
何为SourceMap?讲讲SourceMap食用姿势
大厂技术 坚持周更 精选好文
做好事不留名的 sourcemap
当我们在开发代码的时候,遇到错误的时候可以在控制台定位到具体的问题,就像这样: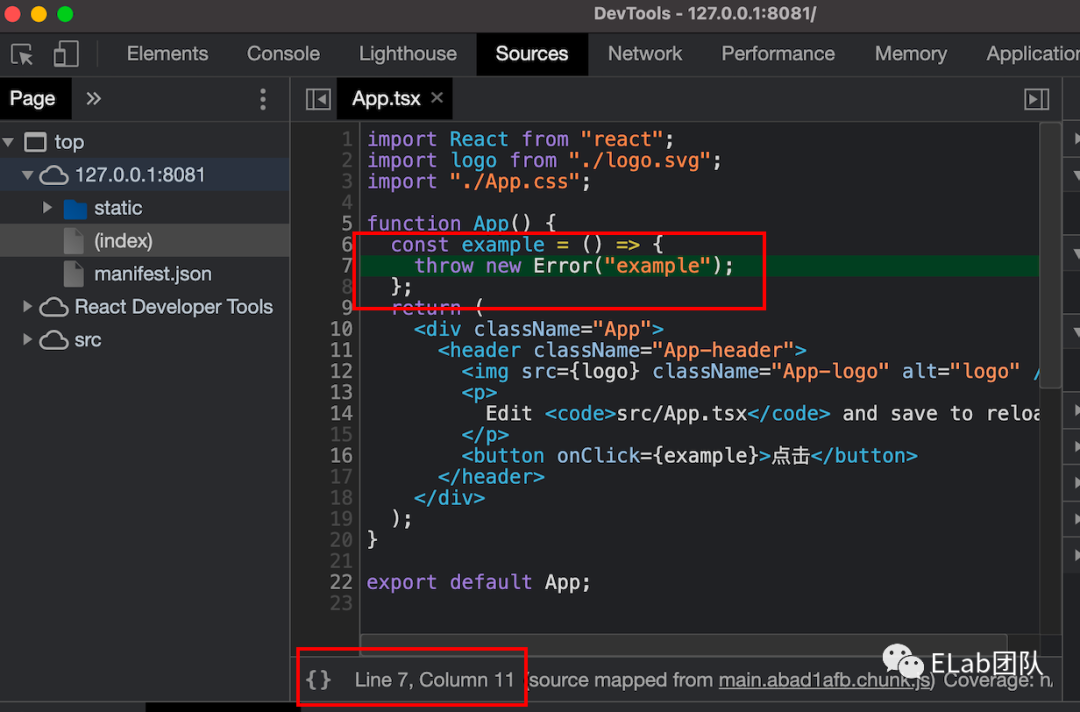 问题在于,由于打包动作会将我们的原始代码进行编译、压缩,最后在产物中早已没有我们的原始代码,打开产物,我们可以见到的只有这样的代码:
问题在于,由于打包动作会将我们的原始代码进行编译、压缩,最后在产物中早已没有我们的原始代码,打开产物,我们可以见到的只有这样的代码: 既然如此,为什么我们可以通过控制台,在原始代码中定位到错误位置呢?答案就是本文的主角:source map。在前端工程体系中,一份代码从开发到上线,大多需要经过打包编译的步骤,为的是:
既然如此,为什么我们可以通过控制台,在原始代码中定位到错误位置呢?答案就是本文的主角:source map。在前端工程体系中,一份代码从开发到上线,大多需要经过打包编译的步骤,为的是:
将 jsx, tsx, ts 之类的文件类型转译成 runtime 可以识别的 js 将 js 转译成适用范围更广的 es5 将多个 js 文件压缩成一个最终的产物,并对代码进行一定程度的混淆
经过以上三个步骤,我们的代码已经变得面目全非。原始信息的丢失不利于对代码进行追踪,如果此时遇到错误,压缩过后的代码会让我们无从下手。但是,如果我们的打包产物中有这样的文件,我们便能利用这些文件还原出原始代码: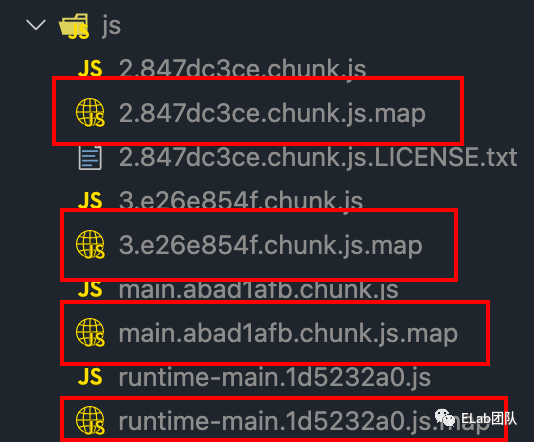 这些就是 sourcemap,那么 sourcemap 是怎么生成的?我们应该怎么使用 sourcemap?
