都为1/6,故其的期望值是3.5,计算如下:
承上,如果X 是一个离散的随机变量,输出值为x1, x2, ..., 和输出值相应的概率为p1, p2, ...(概率和为1),若级数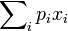 绝对收敛,那么期望值E[X]是一个无限数列的和:
绝对收敛,那么期望值E[X]是一个无限数列的和:
- 而对于一个连续型随机变量来说,如果X的概率分布存在一个相应的概率密度函数f(x),若积分
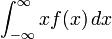 绝对收敛,那么X 的期望值可以计算为:
绝对收敛,那么X 的期望值可以计算为:
实际上,此连续随机型变量的期望值的求法与离散随机变量的期望值的算法同出一辙,由于输出值是连续的,只不过是把求和改成了积分。
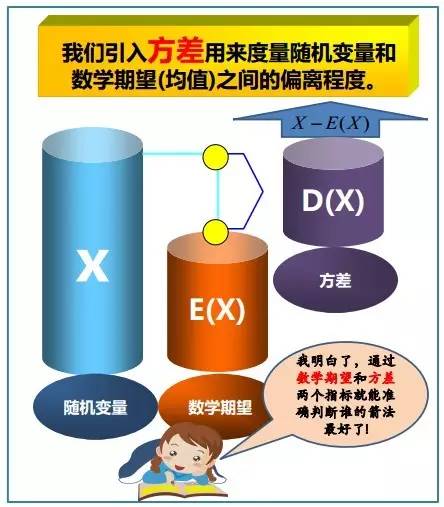
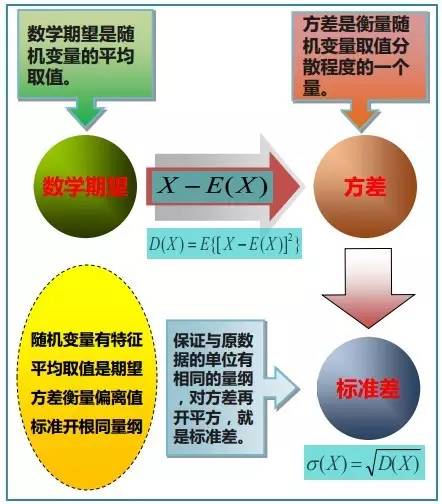
3.1.2、方差与标准差
在概率论和统计学中,一个随机变量的方差(Variance)描述的是它的离散程度,也就是该变量离其期望值的距离。一个实随机变量的方差也称为它的二阶矩或二阶中心动差,恰巧也是它的二阶累积量。方差的算术平方根称为该随机变量的标准差。 其定义为:如果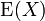 是随机变量X的期望值(平均数) 设为服从分布的随机变量,则称
是随机变量X的期望值(平均数) 设为服从分布的随机变量,则称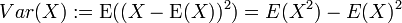 为随机变量或者分布的方差:
为随机变量或者分布的方差:
分别针对离散型随机变量和连续型随机变量而言,方差的分布律和概率密度如下图所示:
标准差(Standard Deviation),在概率统计中最常使用作为统计分布程度(statistical dispersion)上的测量。标准差定义为方差的算术平方根,反映组内个体间的离散程度。
简单来说,标准差是一组数值自平均值分散开来的程度的一种测量观念。一个较大的标准差,代表大部分的数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。例如,两组数的集合 {0, 5, 9, 14} 和 {5, 6, 8, 9} 其平均值都是 7 ,但第二个集合具有较小的标准差。 前面说过,方差的算术平方根称为该随机变量的标准差,故一随机变量的标准差定义为:
须注意并非所有随机变量都具有标准差,因为有些随机变量不存在期望值。 如果随机变量为 具有相同概率,则可用上述公式计算标准差。
具有相同概率,则可用上述公式计算标准差。
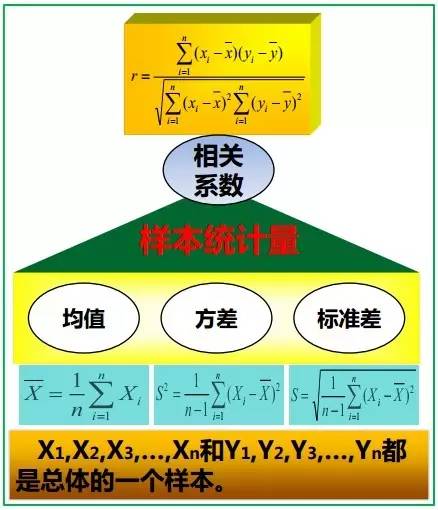
在真实世界中,除非在某些特殊情况下,找到一个总体的真实的标准差是不现实的。大多数情况下,总体标准差是通过随机抽取一定量的样本并计算样本标准差估计的。说白了,就是数据海量,想计算总体海量数据的标准差无异于大海捞针,那咋办呢?抽取其中一些样本作为抽样代表呗。 而从一大组数值 当中取出一样本数值组合
当中取出一样本数值组合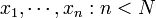 ,进而,我们可以定义其样本标准差为:
