
爬虫返回的Json数据怎么玩?一篇文章搞定!

1、Json是什么
JSON,全称为JavaScript Object Notation
JSON是轻量级的文本数据存储和交换格式,独立于语言。(JSON使用JavaScript语法来描述数据对象,但是JSON仍然独立于语言和平台,JSON解析器和JSON库支持许多不同的编程语言)
下面来看看Json数据到底长啥样?
2、Json长啥样
打开浏览器,输入如下网址:“https://www.douban.com/j/search_photo?q=宋智孝”
你要问为啥是“宋智孝”,那你自己猜吧。
我们可以看到很清爽的 JSON 格式对象(是不是很像Python中的“字典”)
展示的形式是这样的:
{
"images": [
{
"src": "https://img1.doubanio.com/view/photo/photo/public/p2185662697.webp",
"author": "蹦咕噜霸会念经",
"url": "https://www.douban.com/link2/?url=http%3A%2F%2Fwww.douban.com%2Fphotos%2Fphoto%2F2185662697%2F&query=%E5%AE%8B%E6%99%BA%E5%AD%9D&cat_id=1025&type=search",
"id": "2185662697",
"title": "有一种美叫做宋智孝",
"width": 381,
"height": 500
},
{
"src": "https://img1.doubanio.com/view/photo/photo/public/p2185662777.webp",
"author": "蹦咕噜霸会念经",
"url": "https://www.douban.com/link2/?url=http%3A%2F%2Fwww.douban.com%2Fphotos%2Fphoto%2F2185662777%2F&query=%E5%AE%8B%E6%99%BA%E5%AD%9D&cat_id=1025&type=search",
"id": "2185662777",
"title": "有一种美叫做宋智孝",
"width": 452,
"height": 600
}
],
"total": 2658,
"limit": 20,