这些就是 sourcemap,那么 sourcemap 是怎么生成的?我们应该怎么使用 sourcemap?
sourcemap 原理
sourcemap 的构成
为了更清晰的描述 sourcemap 的生成,我用一个最简单的 case 来编译并生成 sourcemap:
// input
const example = () => {
console.log('example');
}
// output
"use strict";
var example = function example(){
console.log("example");
};
利用 babel 将上述代码转为 es5 的同时,我们可以得到一份 sourcemap:
{
"version": 3,
"sources": [
"src/example.js"
],
"names": [
"example",
"console",
"log"
],
"mappings": ";;AAAA,IAAMA,OAAO,GAAG,SAAVA,OAAU,GAAM;AACpBC,EAAAA,OAAO,CAACC,GAAR,CAAY,SAAZ;AACD,CAFD",
"sourcesContent": [
"const example = () => {\n console.log(\"example\");\n};\n"
]
}
可以看到其有多个属性,分别代表着:
version: source map 的版本号。 sources: 转换前的文件。该项是一个数组,可能存在多个文件合并成一个文件。 names: 转换前的所有变量名和属性名。 mappings: 记录位置信息的字符串。 sourceContent: 原始内容。
其中最重要的,便是记录着原始代码和编译后代码映射关系的 mappings 字段。
mappings 是如何记录映射的
可以花两分钟简单思考一下,如果是你来设计 sourcemap,你会如何记录一份原始代码到编译后代码的映射?很简单,我将编译后的每一个单词,对应的原始位置都记录下来就可以了,需要注意的是,由于存在多个文件编译成一个文件的情况,所以我们需要记录下原始文件名:
| 编译后的位置(行/列) | 编译后单词 | 原始文件名 | 原始位置(行/列) | 原始单词 |
|---|---|---|---|---|
| 0, 0 | var | src/example.js | 0, 0 | const |
| 0, 4 | example | src/example.js | 0, 6 | example |
| 0, 11 | = | src/example.js | 0, 13 | = |
| 0, 14 | function | src/example.js | 0, 16 | ( |
| 0, 23 | example | src/example.js | 0, 6 | example |
| 0, 30 | ( | src/example.js | 0, 16 | ( |
| 0, 33 | { | src/example.js | 0, 22 | { |
到这里,我们已经将第一行代码的原始信息记录下来了,可以表示为:
0|0|src/example.js|0|0, 0|4|src/example.js|0|6, 0|11|src/example.js|0|13, 0|14|src/example.js|0|16, 0|23|src/example.js|0|16, 0|30|src/example.js|0|16, 0|33|src/example.js|0|22
同样的,第二行代码与第三行代码的映射关系可以用相同的方式记录下来。当我们完成了映射关系的记录后,便需要考虑一个现实问题:只有 23 个字符的原始信息,我们需要用 150 个字符来记录其映射关系。有没有什么办法,可以用更少的字符记录呢?