,进而,我们可以定义其样本标准差为:
样本方差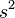 是对总体方差
是对总体方差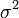 的无偏估计。
的无偏估计。  中分母为 n-1 是因为
中分母为 n-1 是因为 的自由度为n-1(且慢,何谓自由度?简单说来,即指样本中的n个数都是相互独立的,从其中抽出任何一个数都不影响其他数据,所以自由度就是估计总体参数时独立数据的数目,而平均数是根据n个独立数据来估计的,因此自由度为n),这是由于存在约束条件
的自由度为n-1(且慢,何谓自由度?简单说来,即指样本中的n个数都是相互独立的,从其中抽出任何一个数都不影响其他数据,所以自由度就是估计总体参数时独立数据的数目,而平均数是根据n个独立数据来估计的,因此自由度为n),这是由于存在约束条件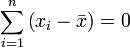 。
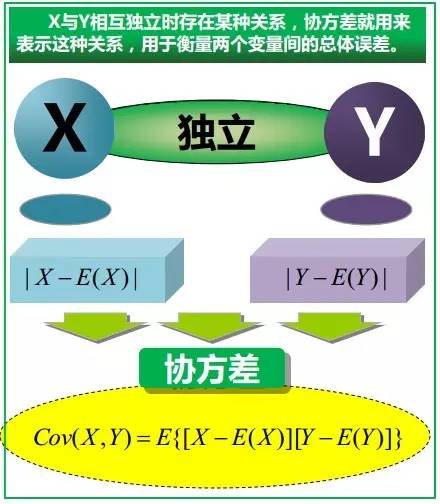
。 3.1.3、协方差与相关系数
下图即可说明何谓协方差,同时,引出相关系数的定义:相关系数 ( Correlation coefficient )的定义是:
(其中,E为数学期望或均值,D为方差,D开根号为标准差,E{ [X-E(X)] [Y-E(Y)]}称为随机变量X与Y的协方差,记为Cov(X,Y),即Cov(X,Y) = E{ [X-E(X)] [Y-E(Y)]},而两个变量之间的协方差和标准差的商则称为随机变量X与Y的相关系数,记为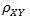 )
)
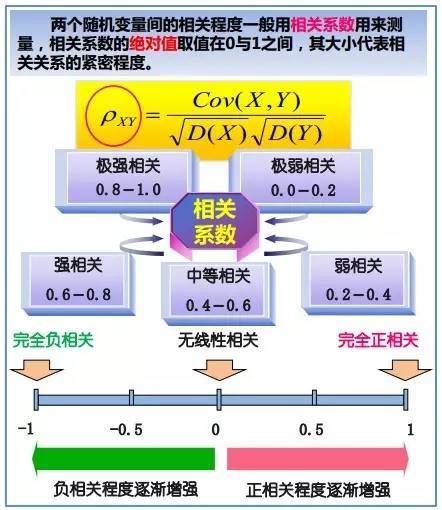
相关系数衡量随机变量X与Y相关程度的一种方法,相关系数的取值范围是[-1,1]。相关系数的绝对值越大,则表明X与Y相关度越高。当X与Y线性相关时,相关系数取值为1(正线性相关)或-1(负线性相关)。
具体的,如果有两个变量:X、Y,最终计算出的相关系数的含义可以有如下理解:- 当X的值增大(减小),Y值增大(减小),两个变量为正相关,相关系数在0.00与1.00之间。
- 当X的值增大(减小),Y值减小(增大),两个变量为负相关,相关系数在-1.00与0.00之间。
自此,已经介绍完期望方差协方差等基本概念,但一下子要读者接受那么多概念,怕是有难为读者之嫌,不如再上几幅图巩固下上述相关概念吧(来源:大嘴巴漫谈数据挖掘):3.1.4、协方差矩阵与主成成分分析
由上,我们已经知道:协方差是衡量两个随机变量的相关程度。且随机变量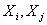 之间的协方差可以表示为 尽管从上面看来,协方差矩阵貌似很简单,可它却是很多领域里的非常有力的工具。它能导出一个变换矩阵,这个矩阵能使数据完全去相关(decorrelation)。从不同的角度看,也就是说能够找出一组最佳的基以紧凑的方式来表达数据。这个方法在统计学中被称为主成分分析(principal components analysis,简称PCA),在图像处理中称为Karhunen-Loève 变换(KL-变换)。 