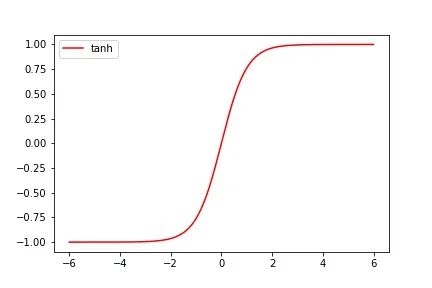
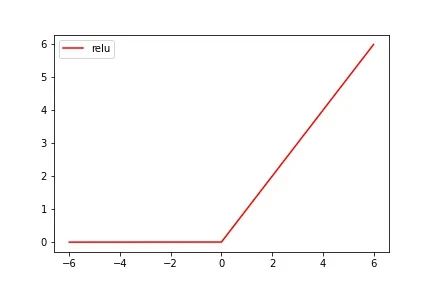
图像很容易理解,若输入的 x 值小于0,则输出为也为0;若输入的 x 值大于0,则直接输出 x 值,需要注意的是ReLu函数在x = 0 处不连续(不可导),但同样也可以作为激活函数。与Sigmoid函数和Tanh函数相比,ReLu函数一个很明显的优点就是在应用梯度下降法是收敛较快,当输入值为整数时,不会出现梯度饱和的问题,因为大于0的部分是一个线性关系,这个优点让ReLu成为目前应用较广的激活函数。ReLu函数的代码如下:
import numpy as np defrelu(x): return np.maximum(0,x)
SoftMax函数
分类问题可以分为二分类问题和多分类问题,Sigmoid函数比较适合二分类问题,而SoftMax函数更加适合多分类问题。SoftMax函数的数学表达式为:其中表示分类器的输出,i表示类别索引,总的类别个数为C,表示当前元素的指数与所有元素指数和的比值。概括来说,SoftMax函数将多分类的输出值按比例转化为相对概率,使输出更容易理解和比较。为了防止SoftMax函数计算时出现上溢出或者下溢出的问题,通常会提前对 V 做一些数值处理,即每个 V 减去 V 中的最大值,假设,SoftMax函数数学表达式更改为:因为SoftMax函数计算的是概率,所以无法用图像进行展示,SoftMax函数的代码如下:
import numpy as np defsoftmax(x): D = np.max(x) exp_x = np.exp(x-D) return exp_x / np.sum(exp_x)