
10分钟教你用Python打造学生成绩管理系统

代码黑科技的分享区

大家好,这学期上了Python这门课,然后结课的时候老师要求做一个这样的学生管理系统。自己按照老师的要求写了一下,今天就把这个小程序分享出来吧~供Python新手小朋友学习~

其实类似这类信息管理系统之类的程序,核心还是和数据打交道吧,包括增删查改,读取、展示、保存等。
在数据结构上,我依然用了给定的数据结构,即:
score1 = { "姓名":"张三丰",
"学号":"U19990001",
"作业" : [80, 64, 67, 20],
"测验" : [75, 75],
"实验" : [78, 57] ,
"分数" : 0
}
没有增加新的字段比如排名之类的。这样做的主要是考虑到排名、平均成绩等均可以由上述结构中的信息计算出来,而且也可以避免因为一个某个成绩变动,导致一系列的数据需要重新计算。毕竟,数据存储得越多,维护起来的难度就越大,特别是一些关联密切的数据更是如此。
在存储在结构上,我采用了Python中常用的列表作为此程序的“数据库”,因为列表操作起来还是非常方便的。此外,因为这里涉及到一个排名的问题,所以我制定了一个原则:在列表中的所有数据实体都是按照成绩高低进行排序的,即整个存储信息的列表由始至终都是有序的。这样就解决了排名的问题,至于如何实现的,后续我会进行阐述。
运行环境采用的是Windows 10 x64位操作系统+anaconda(Python3.7)+Spyder,默认情况下即可运行,不需要安装其他库。
这一节将介绍一下该程序相应的功能以及相应的代码实现。在此之前先介绍设定的一些规则:
> 计算成绩时取小数点后三位。
> 排名根据[分数、作业平均、测验平均、实验平均]的优先级比较。不存在排名相同的情况。如果这4项指标都相同,emmm应该不会有这么巧的事情。
> 文件保存和读取时,采取CSV格式的数据文件。文件头遵循['序号','姓名','学号','分数','排名','作业1','作业2','作业3','作业4', '测验1', '测验2', '实验1', '实验2']这种格式。
2.0 主界面
整个程序的主界面如下:

在整个程序的交互中,为了更好提高提示信息的辨识度,系统规定了几种颜色:
- 蓝色提示内容表示需要用户输入相关信息。
- 红色表示系统执行指令的结果,比如成功,失败等等。
- 黑色表示系统菜单显示啊,查询结果的输出等。
2.1 添加学生信息
在添加学生信息中,在实现了手动添加信息的基础上,我又增加了从文件中导入信息的功能。不过在添加信息这块,我做了一个约束:添加学生信息时,如果系统中已经存在该学生的学号,则不能重复添加。两种方式都遵循该原则,以保证学号的唯一性。

在添加学生信息时,因为前面说了列表里面的数据需要保持有序性,所以采取了插入排序的方式进行添加,核心的代码如下:
# 根据优先级[分数、作业平均、测验平均、实验平均]比较s1是否优于s2
def cmp_student(s1, s2):
if s1["分数"] != s2["分数"]:
return s1["分数"] > s2["分数"]
else:
if np.mean(s1["作业"]) != np.mean(s2["作业"]):
return np.mean(s1["作业"]) > np.mean(s2["作业"])
else:
if np.mean(s1["测验"]) != np.mean(s2["测验"]):
return np.mean(s1["测验"]) > np.mean(s2["测验"])
else:
return np.mean(s1["实验"]) > np.mean(s2["实验"])
# 根据分数大小,将学生信息插入到列表中,插入排序
def add_to_list(stu, stu_list):
if len(stu_list):
if cmp_student(stu, stu_list[0]): # 比第一名还优秀
stu_list.insert(0,stu)
elif not cmp_student(stu, stu_list[-1]): # 比最后一名还差
stu_list.append(stu)
else:
for i in range(len(stu_list)-1):
if (not cmp_student(stu, stu_list[i])) and (cmp_student(stu, stu_list[i+1])):
stu_list.insert(i+1, stu)
return
else:
stu_list.append(stu)
原谅我写了这么多if!