根据wikipedia上的介绍,主成分分析PCA由卡尔·皮尔逊于1901年发明,用于分析数据及建立数理模型。其方法主要是通过对协方差矩阵进行特征分解,以得出数据的主成分(即特征矢量)与它们的权值(即特征值)。PCA是最简单的以特征量分析多元统计分布的方法。其结果可以理解为对原数据中的方差做出解释:哪一个方向上的数据值对方差的影响最大。 然为何要使得变换后的数据有着最大的方差呢?我们知道,方差的大小描述的是一个变量的信息量,我们在讲一个东西的稳定性的时候,往往说要减小方差,如果一个模型的方差很大,那就说明模型不稳定了。但是对于我们用于机器学习的数据(主要是训练数据),方差大才有意义,不然输入的数据都是同一个点,那方差就为0了,这样输入的多个数据就等同于一个数据了。 简而言之,主成分分析PCA,留下主成分,剔除噪音,是一种降维方法,限高斯分布,n维眏射到k维,
之间的协方差可以表示为 尽管从上面看来,协方差矩阵貌似很简单,可它却是很多领域里的非常有力的工具。它能导出一个变换矩阵,这个矩阵能使数据完全去相关(decorrelation)。从不同的角度看,也就是说能够找出一组最佳的基以紧凑的方式来表达数据。这个方法在统计学中被称为主成分分析(principal components analysis,简称PCA),在图像处理中称为Karhunen-Loève 变换(KL-变换)。 根据wikipedia上的介绍,主成分分析PCA由卡尔·皮尔逊于1901年发明,用于分析数据及建立数理模型。其方法主要是通过对协方差矩阵进行特征分解,以得出数据的主成分(即特征矢量)与它们的权值(即特征值)。PCA是最简单的以特征量分析多元统计分布的方法。其结果可以理解为对原数据中的方差做出解释:哪一个方向上的数据值对方差的影响最大。 然为何要使得变换后的数据有着最大的方差呢?我们知道,方差的大小描述的是一个变量的信息量,我们在讲一个东西的稳定性的时候,往往说要减小方差,如果一个模型的方差很大,那就说明模型不稳定了。但是对于我们用于机器学习的数据(主要是训练数据),方差大才有意义,不然输入的数据都是同一个点,那方差就为0了,这样输入的多个数据就等同于一个数据了。 简而言之,主成分分析PCA,留下主成分,剔除噪音,是一种降维方法,限高斯分布,n维眏射到k维,
- 取最大的k个特征值所对应的特征向量组成特征向量矩阵,
- 投影数据=原始样本矩阵x特征向量矩阵。其依据为最大方差,最小平方误差或坐标轴相关度理论,及矩阵奇异值分解SVD(即SVD给PCA提供了另一种解释)。
也就是说,高斯是0均值,其方差定义了信噪比,所以PCA是在对角化低维表示的协方差矩阵,故某一个角度而言,只需要理解方差、均值和协方差的物理意义,PCA就很清晰了。 再换言之,PCA提供了一种降低数据维度的有效办法;如果分析者在原数据中除掉最小的特征值所对应的成分,那么所得的低维度数据必定是最优化的(也即,这样降低维度必定是失去讯息最少的方法)。主成分分析在分析复杂数据时尤为有用,比如人脸识别。3.2、中心极限定理
本节先给出现在一般的概率论与数理统计教材上所介绍的2个定理,然后简要介绍下中心极限定理的相关历史。3.2.1、独立同分布的中心极限定理
3.2.2、棣莫弗-拉普拉斯中心极限定理