现在,我们对照 sourcemap 的做法,将上面的信息进行逐层的优化:
优化
省去输出文件中的行号,改用 ; 来标识换行
利用; 来标识换行,我们可以将上述的编码节省为:
0|src/example.js|0|0, 4|src/example.js|0|6, 11|src/example.js|0|13, 14|src/example.js|0|16, 23|src/example.js|0|16, 30|src/example.js|0|16, 33|src/example.js|0|22;
用索引标识变量名
前面我们提到 sourcemap 中的 names 数组,在 sourcemap 中,它会将变量名在 names 数组中的索引也记录下来,所以编码会变成如下:
0|src/example.js|0|0, 4|src/example.js|0|6|0, 11|src/example.js|0|13, 14|src/example.js|0|16, 23|src/example.js|0|16|0, 30|src/example.js|0|16, 33|src/example.js|0|22;
用索引来代替文件名
使用 sources 属性记录下来的原始文件数组,在记录原始信息时用索引代替,如 src/example.js 在 sources 中的索引为 0,所以可以进一步简化为:
0|0|0|0, 4|0|0|6|0, 11|0|0|13, 14|0|0|16, 23|0|0|16|0, 30|0|0|16, 33|0|0|22;
用相对位置来代替绝对位置
当文件内容巨大时,上面精简后的代码也有可能某些数字会随着增加而变得很长,如果一行的位置记录了某个位置,那么根据这一位置进行相对定位是可以到达一行内的任意位置。如:
| 编译后的位置(列) | 编译后单词 | 原始文件名 | 原始位置(行/列) | 原始单词 |
|---|---|---|---|---|
| 0 | var | src/example.js | 0, 0 | const |
| 4(上一个位置+4) | example | src/example.js | 0, 6 | example |
| 7(上一个位置+7) | = | src/example.js | 0, 7 | = |
| 3(上一个位置+10) | function | src/example.js | 0, 3 | ( |
| 9(上一个位置+9) | example | src/example.js | 0, -10 | example |
| 7(上一个位置+7) | ( | src/example.js | 0, 10 | ( |
| 3(上一个位置+3) | { | src/example.js | 0, 6 | { |
所以我们的 mappings 继续被简化为:
0|0|0|0, 4|0|0|6|0, 7|0|0|7, 3|0|0|3, 10|0|10, 9|0|0|-10, 7|0|0|10, 3|0|0|6;
VLQ 编码
如果我们可以想办法去掉每个单词之间的分隔符(在我们的例子中是 | ),我们可以进一步省下大量的字符。当然,限制我们去掉这个分隔符的问题是,我们无法在没有分隔符的帮助下区分 10010 是 10|0|10 还是 100|1|0,但我们可以设计一套方法,让我们能够在去掉分隔符的情况下依然能够正确的分组。sourcemap 使用了这一套方法:
在二进制中,使用 6 个字节比特来记录一个数字,用其中一个字节来标识它是否结束(下方 C),再用一位标识正负(下方 S),剩下还有四位用来表示数值。用这样 6 个字节来表示我们需要的数字。

| 十进制 | 二进制 |
|---|---|
| 4 | 100 |
| 0 | 0 |
| 6 | 110 |