手动添加时,逐个输入学生的信息,最后按照分数插入到相应的位置,注意的是,需要保证在输入成绩时确保获取的是数字,否则提示错误需要用户重新输入:
# 输入一个数字
def input_number(information):
while True:
try:
print("\033[34m",end='')
number = input(information)
print("\033[0m",end='')
if type(eval(number)) == float or type(eval(number)) == int:
return float(number)
except :
print('\033[1;31m',end='')
print("输入有误,请输入一个数字!")
print('\033[0m',end='')
注:类似print("\033[34m",end='')这类语句是控制输出的字体颜色的。下同
从文件中添加时,系统提供了默认文件的选项,直接回车则默认从data_file目录下的学生成绩信息.csv文件导入,因为有些用户是懒得输入文件名的。需要注意的是,导入的文件中,允许成绩选项缺失,如果缺失了,则利用其它成绩重新计算得出。但其它必要信息不能缺失:
# 从文件添加学生信息
# 需要遵循格式:['序号','姓名','学号','分数','排名','作业1','作业2','作业3','作业4', '测验1', '测验2', '实验1', '实验2']
def add_from_file(stu_list):
print("\033[34m",end='')
fn = input("请输入文件路径(例如: C:/a.csv, 直接回车则默认为[./data_file/学生成绩信息.csv]) >> ")
print("\033[0m",end='')
file_path = './data_file/'+'学生成绩信息.csv' # 默认选项
if fn != '':
file_path = fn
n = 0
n_du = 0
with open(file_path) as csvfile:
csv_reader = csv.reader(csvfile) # 使用csv.reader读取csvfile中的文件
next(csv_reader) # 跳过文件头
for row in csv_reader: # 读取数据
if find_student_uid(row[2], stu_list) != -INF: # 如果存在学号相同,则不添加
n_du = n_du + 1
continue
work = [float(x) for x in row[5:9]] #转化作业成绩
test = [float(x) for x in row[9:11]] #转化测验成绩
experiment = [float(x) for x in row[11:]] #转化实验成绩
score = 0
if row[3] == '':
score = calc_score(work, test, experiment) # 考虑到成绩位置为空的情况,重新计算成绩。
else:
score = float(row[3])
stu_info = {'姓名':row[1], '学号':row[2], '作业':work,
'测验':test, '实验': experiment, '分数':score}
add_to_list(stu_info,stu_list) #将字典数据添加到列表中,插入排序。
n = n + 1
print('\033[1;31m')
print("从文件["+file_path+"]添加信息成功!共添加 "+str(n)+" 条信息,跳过 "+str(n_du)+" 条重复信息!")
print('\033[0m')
return stu_list
2.2 修改学生信息
这一块比较简单,找到学生信息后,输入相应信息然后修改。大部分都是提示输入的语句。

不过需要注意的是,修改了相应的作业、实验等成绩后,需要更新学生的分数,同时重新计算学生的排名,将该生挪到列表的相应位置上。具体做法在我的代码实现中比较简单,先将该生从列表中移除,重新计算分数后再按照插入排序的思路放进列表即可。这样速度可能会快一些。因为变动信息的只有一个学生,如果再次对整个列表进行排序可能会造成比较大的开销。
2.3 删除学生信息
这一块也相对来说比较简单,找到学生后,如果确认删除,则直接删除该学生即可。删除后其他学生的次序依然是有序的,无需再做调整。