此外,据wikipedia上的介绍,包括上面介绍的棣莫弗-拉普拉斯定理在内,历史上前后发展了三个相关的中心极限定理,它们得出的结论及内容分别是:- 棣莫弗-拉普拉斯(de Movire - Laplace)定理是中心极限定理的最初版本,讨论了服从二项分布的随机变量序列。
其内容为:若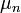 是n次伯努利实验中事件A出现的次数,
是n次伯努利实验中事件A出现的次数,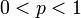 ,则对任意有限区间
,则对任意有限区间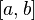 :
:
(i)当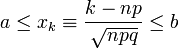 及
及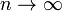 时,一致地有
时,一致地有
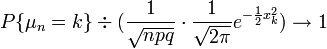
(ii)当时,一致地有,
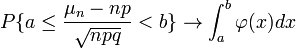 ,其中
,其中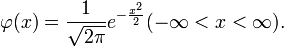 。 它指出,参数为n, p的二项分布以np为均值、np(1-p)为方差的正态分布为极限。
。 它指出,参数为n, p的二项分布以np为均值、np(1-p)为方差的正态分布为极限。 - 林德伯格-列维(Lindeberg-Levy)定理,是棣莫佛-拉普拉斯定理的扩展,讨论独立同分布随机变量序列的中心极限定理。
其内容为:设随机变量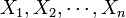 独立同分布, 且具有有限的数学期望和方差
独立同分布, 且具有有限的数学期望和方差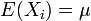 ,
,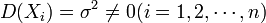 。它表明,独立同分布、且数学期望和方差有限的随机变量序列的标准化和以标准正态分布为极限。
。它表明,独立同分布、且数学期望和方差有限的随机变量序列的标准化和以标准正态分布为极限。- 林德伯格-费勒定理,是中心极限定理的高级形式,是对林德伯格-列维定理的扩展,讨论独立,但不同分布的情况下的随机变量和。
其内容为:记随机变量序列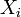 (独立但不一定同分布,
(独立但不一定同分布,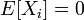 且有有限方差)部分和为
且有有限方差)部分和为
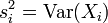 ,
,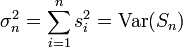
如果对每个 ,序列满足
,序列满足
则称它满足林德伯格(Lindeberg)条件。
满足此条件的序列趋向于正态分布,即
它表明,满足一定条件时,独立,但不同分布的随机变量序列的标准化和依然以标准正态分布为极限。3.2.3、历史
1776年,拉普拉斯开始考虑一个天文学中的彗星轨道的倾角的计算问题,最终的问题涉及独立随机变量求和的概率计算,也就是计算如下的概率值
