
稀疏索引与其在Kafka和ClickHouse中的应用
点击上方蓝色字体,选择“设为星标”




Sparse Index
在以数据库为代表的存储系统中,索引(index)是一种附加于原始数据之上的数据结构,能够通过减少磁盘访问来提升查询速度,与现实中的书籍目录异曲同工。索引通常包含两部分,即索引键(≈章节)与指向原始数据的指针(≈页码),如下图所示。
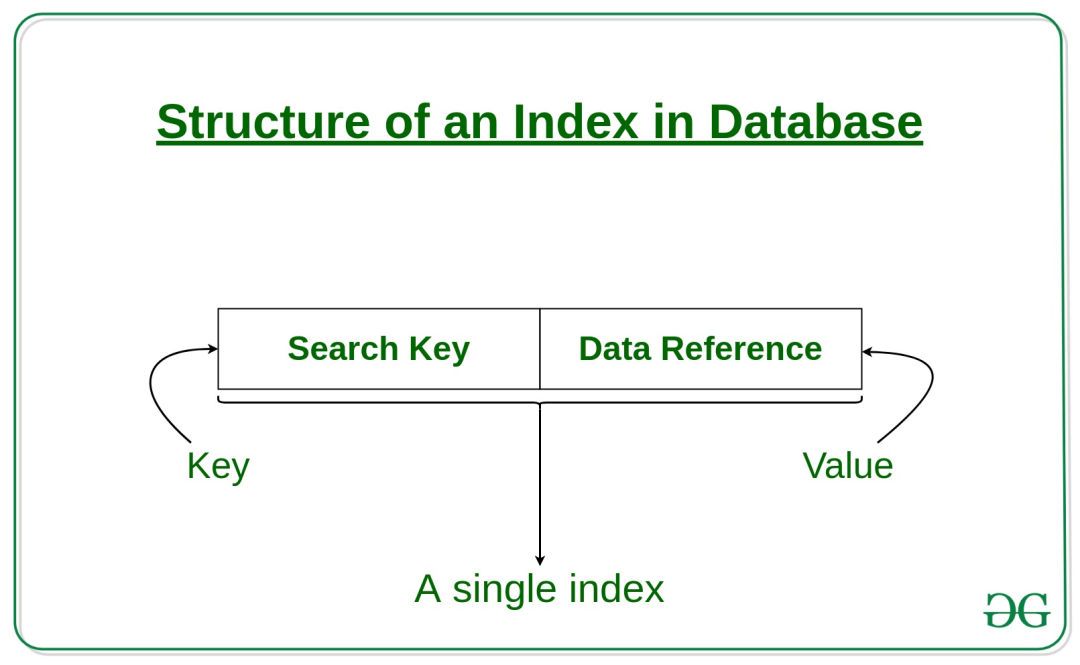 https://www.geeksforgeeks.org/indexing-in-databases-set-1/
https://www.geeksforgeeks.org/indexing-in-databases-set-1/
索引的组织形式多种多样,本文要介绍的稀疏索引(sparse index)是一种简单而常用的有序索引形式——即在数据主键有序的基础上,只为部分(通常是较少一部分)原始数据建立索引,从而在查询时能够圈定出大致的范围,再在范围内利用适当的查找算法找到目标数据。如下图所示,为3条原始数据建立了稀疏索引。
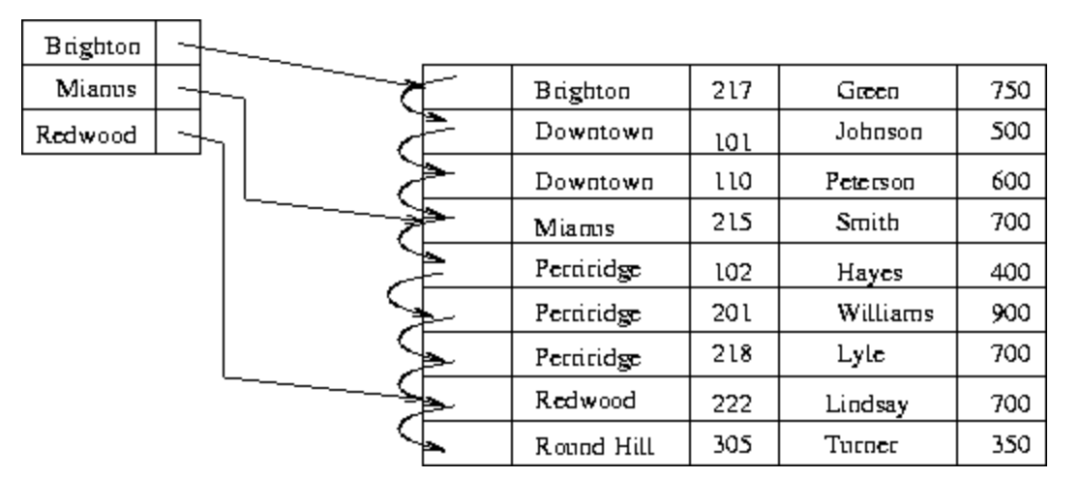 https://www2.cs.sfu.ca/CourseCentral/354/zaiane/material/notes/Chapter11/node5.html
https://www2.cs.sfu.ca/CourseCentral/354/zaiane/material/notes/Chapter11/node5.html
相对地,如果为所有原始数据建立索引,就称为稠密索引(dense index),如下图。
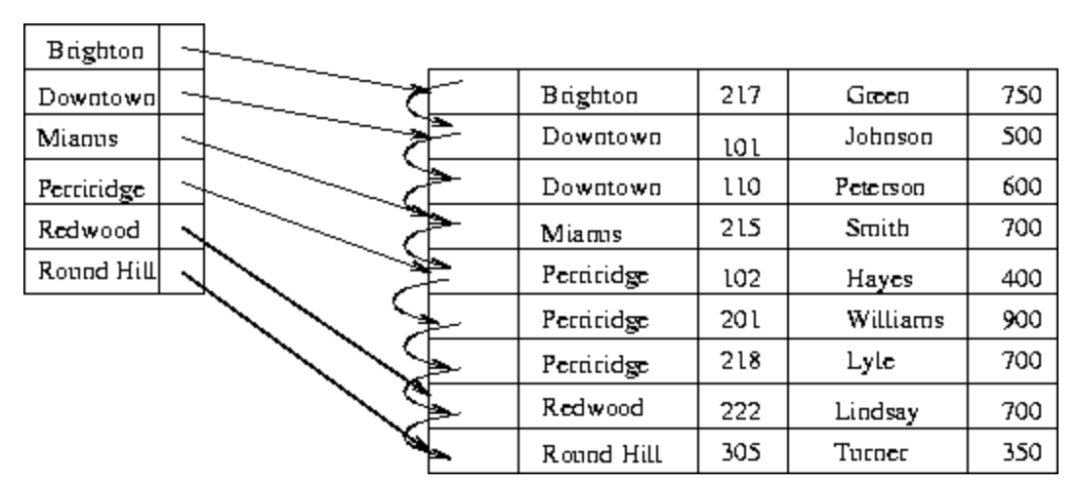
稠密索引和稀疏索引其实就是空间和时间的trade-off。在数据量巨大时,为每条数据都建立索引也会耗费大量空间,所以稀疏索引在特定场景非常好用。以下举两个例子。
Sparse Index in Kafka
我们知道,单个Kafka的TopicPartition中,消息数据会被切分成段(segment)来存储,扩展名为.log。log文件的切分时机由大小参数log.segment.bytes(默认值1G)和时间参数log.roll.hours(默认值7天)共同决定。数据目录中存储的部分文件如下。
.
├── 00000000000190089251.index
├── 00000000000190089251.log
├── 00000000000190089251.timeindex
├── 00000000000191671269.index
├── 00000000000191671269.log
├── 00000000000191671269.timeindex
├── 00000000000193246592.index
├── 00000000000193246592.log
├── 00000000000193246592.timeindex
├── 00000000000194821538.index
├── 00000000000194821538.log
├── 00000000000194821538.timeindex
├── 00000000000196397456.index