"more": true
}
数据被放到了 images 对象里,它是个数组的结构,每个数组的元素是个字典的类型。
src、author、url、id、title、width 和height 这些字段代表的含义分别是原图片的地址、作者、发布地址、图片 ID、标题、图片宽度、图片高度等信息。
json的格式本来就很清爽了,那我要想更加“清爽”的查看数据之间的层级关系,该怎么办呢?
这时候就需要用到一个插(shen)件(qi)了。
JSON-handle(如图)
解析之后的数据长这样:
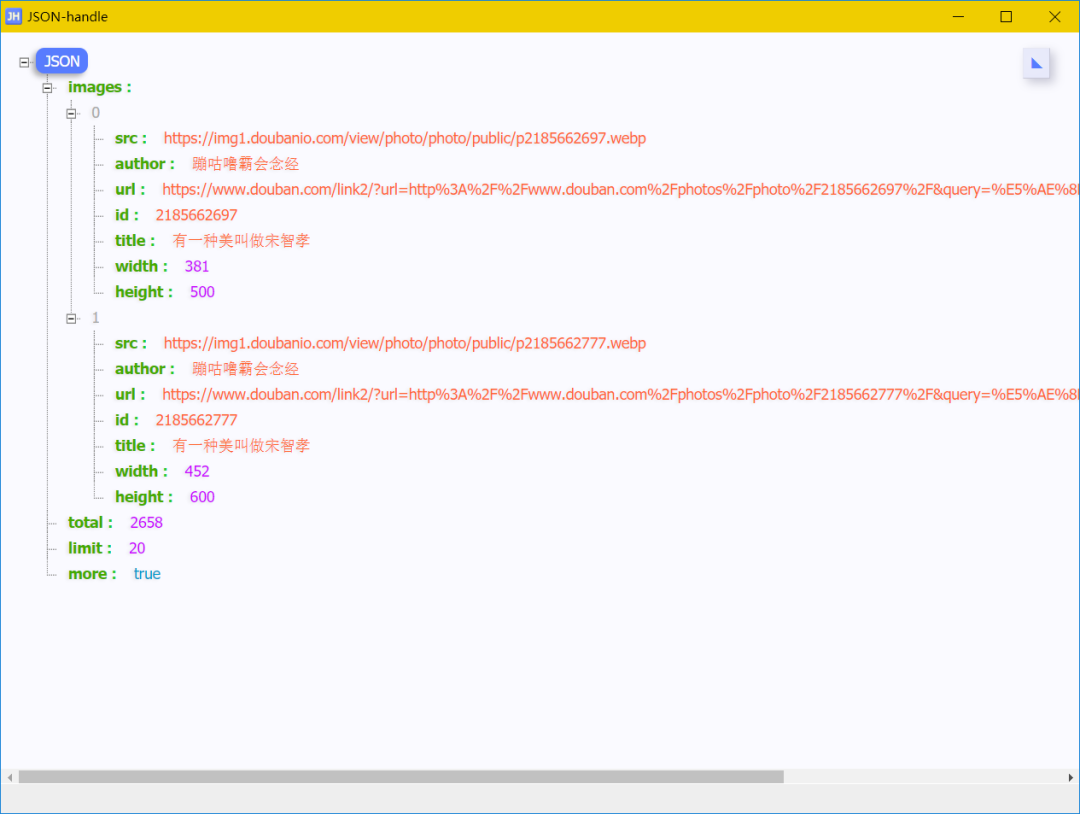
嗯,更清爽了!
3、在Python中玩转Json
在 Python 中有 JSON 库,可以让我们将 Python 对象和 JSON 对象进行转换,便于数据的解析。
在Json库里有两个方法:
json.dumps() 将Python对象(字符串)转换成为Json对象(字典)
json.loads() 将Json对象转换成为Python对象
下面这段代码中,通过loads()函数把data从“json string”转化为“dict”;又通过dumps()函数把data从“dict”转化为“json string”(折腾来、折腾去)
说白了就是一个“ 双引号”的问题,把双引号干掉,就是“dict”,放在python中就可以轻松的取到想要的节点数据。
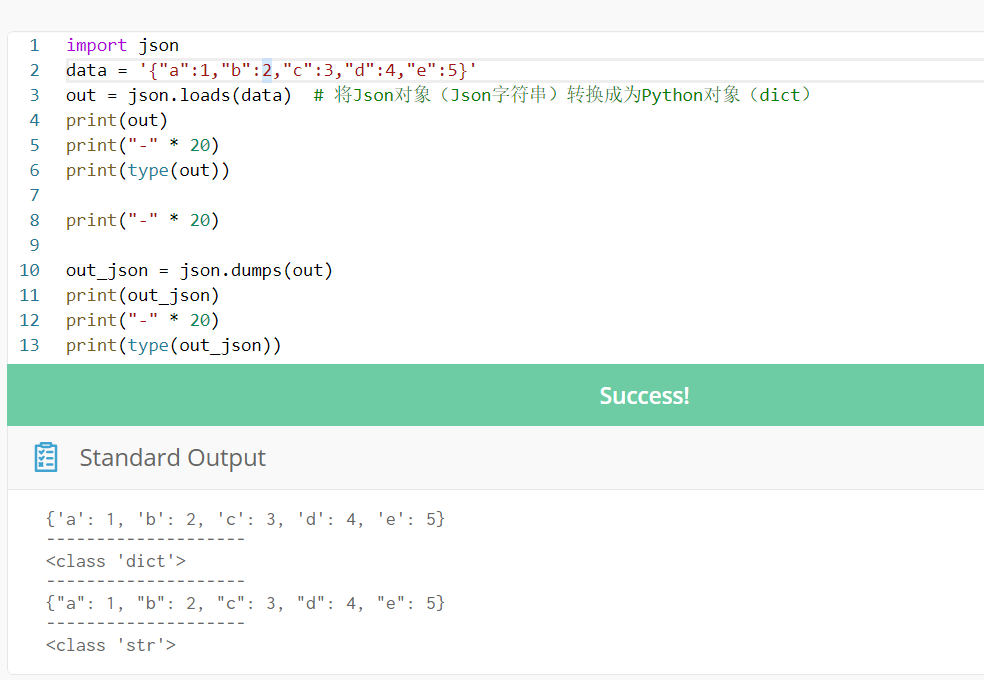
代码可通过网址查看:
https://tech.io/snippet/JqONpVh
4、实战演练
打开浏览器,输入如下网址:“https://www.douban.com/j/search_photo?q=宋智孝”,获得的src字段为图片的url地址。
我们要做的是把作者、原地址、标题保存为DataFrame,并存储为csv文件,然后根据图片的原地址把关于“宋智孝”的图片全部下载下来。
数据保存的代码:
利用request模块获取API的数据(记得加上headers,模拟浏览器的操作),然后把每一份数据存在“字典”里,再追加到“列表”中。
利用 pandas模块,把数据转为DataFrame,在保存为csv文件(注意中文乱码的问题)
import requests
import pandas as pd
query = '宋智孝'
headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36"}
url = 'https://www.douban.com/j/search_photo?q=' + query
response = requests.get(url, headers=headers).json() # 得到返回结果
# print(response)
result = []
for image in response['images']:
dict = {}
dict["pic"] = image["src"]
dict["author"] = image["author"]
dict["title"] = image["title"]
result.append(dict)
print(image['src']) # 查看当前下载的图片网址
download(image['src'], image['id']) # 下载一张图片
result_pd = pd.DataFrame(result)
result_pd.to_csv("result_pd.csv",encoding='utf_8_sig')下载图片的代码:
根据图片的URL地址,把图片下载到.py文件的同级目录,命名为“str(i).jpg”
def download(src, id):
dir = './' + str(id) + '.jpg'
try:
pic = requests.get(src, headers=headers, timeout=10)
# print(pic)
with open(dir, "wb") as f:
f.write(pic.content)
except requests.exceptions.ConnectionError:
print('图片无法下载')
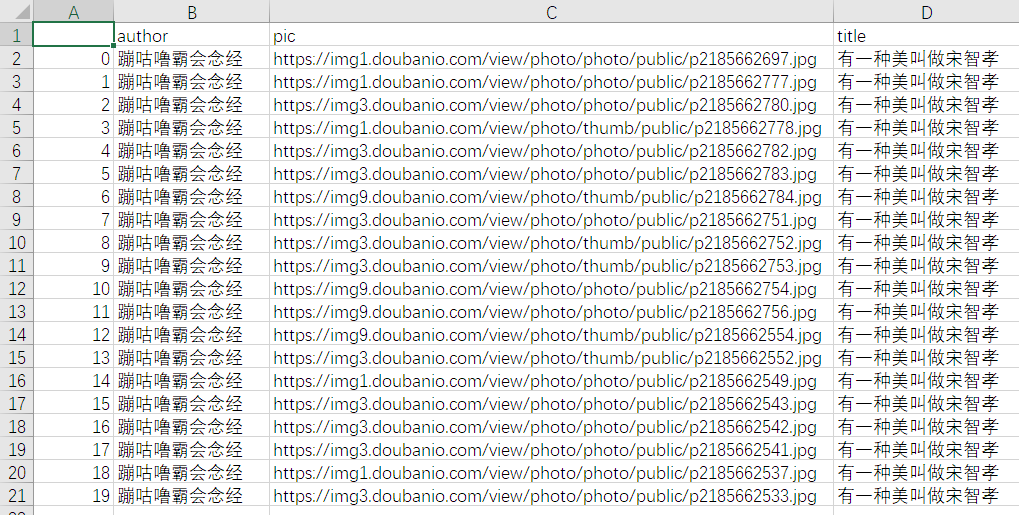
运行结果:
5、我是小结
JSON是轻量级的文本数据存储和交换格式,独立于语言,可以使用Json Handle插件来“一目了然”地查看Json数据的层级关系。
利用Json扩展库,可以方便的把json数据转为python数据类型,通过一个批量下载图片的案例,介绍了Request库与json数据的访问。
希望这篇文章能帮助你在Python中更好地玩转Json数据。