令 Sn=X1+X2+⋯+Xn, 那么
在这个问题的处理上,拉普拉斯充分展示了其深厚的数学分析功底和高超的概率计算技巧,他首次引入了特征函数(也就是对概率密度函数做傅立叶变换)来处理概率分布的神妙方法,而这一方法经过几代概率学家的发展,在现代概率论里面占有极其重要的位置。基于这一分析方法,拉普拉斯通过近似计算,在他的1812年的名著《概率分析理论》中给出了中心极限定理的一般描述: [定理Laplace,1812]设 ei(i=1,⋯n)为独立同分布的测量误差,具有均值μ和方差σ2。如果λ1,⋯,λn为常数,a>0,则有
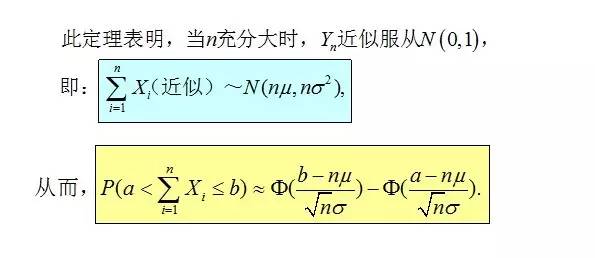
这已经是比棣莫弗-拉普拉斯中心极限定理更加深刻的一个结论了,在现在大学本科的教材上,包括包括本文主要参考之一盛骤版的概率论与数理统计上,通常给出的是中心极限定理的一般形式: [Lindeberg-Levy中心极限定理] 设X1,⋯,Xn独立同分布,且具有有限的均值μ和方差σ2,则在n→∞时,有
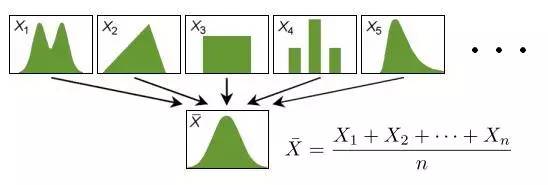
多么奇妙的性质,随意的一个概率分布中生成的随机变量,在序列和(或者等价的求算术平均)的操作之下,表现出如此一致的行为,统一的规约到正态分布。 概率学家们进一步的研究结果更加令人惊讶,序列求和最终要导出正态分布的条件并不需要这么苛刻,即便X1,⋯,Xn并不独立,也不具有相同的概率分布形式,很多时候他们求和的最终归宿仍然是正态分布。
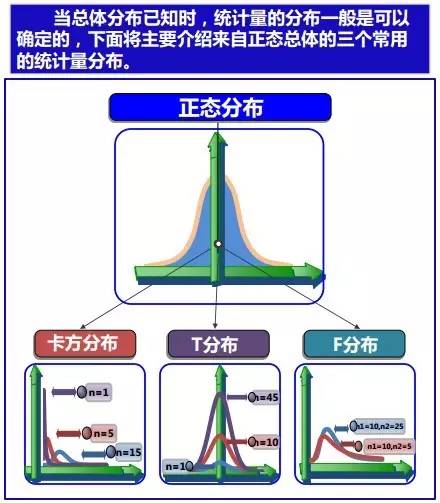
在正态分布、中心极限定理的确立之下,20世纪之后,统计学三大分布χ2分布、t分布、F分布也逐步登上历史舞台:
- 中心极限定理理的第一版被法国数学家棣莫弗发现,他在1733年发表的卓越论文中使用正态分布去估计大量抛掷硬币出现正面次数的分布;
- 1812年,法国数学家拉普拉斯在其巨著 Théorie Analytique des Probabilités中扩展了棣莫弗的理论,指出二项分布可用正态分布逼近;
- 1901年,俄国数学家李雅普诺夫用更普通的随机变量定义中心极限定理并在数学上进行了精确的证明。
如今,中心极限定理被认为是(非正式地)概率论中的首席定理。

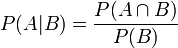
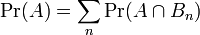
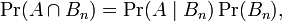
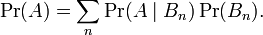
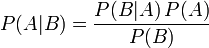
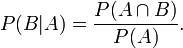
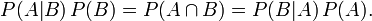
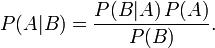
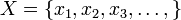
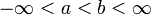

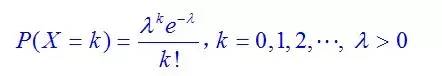