├── 00000000000196397456.log
├── 00000000000196397456.timeindex
├── 00000000000197971543.index
├── 00000000000197971543.log
├── 00000000000197971543.timeindex
......
log文件的文件名都是64位整形,表示这个log文件内存储的第一条消息的offset值减去1(也就是上一个log文件最后一条消息的offset值)。每个log文件都会配备两个索引文件——index和timeindex,分别对应偏移量索引和时间戳索引,且均为稀疏索引。
可以通过Kafka提供的DumpLogSegments小工具来查看索引文件中的信息。
~ kafka-run-class kafka.tools.DumpLogSegments --files /data4/kafka/data/ods_analytics_access_log-3/00000000000197971543.index
Dumping /data4/kafka/data/ods_analytics_access_log-3/00000000000197971543.index
offset: 197971551 position: 5207
offset: 197971558 position: 9927
offset: 197971565 position: 14624
offset: 197971572 position: 19338
offset: 197971578 position: 23509
offset: 197971585 position: 28392
offset: 197971592 position: 33174
offset: 197971599 position: 38036
offset: 197971606 position: 42732
......
~ kafka-run-class kafka.tools.DumpLogSegments --files /data4/kafka/data/ods_analytics_access_log-3/00000000000197971543.timeindex
Dumping /data4/kafka/data/ods_analytics_access_log-3/00000000000197971543.timeindex
timestamp: 1593230317565 offset: 197971551
timestamp: 1593230317642 offset: 197971558
timestamp: 1593230317979 offset: 197971564
timestamp: 1593230318346 offset: 197971572
timestamp: 1593230318558 offset: 197971578
timestamp: 1593230318579 offset: 197971582
timestamp: 1593230318765 offset: 197971592
timestamp: 1593230319117 offset: 197971599
timestamp: 1593230319442 offset: 197971606
......