2.4 查找学生信息
查找学生相关信息是通过`学号`遍历列表进行搜寻,找到后输出学生的相关信息。
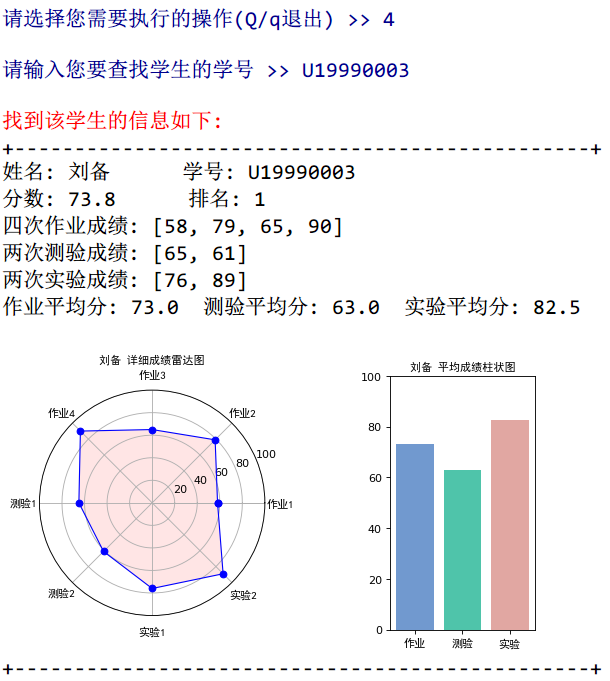
不过我在此基础上,对学生成绩进行了简单的统计,并通过图表的方式进行呈现。能够让老师或学生更直观地看到各科成绩的详细内容,找出自己的优势与不足,便于下次努力改进。(不过这里因为想把两个图拼在一个图上,因为不熟悉操作做了好久^~^)
bar1_colors = ['#7199cf','#4fc4aa','#e1a7a2']
labels = np.array(['作业1','作业2','作业3','作业4','测验1','测验2','实验1','实验2'])
name=['作业','测验','实验']
# 统计学生成绩等信息
def statistics_student(stu):
#=======自己设置开始============
#标签
#数据个数
dataLenth = len(stu["作业"])+len(stu["测验"])+len(stu["实验"])
#数据
all_scores = stu["作业"] + stu["测验"] + stu["实验"]
data = np.array(all_scores)
average_score=[np.mean(stu["作业"]),np.mean(stu["测验"]),np.mean(stu["实验"])]
#========自己设置结束============
angles = np.linspace(0, 2*np.pi, dataLenth, endpoint=False)
data = np.concatenate((data, [data[0]])) # 闭合 # #将数据结合起来
angles = np.concatenate((angles, [angles[0]])) # 闭合
fig = plt.figure(figsize=(8, 4.2), dpi=80)
ax = fig.add_subplot(121, polar=True)# polar参数!!121代表总行数总列数位置
ax.plot(angles, data, 'bo-', linewidth=1)# 画线四个参数为x,y,标记和颜色,闲的宽度
ax.fill(angles, data, facecolor='r', alpha=0.1)# 填充颜色和透明度
ax.set_thetagrids(angles * 180/np.pi, labels, fontproperties='SimHei')
ax.set_title("{} 详细成绩雷达图".format(stu["姓名"]),fontproperties='SimHei',weight='bold', size='medium', position=(0.5, 1.11),
horizontalalignment='center', verticalalignment='center')
ax.set_rlim(0,100)
ax.grid(True)
xticks = np.arange(len(average_score)) #生成x轴每个元素的位置
ax=fig.add_subplot(133)
ax.set_xticklabels(name, fontproperties='SimHei')
ax.set_xticks(xticks) #设置x轴上每个标签的具体位置
ax.set_ylim([0, 100]) # 设置y轴范围
ax.bar(xticks,average_score,color=bar1_colors)
ax.set_title("{} 平均成绩柱状图".format(stu["姓名"]),fontproperties='SimHei')
plt.show()2.5 打印全体学生成绩信息
这一个功能实现也蛮简单,遍历学生列表,然后调用打印函数逐个进行打印输出即可,这里输出单个学生信息的时候就没有输出统计图的信息了。主要是考虑到人数过多时,输出图的话,可能会导致速度过慢,影响体验。输出完成后会简单统计一下一共有几个人。