任意数字中,第一组的第一个字节比特就已经明确标明该数字的正负,所以后续字节比特不需要再标识,也就是说,第一组有 4 个字节比特来表示数值,后续每一组都有 5 个字节 比特来表示数值(每组依然有一个字节比特标识是否结束)
我们用上述的简化过的 mappings 的第二项 4|0|0|6|0 为例:
所以它们应该被编码为:
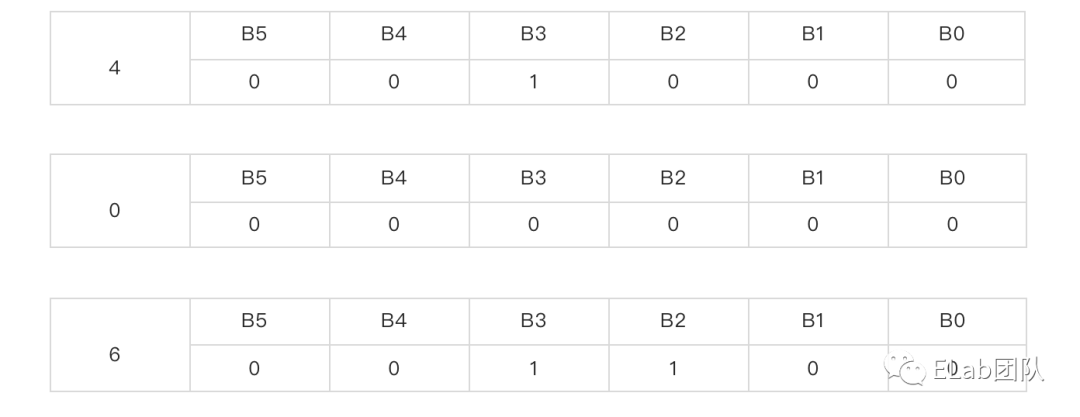
注:如果是一个分组无法表达的数字,则会用第二个分组来容纳剩余部分,这里举个例子:23 的二进制为 10111,由于一个分组无法容纳,那么将 10111 分为两组,第一组是最后面的四位,既 10111,第二组是剩下的 10111,那么它最终会被编码为:101110 000001。
所以 4|0|0|6|0 最终被转化为 001000 000000 000000 001100 000000,随后再进行 base64 编码得到:
001000 000000 000000 001100 000000
I A A M A
之所以要用 6 个字节比特为一组记录一个数字,正是因为每一个 base64 编码最多可以表示二进制 6 位,所以通过这样的编码,我们将 4|0|0|6|0 转化为了 IAAMA。至此,我们便了解了 sourcemap 的原理和生成方式。
webpack 中不同的 sourcemap
我们知道 sourcemap 是用来记录编译后代码到原始代码的映射关系,所以理论上每一个编译过程都可以产生一份 sourcemap,如 TS(X) 转 JS,ES6 转 ES5,代码压缩等等。经过这么多过程,我们需要将每一步生成的 sourcemap 合并起来才能最终得到一份生产环境代码到开发环境代码的 sourcemap。我们可以用社区上现有的轮子手动实现 sourcemap 的合并:https://www.npmjs.com/package/merge-source-map[1]
不过这样还是有一些麻烦,在前段工程体系中,webpack 这类打包工具是不可或缺的,webpack 本身也提供了 sourcemap 的生成,而且不需要我们关注其中 sourcemap 合并的细节。在 webpack 配置中,用 devtool 属性来标识使用何种模式生成 sourcemap。devtool 中有多种类型可以使用,如 eval , inline, cheap...
以这一段程序为例子:
// index.js
import a from "./a";
import b from "./b";
b(a);
// a.js
export default "a";
// b.js
export default (str) => {
throw new Error(str);
};
source-map
该模式会生成一份独立的.map 文件。其和我们前面讲述的一样。它是最详细,同时也是耗时最久的模式。
inline (如 inline-source-map)
该模式不会生成一份独立的.map 文件,而是用 base64 编码将 sourcemap 进行编码后附在编译后代码的末处。缺点是这样会使得编译后代码的体积变得庞大,其他方面则和 source-map 模式一样。
eval
源码以字符的形式被 eval(…) 来调用,不会生成 sourceMap 信息,只会通过一个附着在各个模块后的 sourceURL 来存储原始文件的位置,同时,我们只能在控制台中看到经过 webpack 处理的编译后代码,所以它并不能反映真实的行号: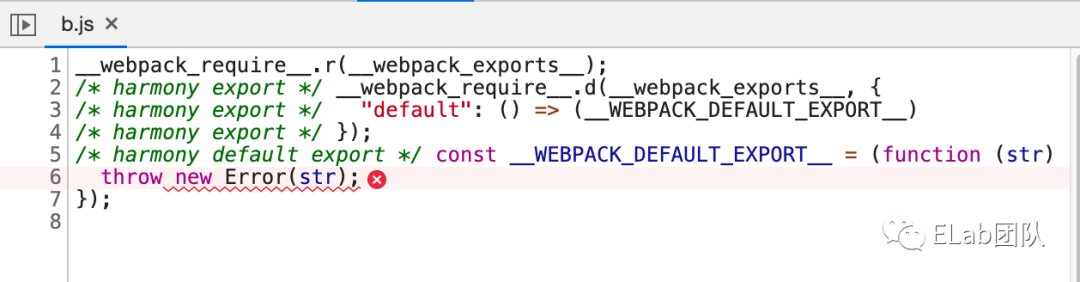
eval-source-map
源码以字符的形式被 eval(…) 来调用,同时生成 sourceMap 信息,sourcemap 信息(以 base64 编码的形式)和 sourceURL 被附着在各个模块后,在这个模式下,我们可以在控制台中看到原始的代码。
