
项目实战:用户消费行为分析
《分析步骤》
第一部分:数据类型的处理—字段的清洗
缺失值的处理、数据类型的转化
第二部分:按月数据分析
每月的消费总金额、每月的消费次数、每月的产品购买量、每月的消费人数
第三部分:用户个体消费数据分析
用户消费金额和消费次数的描述统计、用户消费金额和消费次数的散点图、用户消费金额的分布图(二八法则)、用户消费次数的分布图
、用户累计消费金额的占比
第四部分:用户消费行为分析
用户第一次消费时间、用户最后一次消费时间、新老客消费比、用户分层、用户购买周期、用户生命周期。
第一部分:数据类型的处理—字段的清洗
导入常用的库
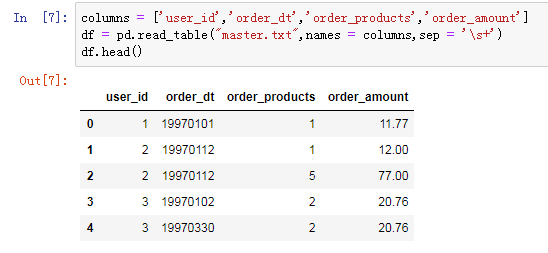
加载包和数据,文件是txt,用read_table方法打开,因为原始数据不包含表头,所以需要赋予。字符串是空格分割,用\s+表示匹配任意空白符。
列字段的含义:
user_id:用户ID
order_dt:购买日期
order_products:购买产品数
order_amount:购买金额
消费行业或者是电商行业一般是通过订单数,订单额,购买日期,用户ID这四个字段来分析的。基本上这四个字段就可以进行很丰富的分析。
观察数据,判断数据是否正常识别。值得注意的是一个用户可能在一天内购买多次,用户ID为2的用户在1月12日买了两次,这个细节不要遗漏。
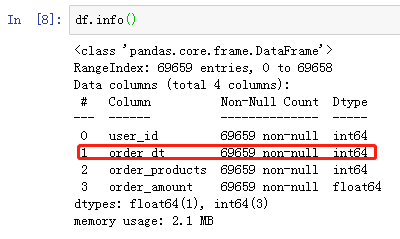
查看数据类型、数据是否存在空值;原数据没有空值,很干净的数据。接下来我们要将时间的数据类型转化。
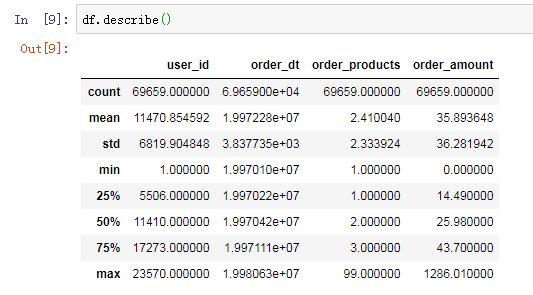
用户平均每笔订单购买2.4个商品,标准差在2.3,稍稍具有波动性。中位数在2个商品,75分位数在3个商品,说明绝大部分订单的购买量都不多。最大值在99个,数字比较高。购买金额的情况差不多,大部分订单都集中在小额。
一般而言,消费类的数据分布,都是长尾形态。大部分用户都是小额,然而小部分用户贡献了收入的大头,俗称二八。
数据类型的转化
