
分布式事务理论加实战
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
为什么需要分布式事务
随着互联网的快速发展,业务越来越复杂,一个完整的业务往往需要调用多个子服务,涉及的数据也越来越多。传统的系统难以支撑,就出现了分布式系统,而分布式系统又带来了数据一致性的问题,从而产生了分布式事务。
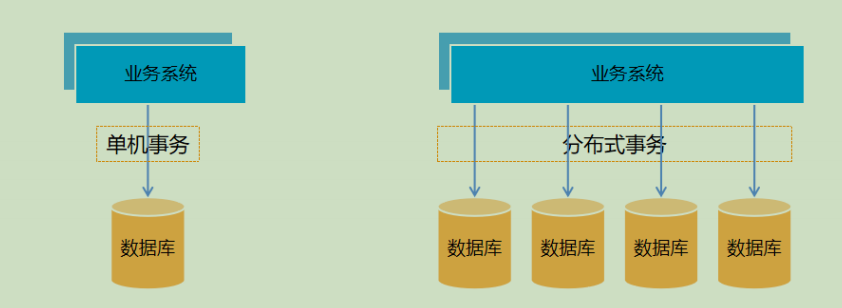
什么叫分布式事务
分布式条件下,多个节点操作的整体事务一致性。
特别是在微服务场景下,业务A和业务B关联,如果事务A成功了,事务B失败了。由于跨系统,事务B无法通知到事务A,就造成了数据的不一致。
如何实现分布式下的一致性
强一致性
XA
弱一致性
不用事务,业务侧补偿冲正
柔性事务,使用一套事务框架保证最终一致性的事务。
一、强一致性事务
1. XA分布式事务
在学习XA之前,我们先了解一下DTP模型,该模型规范了分布式事务的模型设计
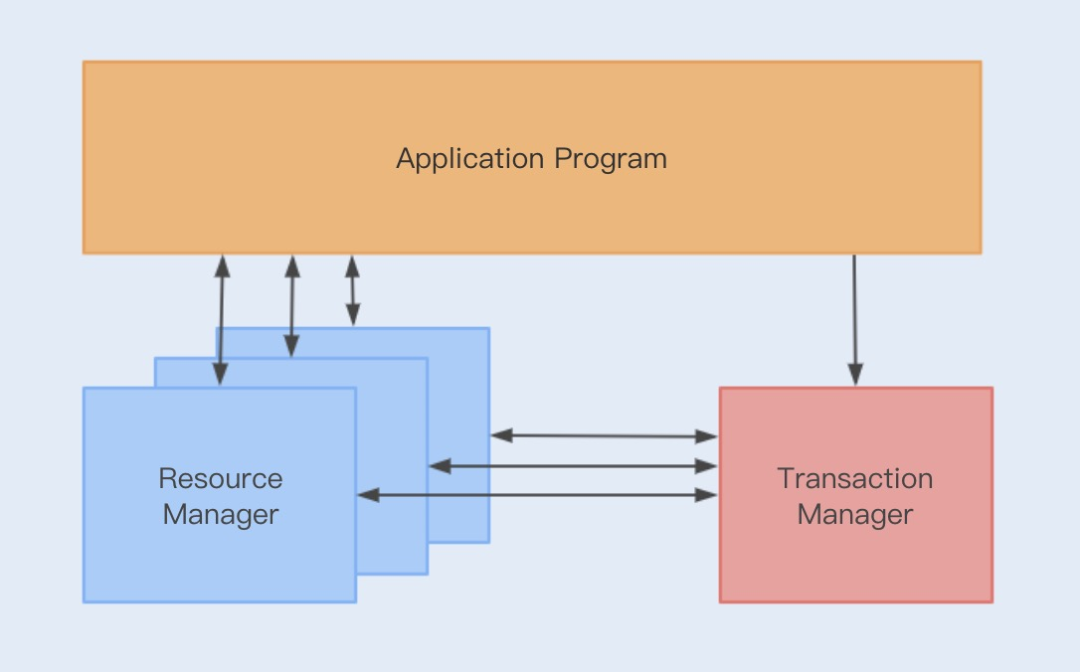
应用程序(Application Program):定义事务边界(即事务的开始和结束),并且在事务边界内对资源进行操作
资源管理器(Resource Manager):如数据库、文件系统等。并提供访问资源的方式
事务管理器(Transaction Manager):负责分配事务唯一标识,监控事务的执行进度,并负责事务的提交、回滚等。