2.6 课程成绩统计
在统计成绩这个模块中,由于数据在列表中已经是有序的了,所以最高分最低分,中位数的获取都比较容易。而平均分也可以很快得出。(其实我觉得,程序的整体结构和思路做好以后,功能模块的实现就方便得多了。)
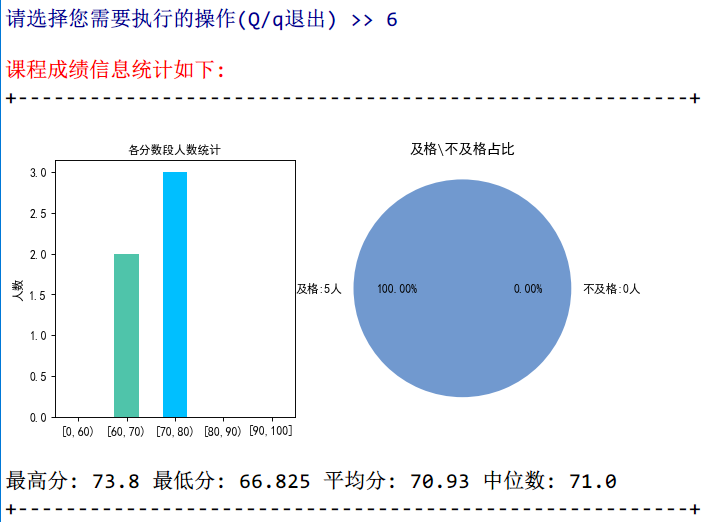
同样地,在这里我也做了一个图形的统计,利用柱状图展示了各个分数段的人数,方便老师快速了解成绩的分布情况。然后利用了饼状图分析了`及格人数/不及格人数`的比例,因为在这里不及格的人数为0,所以整块都是及格的蓝色。
画图的代码如下(有了上一张图的经验,这张就好多了):
## 绘制统计试图
def print_statistics_view(stu_list):
##### 数据设置
range_number = [0,0,0,0,0] #各分数段人数
type_number = [0,0] # 各类型人数[及格,不及格,缺考]
for stu in stu_list:
count_type(stu, type_number)
count_range(stu, range_number)
#### 开始绘图
fig = plt.figure(figsize=(8, 4), dpi=85) #整体图的标题
colors = ['#7199cf', '#4fc4aa', '#00BFFF', '#FF7F50', '#BDB76B']
#①在121位置上添加柱图,通过fig.add_subplot()加入子图
ax = fig.add_subplot(121)
ax.set_title('各分数段人数统计', fontproperties='SimHei') #子图标题
xticks = np.arange(len(range_number)) #生成x轴每个元素的位置
bar_width = 0.5 #定义柱状图每个柱的宽度
#设置x轴标签
score_range = ['[0,60)','[60,70)','[70,80)','[80,90)','[90,100]']
ax.set_xticklabels(score_range)
ax.set_xticks(xticks) #设置x轴上每个标签的具体位置
#设置y轴的标签
ax.set_ylabel('人数', fontproperties='SimHei')
ax.bar(xticks, range_number, width=bar_width, color=colors, edgecolor='none') #设置柱的边缘为透明
#②在122位置加入饼图
ax = fig.add_subplot(122)
ax.set_title('及格\不及格占比')
# 生成同时包含名称和速度的标签
type_labels = ['及格','不及格']
pie_labels = ['{}:{}人'.format(type_name, number) for type_name, number in zip(type_labels, type_number)]
# 画饼状图,并指定标签和对应颜色
#解决汉字乱码问题
matplotlib.rcParams['font.sans-serif']=['SimHei'] #使用指定的汉字字体类型(此处为黑体)
ax.pie(type_number, labels=pie_labels, colors=colors, autopct='%1.2f%%')
ax.axis('equal') #保证饼图不变形
plt.show()2.7 保存学生信息到文件中
在保存到文件时,默认保存到程序目录下的data_file目录里面,用户可以手动输入文件名,也可以直接回车使用默认选项(防止用户懒得输入这么麻烦的东西^_^)。

# 文件头
STUDENT_LABEL = ['序号','姓名','学号','分数','排名','作业1','作业2','作业3','作业4', '测验1', '测验2', '实验1', '实验2']
FILE_DIR = './data_file/' #保存文件的目录,默认为当前文件下的data_file目录
# save to file保存到文件
def save_to_file(stu_list):
print("\033[34m",end='')
fn = input("请输入文件名(例如: a.csv, 直接回车则默认为[学生成绩信息.csv]) >> ")
print('\033[0m',end='')
if fn == '': # 默认选项
fn = '学生成绩信息.csv'
elif len(fn) < 5: # 该用户没有输入后缀名
fn = fn + '.csv'
elif fn[-4:] != '.csv': # 该用户没有输入后缀名
fn = fn + '.csv'
all_values = []
for index, stu in enumerate(stu_list):
'''
一个stu字典实体序列化成我们想要的格式,便于保存到文件
index为保存到文件后该实体的序号,与list的序号对应
'''
stu_value = [index, stu['姓名'], stu['学号'], stu['分数'], index+1]
stu_value = stu_value + stu['作业'] + stu['测验'] + stu['实验']
all_values.append(stu_value)
with open(FILE_DIR+fn,'w+',newline='') as f:
writer = csv.writer(f)#创建一个csv的写入器
writer.writerow(STUDENT_LABEL)#写入标签
writer.writerows(all_values) #写入样本数据
f.close()
print('\033[1;31m')
print("保存信息到["+FILE_DIR+fn+"]成功!")
print('\033[0m')
用户输入自定义的文件名后,由于保存的是CSV格式的文件,因此需要简单修正一下用户输入的文件名(因为有时候可能没有输入后缀名之类的。),然后再读取列表的数据,保存到文件中,如下:
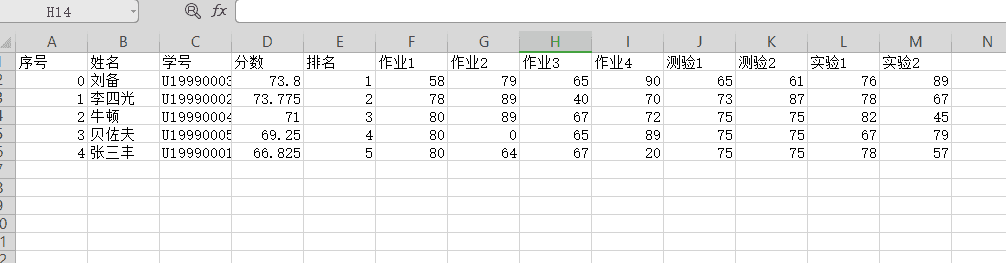
可以看到,由于列表的数据始终是有序的,因此排名与序号是对应的。
2.8 从文件中读取学生信息
从文件读取信息时,遵循的格式和保存的格式是一致的。与从文件中添加信息不同的是,该功能读取文件中所有的信息添加进一个新的列表,然后丢弃系统原有的列表,使用读取文件生成的新列表。