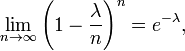
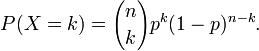
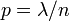 ,
,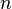 趋于无穷时
趋于无穷时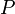 的极限:
的极限: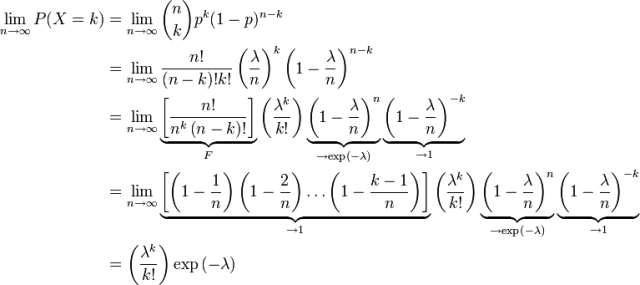
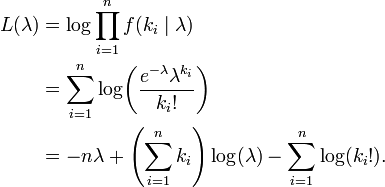
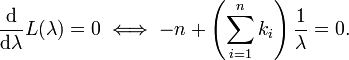
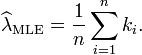
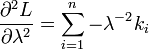

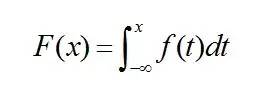
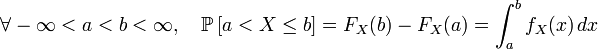

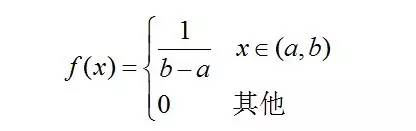
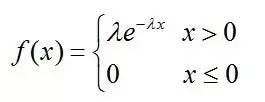
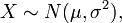
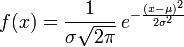
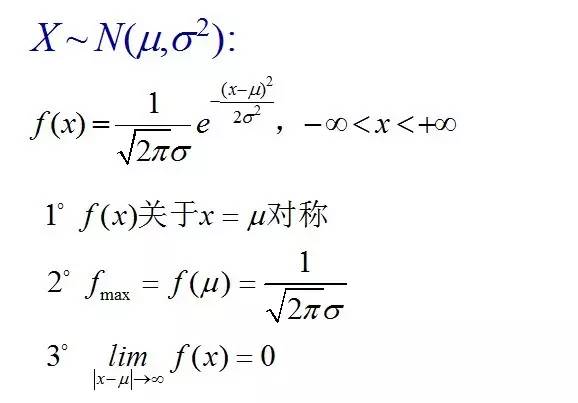
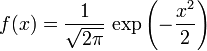
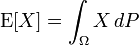
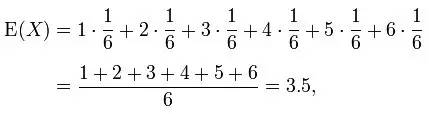

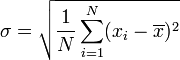
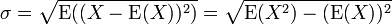

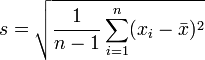

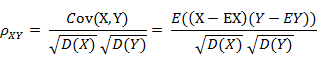
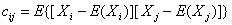
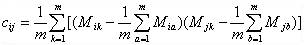
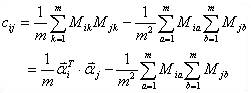
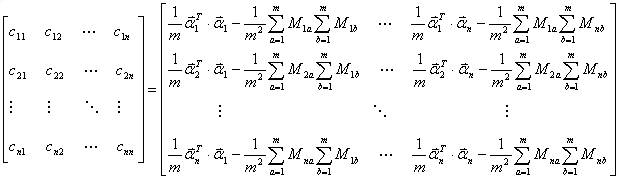
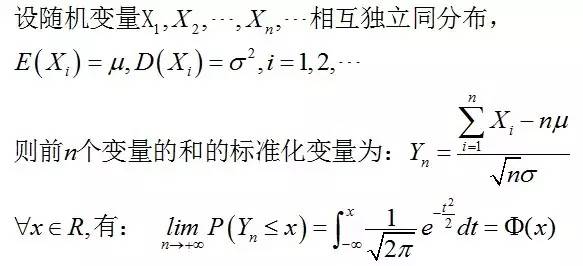

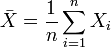 ,
,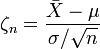 ,则
,则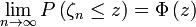 ,其中
,其中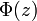 是标准正态分布的分布函数。
是标准正态分布的分布函数。