XA协议 是由 X/Open 组织提出的,作为资源管理器与事务管理器的接口标准.目前Oracle、DB2、MySQL的InnoDB存储引擎都对XA进行了支持。XA接口提供资源管理器与事务管理器之间进行通信的标准接口。XA协议包括两套函数,以xa_开头的及以ax_开头的。

xa_start:负责开启或者恢复一个事务分支
xa_end:负责取消当前线程和事务分支的关联
xa_prepare:询问RM是否准备好提交事务分支
xa_commit:通知RM提交事务分支
xa_rollback:通知RM回滚事务分支
xa_recover:列出所有prepare的XA事务
MySQL 从5.0.3开始支持 InnoDB 引擎的 XA 分布式事务,MySQL Connector/J 从5.0.0版本开始支持 XA
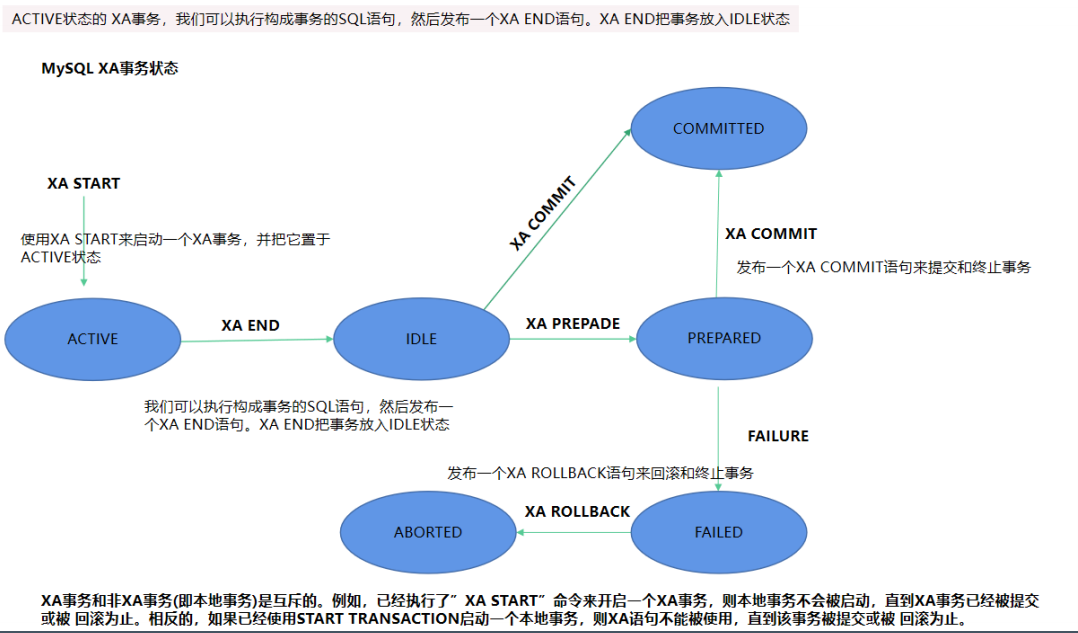
MySQL XA事务状态
完整的XA事务流程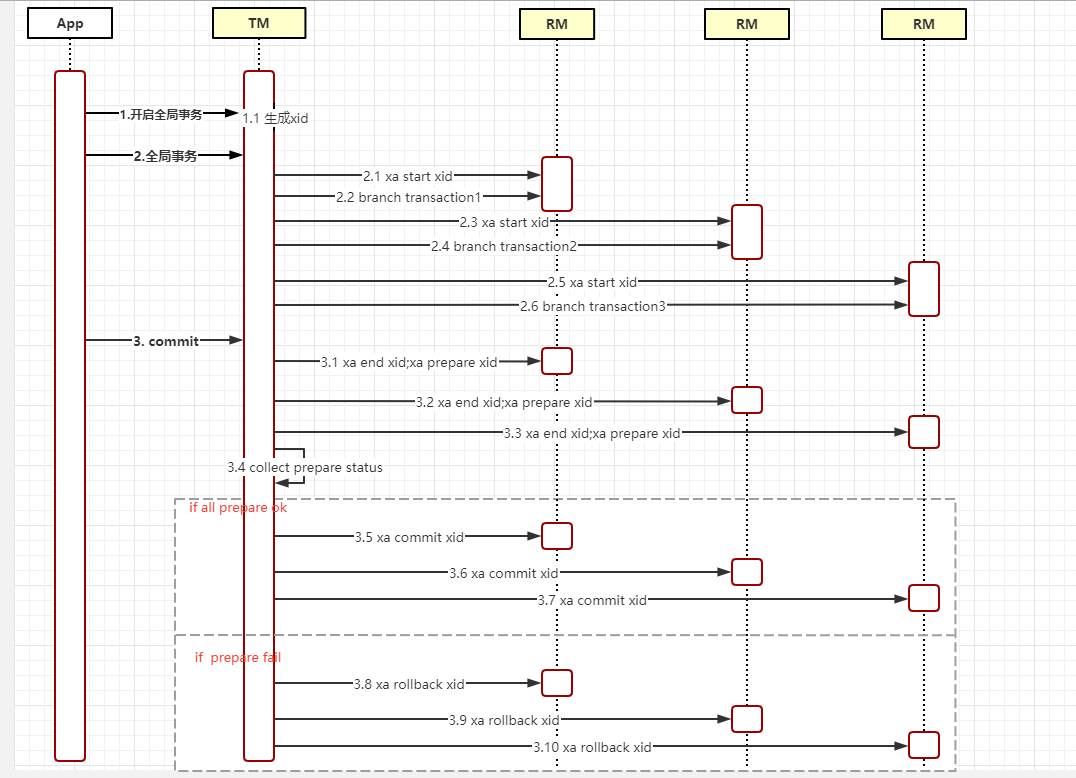
XA事务异常情况
业务SQL执行期间,某个RM崩溃怎么处理?
答:通知回滚。
2. 全部prepare后,某个RM崩溃怎么处理?
答:5.7以前崩溃的那个RM会丢失事务,导致别人都提交了,他被回滚了。5.7之后修复了,重连后还能继续提交。
commit时,某个RM崩溃了怎么办?