cheap-source-map
生成的 sourcemap 只有行信息,不会记录列信息: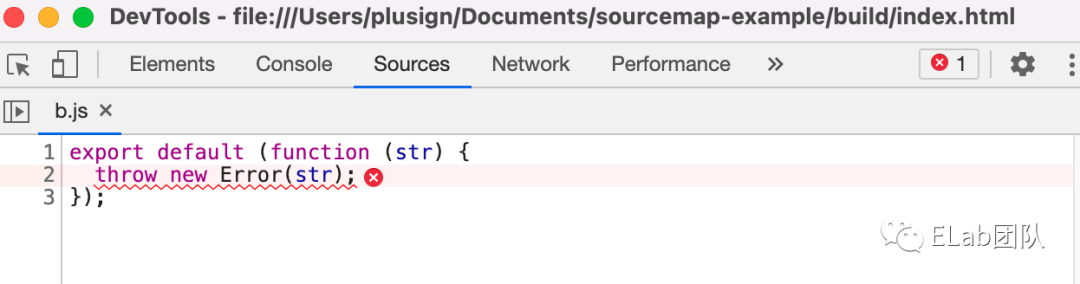 但是,细心的你可能发现了,cheap-source-map 模式下的 sourcemap 依然没有映射到真正的原始代码(原本的箭头函数被 babel 编译成了 function)。cheap-source-map 记录下的是与被 loader(此处是 babel-loader)转化后的代码之间的映射。
但是,细心的你可能发现了,cheap-source-map 模式下的 sourcemap 依然没有映射到真正的原始代码(原本的箭头函数被 babel 编译成了 function)。cheap-source-map 记录下的是与被 loader(此处是 babel-loader)转化后的代码之间的映射。
cheap-module-source-map
使用 cheap-module-source-map 可以记录下 loader 转译前的信息: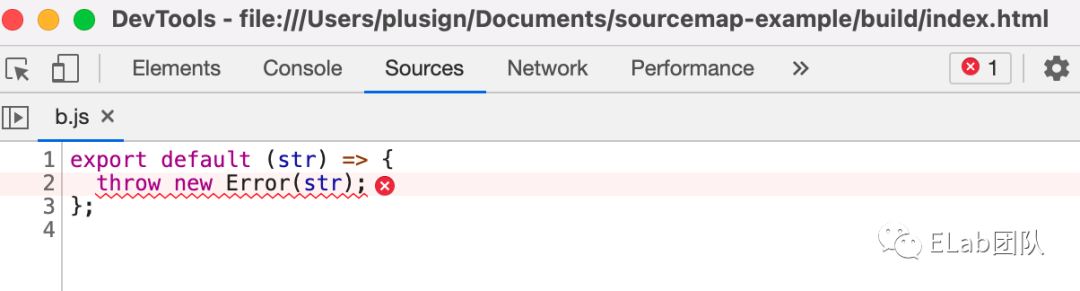
nosources
在这个模式下,会生成不包含 sourcecontent 的 sourcemap,具体表现为有错误堆栈信息但没有具体的内容:

hidden
在这个模式下,会生成 sourcemap,但是不会将 sourcemapURL 信息附着在编译后代码中。此外还有一些模式的组合,具体可以是"^(inline-|hidden-|eval-)?(nosources-)?(cheap-(module-)?)?source-map$"
开发环境应该用哪种模式?生产环境呢?
开发环境下一般使用构建速度快,同时可以看到原始信息的 eval-source-map 模式。而在生产环境下,为了不泄露源代码,可以使用 hidden-source-map 模式。
为什么有时候 sourcemap 表现不准?
一个猜测:上面我们介绍了 webpack 中多种 sourcemap 模式。其中有些模式是以牺牲掉一部分信息来换取更好的构建速度的(如 eval、cheap-source-map)。如果 webpack 的 hot server 没有采用正确的 sourcemap 模式,就会出现定位不准的问题。这个时候通常更换一下 sourcemap 模式为cheap-module-source-map甚至source-map模式就 OK 了。同时,如果打包过程的某个环节在转译代码的时候将原始信息丢失了,也可能会出现最终合并成的 sourcemap 定位不准。
相关链接
D-kylin/note[2] Rich-Harris/vlq[3] 细说 js 压缩、sourcemap、通过 sourcemap 查找原始报错信息[4]
参考资料
https://www.npmjs.com/package/merge-source-map: https://www.npmjs.com/package/merge-source-map
[2]D-kylin/note: https://github.com/D-kylin/note/blob/master/VLQ%E7%BC%96%E7%A0%81.md
[3]Rich-Harris/vlq: https://github.com/Rich-Harris/vlq
[4]细说 js 压缩、sourcemap、通过 sourcemap 查找原始报错信息: https://segmentfault.com/a/1190000016987829
❤️ 谢谢支持
以上便是本次分享的全部内容,希望对你有所帮助^_^
喜欢的话别忘了 分享、点赞、收藏 三连哦~。
欢迎关注公众号 前端Sharing 收货大厂一手好文章~