同时,从文件读取信息时,也允许分数项缺失,如果缺失,则重新计算后存入列表中去。导入文件也提供了默认的文件:
# 从文件导入信息
# 需要遵循格式:['序号','姓名','学号','分数','排名','作业1','作业2','作业3','作业4', '测验1', '测验2', '实验1', '实验2']
def load_from_file():
print("\033[34m",end='')
fn = input("请输入文件路径(例如: C:/a.csv, 直接回车则默认为[./data_file/学生成绩信息.csv]) >> ")
print('\033[0m',end='')
file_path = FILE_DIR+'学生成绩信息.csv' # 默认选项
if fn != '':
file_path = fn
stu_list = []
n = 0
with open(file_path) as csvfile:
csv_reader = csv.reader(csvfile) # 使用csv.reader读取csvfile中的文件
next(csv_reader) # 跳过文件头
for row in csv_reader: # 读取数据
work = [float(x) for x in row[5:9]] #转化作业成绩
test = [float(x) for x in row[9:11]] #转化测验成绩
experiment = [float(x) for x in row[11:]] #转化实验成绩
score = 0
if row[3] == '':
score = calc_score(work, test, experiment) # 考虑到成绩位置为空的情况,重新计算成绩。
else:
score = float(row[3])
stu_info = {'姓名':row[1], '学号':row[2], '作业':work,
'测验':test, '实验': experiment, '分数':score}
stu_list.append(stu_info) #
n = n + 1
# 如果读取的是本程序输出的,按理说不用排序
# 但也可能是从其他文件读入的数据,所以还是得做一下排序。
stu_list.sort(key=lambda d:(d["分数"],np.mean(d["作业"]),np.mean(d["测验"]),np.mean(d["实验"])), reverse = True) # 排好序
print('\033[1;31m')
print("从文件["+file_path+"]导入成功!共 "+str(n)+" 条信息!")
print('\033[0m')
return stu_list2.9 退出
在退出的时候,我做了一个小提示,提示用户是否保存当前数据到文件中去。因为有时候如果不提醒用户的话,用户可能由于疏忽而忘记了保存到文件,一旦退出程序则数据就丢失了。

这个程序断断续续写了好久,主要是想把这个作业给做的完善一些(因为小编有各种强迫症)。尽管这是一个小小的project,但是如果能充分考虑各方面的因素,功能上做到尽可能完美,程序上尽可能做到健壮,也是一件并不简单的事情。
当然了,一些元素都是基于我自己个人的简单思考而设计实现的需求,并没有做过相关实际的调研问询,所可能会存在不合理的地方。希望各位读者嘴下留情。如果喜欢的话,各位可以点个在看嘛!

完整源代码在公众号后台回复【Python成绩管理】即可获取
推荐阅读:
干货 | 学习算法,你需要掌握这些编程基础(包含JAVA和C++)
记得点个在看支持下哦~