答:RM恢复之后重试,要是重试还是失败就要发送告警,人工进行干预。
XA协议存在的问题
同步阻塞问题
全局事务内部包含了多个独立的事务分支,这一组事务分支,这一组事务分支要不都成功,要不都失败。各个事务分支的ACID特性构成了全局事务的ACID特性。那么mysql的效率也会降低
2. 单点故障
TM是单点的,一旦TM发生故障,参与者RM会一直阻塞下去。尤其再第二阶段,TM发生故障,那么所有的RM都还处于锁定资源的状态中,而无法完成事务操作。成熟的XA框架需要考虑TM的高可用性。
数据不一致
在提交阶段的时候,TM向RM发送commit请求后,发生了局部网络异常或者在发送commit请求的时候TM故障了,会导致部分RM收到commit请求并执行,而部分RM未收到commit请求则无法进行事务提交,就会造成数据不一致的情况。
支持XA的框架
XA方面的框架,比较推荐Atomikos和narayana
二、柔性事务
如果将实现了ACID的事务要素的事务称为刚性事务的话,那么基于BASE理论的事务则称为柔性事务。
BASE:
Basically Available (基本可用)
Soft state(柔性状态) 允许系统状态更新有一定的延时
Eventually consistent(最终一致性)
柔性事务常见模式
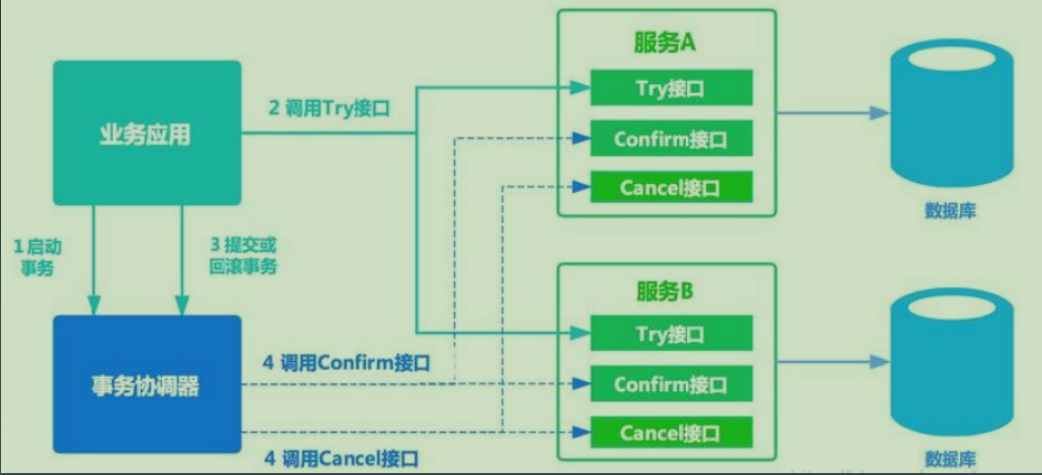
1. TCC