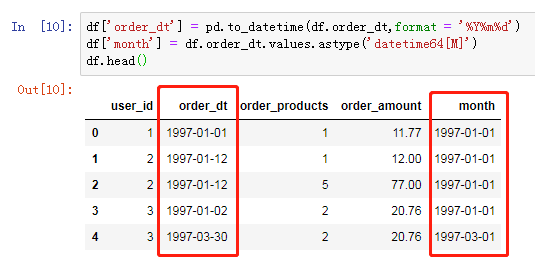
到目前为止,我们已经把数据类型处理成我们想要的类型了。我们通过四个字段及衍生字段就可以进行后续的分析了。
第二部分:按月数据分析
接下来我们用之前清洗好的字段进行数据分析。从用户方向、订单方向、消费趋势等进行分析。
1、消费趋势的分析
-
每月的消费总金额
-
每月的消费次数
-
每月的产品购买量
-
每月的消费人数
目的:了解这批数据的波动形式。
用groupby创建一个新的对象。这里要观察消费总金额,需要将order_amount求和
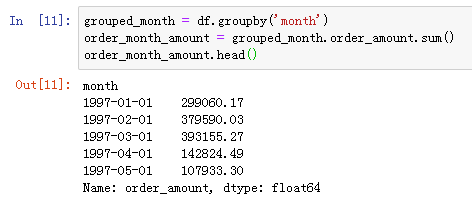
按月统计每个月的CD消费总金额
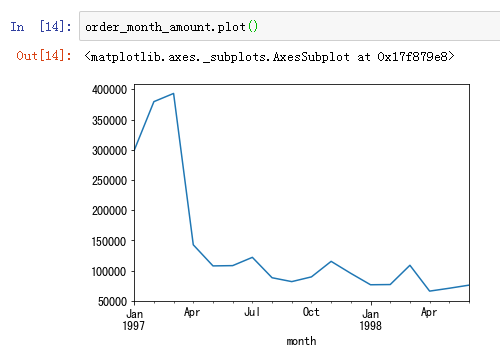
从图中可以看到,前几个月的销量非常高涨。数据比较异常。而后期的销量则很平稳。
每月的消费次数(订单数)
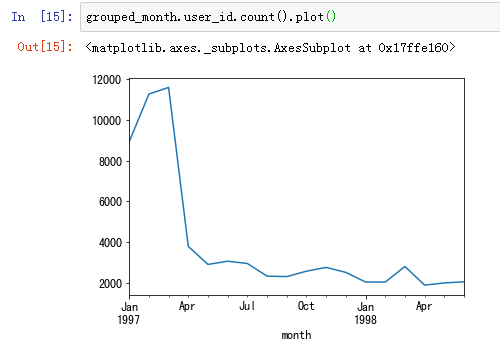
前三个月的消费订单数在10000笔左右,后续月份的消费人数则在2500人左右。
每月的产品购买量
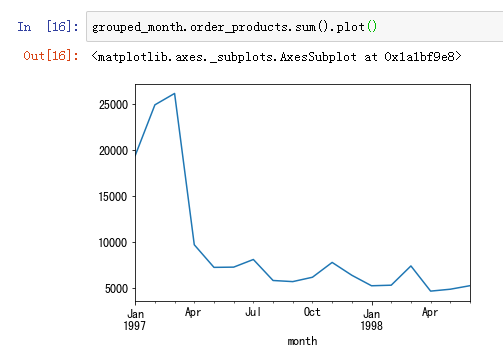
每月的产品购买量一样呈现早期购买量多,后期平稳下降的趋势。
为什么会呈现这个原因呢?
我们假设是用户身上出了问题,早期时间段的用户中有异常值,第二假设是各类促销营销,但这里只有消费数据,所以无法判断。
每月的消费人数(去重)
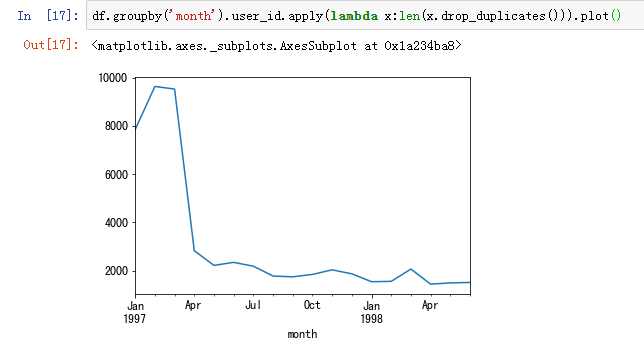
每月的消费人数小于每月的消费次数,但是区别不大。前三个月每月的消费人数在8000—10000之间,后续月份,平均消费人数在2000不到。一样是前期消费人数多,后期平稳下降的趋势。
第三部分:用户个体消费数据分析
之前我们维度都是月,来看的是趋势。有时候我们也需要看个体来看这个人的消费能力如何,这里划分了五个方向如下:
-
用户消费金额和消费次数的描述统计
-
用户消费金额和消费次数的散点图
-
用户消费金额的分布图(二八法则)