可见,index文件中存储的是offset值与对应数据在log文件中存储位置的映射,而timeindex文件中存储的是时间戳与对应数据offset值的映射。有了它们,就可以快速地通过offset值或时间戳定位到消息的具体位置了。并且由于索引文件的size都不大,因此很容易将它们做内存映射(mmap),存取效率很高。
以index文件为例,如果我们想要找到offset=197971577的消息,流程是:
通过二分查找,在index文件序列中,找到包含该offset的文件(00000000000197971543.index);
通过二分查找,在上一步定位到的index文件中,找到该offset所在区间的起点(197971592);
从上一步的起点开始顺序查找,直到找到目标offset。
最后,稀疏索引的粒度由log.index.interval.bytes参数来决定,默认为4KB,即每隔log文件中4KB的数据量生成一条索引数据。调大这个参数会使得索引更加稀疏,反之则会更稠密。
Sparse Index in ClickHouse
在ClickHouse中,MergeTree引擎表的索引列在建表时使用ORDER BY语法来指定。而在官方文档中,用了下面一幅图来说明。

这张图示出了以CounterID、Date两列为索引列的情况,即先以CounterID为主要关键字排序,再以Date为次要关键字排序,最后用两列的组合作为索引键。marks与mark numbers就是索引标记,且marks之间的间隔就由建表时的索引粒度参数index_granularity来指定,默认值为8192。
ClickHouse MergeTree引擎表中,每个part的数据大致以下面的结构存储。
.
├── business_area_id.bin
├── business_area_id.mrk2
├── coupon_money.bin
├── coupon_money.mrk2
├── groupon_id.bin
├── groupon_id.mrk2
├── is_new_order.bin
├── is_new_order.mrk2
......
├── primary.idx
......
其中,bin文件存储的是每一列的原始数据(可能被压缩存储),mrk2文件存储的是图中的mark numbers与bin文件中数据位置的映射关系。另外,还有一个primary.idx文件存储被索引列的具体数据。另外,每个part的数据都存储在单独的目录中,目录名形如20200708_92_121_7,即包含了分区键、起始mark number和结束mark number,方便定位。
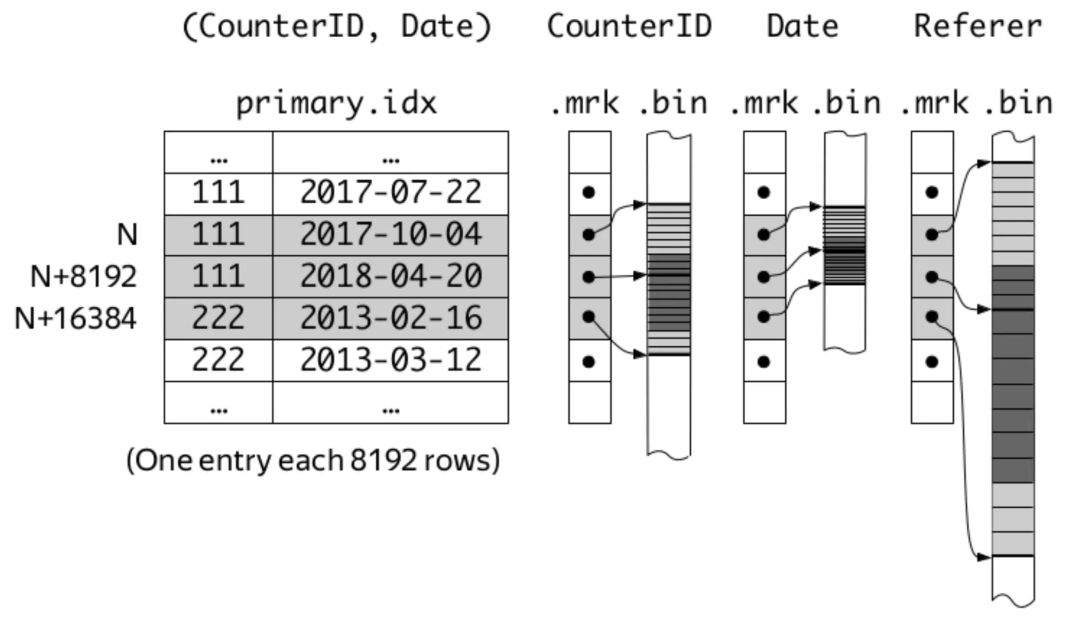
这样,每一列都通过ORDER BY列进行了索引。查询时,先查找到数据所在的parts,再通过mrk2文件确定bin文件中数据的范围即可。
不过,ClickHouse的稀疏索引与Kafka的稀疏索引不同,可以由用户自由组合多列,因此也要格外注意不要加入太多索引列,防止索引数据过于稀疏,增大存储和查找成本。另外,基数太小(即区分度太低)的列不适合做索引列,因为很可能横跨多个mark的值仍然相同,没有索引的意义了。


版权声明:
文章不错?点个【在看】吧! ?