用户消费金额和消费次数的描述统计
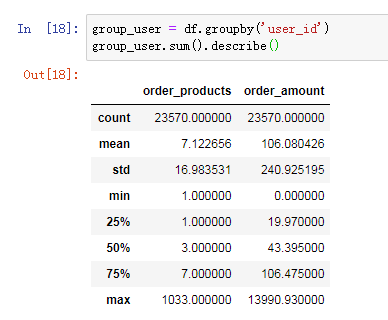
从用户角度看,每位用户平均购买7张CD,最多的用户购买了1033张。用户的平均消费金额(客单价)100元,标准差是240,结合分位数和最大值看,平均值才和75分位接近,肯定存在小部分的高额消费用户。
用户消费金额和消费次数的散点图
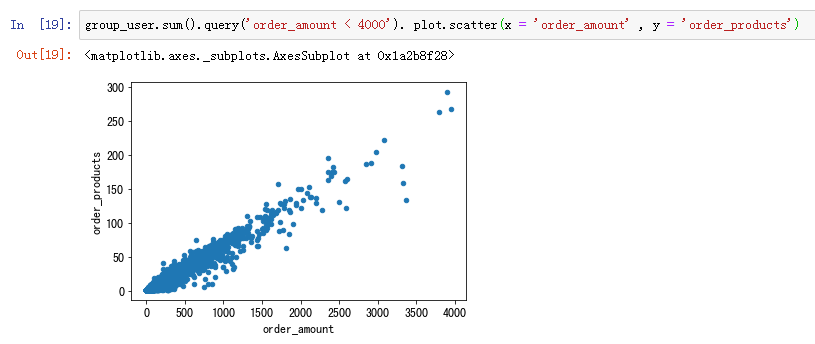
绘制用户的散点图,用户比较健康而且规律性很强。因为这是CD网站的销售数据,商品比较单一,金额和商品量的关系也因此呈线性,没几个离群点。
用户消费金额的分布图(二八法则)
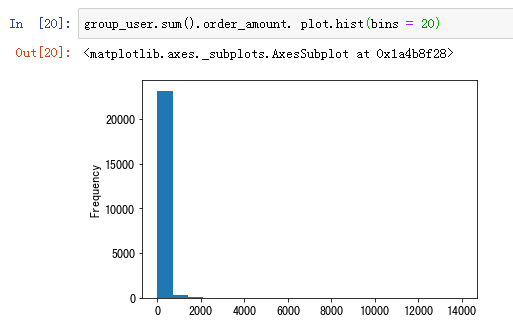
从上图直方图可知,大部分用户的消费能力确实不高,绝大部分呈现集中在很低的消费档次。高消费用户在图上几乎看不到,这也确实符合消费行为的行业规律。
到目前为止关于用户的消费行为有一个大概的了解
第四部分:用户消费行为分析
- 用户第一次消费(首购)。
- 用户最后一次消费
- 新老客消费比
- 多少用户仅消费了一次
- 每月新客占比
- 用户分层
- RFM
- 新、老、活跃、流失
- 用户购买周期(按订单)
- 用户消费周期描述
- 用户消费周期分布
用户第一次消费(首购)
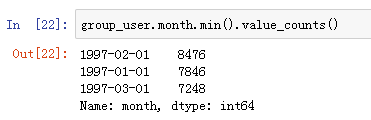
求月份的最小值,即用户消费行为中的第一次消费时间。所有用户的第一次消费都集中在前三个月.
用户最后一次消费

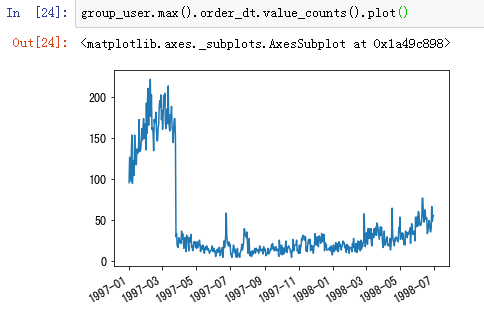
观察用户的最后一次消费时间。用户最后一次消费比第一次消费分布广,大部分最后一次消费集中在前三个月,说明很多客户购买一次就不再进行购买。随着时间的增长,最后一次购买数也在递增,消费呈现流失上升的情况,用户忠诚度在慢慢下降。
新老客的消费比
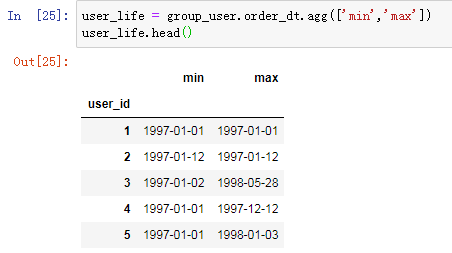
user_id为1的用户第一次消费时间和最后一次消费时间为19970101,说明他只消费了一次
用户购买周期
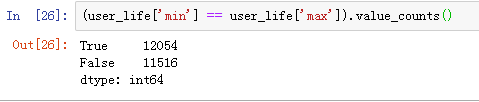
有一半的用户只消费了一次
用户分层
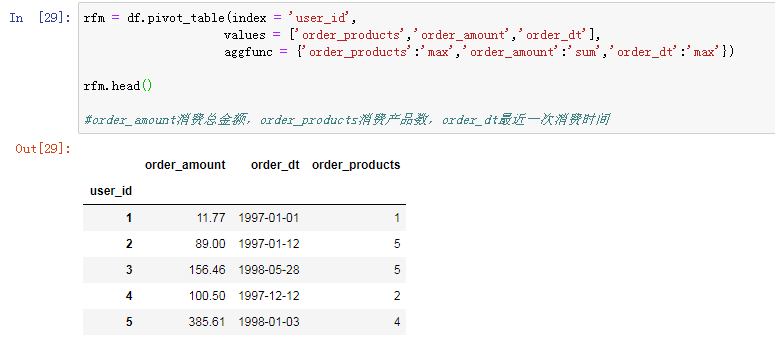
order_products求的是消费产品数,把它替换成消费次数也是可以,但是因为我们这里消费次数是比较固定的,所以使用消费产品数的维度。
RFM距今天数
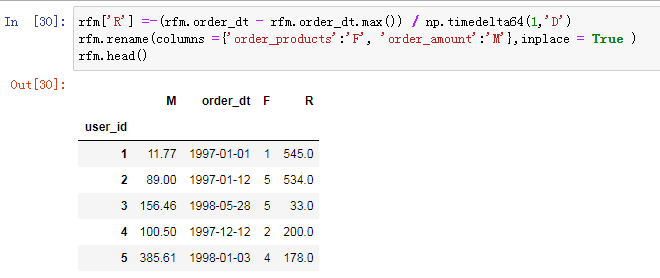
R表示客户最近一次交易时间的间隔,客户在最近一段时间内交易的金额。F表示客户在最近一段时间内交易的次数,F值越大,表示客户交易越频繁,反之则表示客户交易不够活跃。M表示客户在最近一段时间内交易的金额。M值越大,表示客户价值越高,反之则表示客户价值越低。
用户分层:RFM
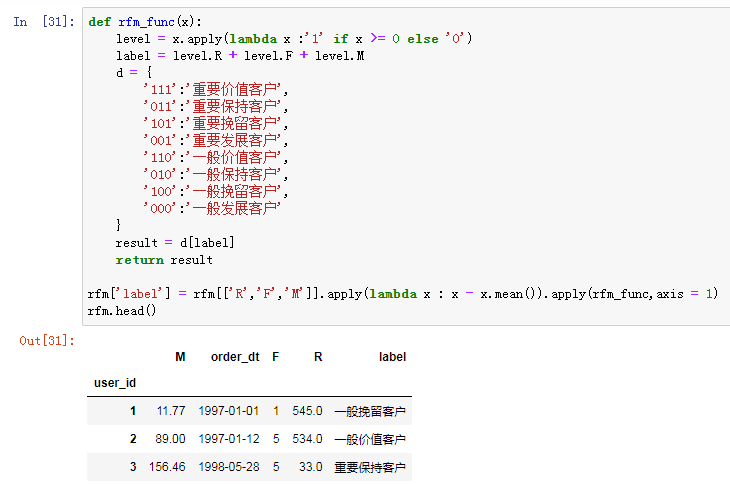
用户分层,这里使用平均数
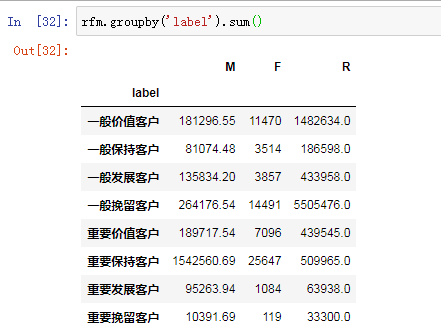
M不同层次客户的消费累计金额,重要保持客户的累计消费金额最高
用户分层:计数
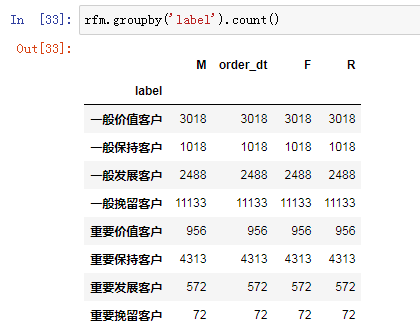
不同层次用户的消费人数,之前重要保持客户的累计消费金额最高,这里重要保持客户的消费人数排名第二,但离一般挽留用户差距比较大,一般挽留用户有14074人,重要保持客户4554人
RFM用户分层
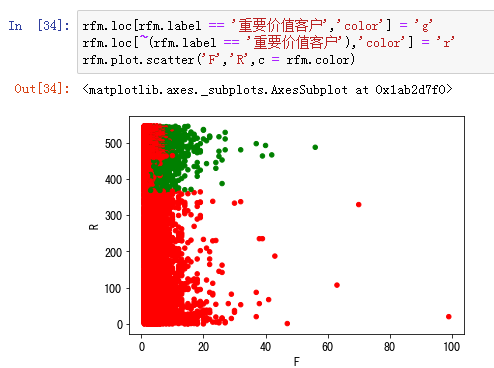
从RFM分层可知,大部分用户为重要保持客户,但是这是由于极致的影响,所以RFM的划分应该尽量以业务为准。尽量用小部分的用户覆盖大部分的额度,不要为了数据好看划分等级。
RFM是人工使用象限法把数据划分为几个立方体,立方体对应相应的标签,我们可以把标签运用到业务层面上。比如重要保持客户贡献金额最多159203.62,我们如何与业务方配合把数据提高或者维护;而重要发展客户和重要挽留客户他们有一段时间没有消费了,我们如何把他们拉回来.