TCC模式将每个服务的业务操作分为两个阶段。第一个阶段检查并预留相关资源(Try),第二个阶段根据Try状态,如果都成功,则进行Comfirm操作,如果任意一个发生错误,则全部Cancel。
Try:完成所有业务检查,预留资源
Confirm:正在执行的业务逻辑,不做业务检查,只是要Try阶段预留的业务资源。因此,只要Try成功,Confirm基本能成功。另外Confirm需要满足幂等性。
Cancel:释放Try阶段的资源。同样Cancel也需要满足幂等性。
TCC不依赖RM对分布式事务的支持,而是通过对业务逻辑的分解来实现分布式事务。对业务有侵入性
TCC需要注意的问题:
允许空回滚
Cancel的时候要判断Try有没有完成,没完成就不做Cancel
2. 防悬挂控制
如果网络等数据库还没收到Try的执行命令,Cancel命令先收到了。就会导致这个Try命令就没有相对于的Cancel操作了,会一直悬挂在那里。
解决方法:
可以控制Try和Cancel的顺序,让Try在前面
先收到Cancel的时候,记录一下。再收到Try的时候就知道这个操作是要取消的,那Try就没必要执行了。
幂等设计
commit操作可能会被重试,所以需要幂等性。
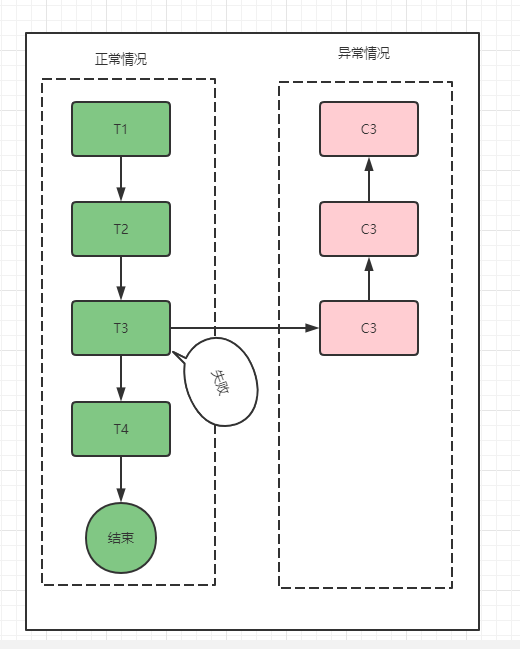
2. SAGA
Saga模式没有Try阶段,直接提交事务。复杂情况下,对回滚操作的设计要求较高。
3. AT
AT就是通过自动生成反向SQL的方式进行回滚。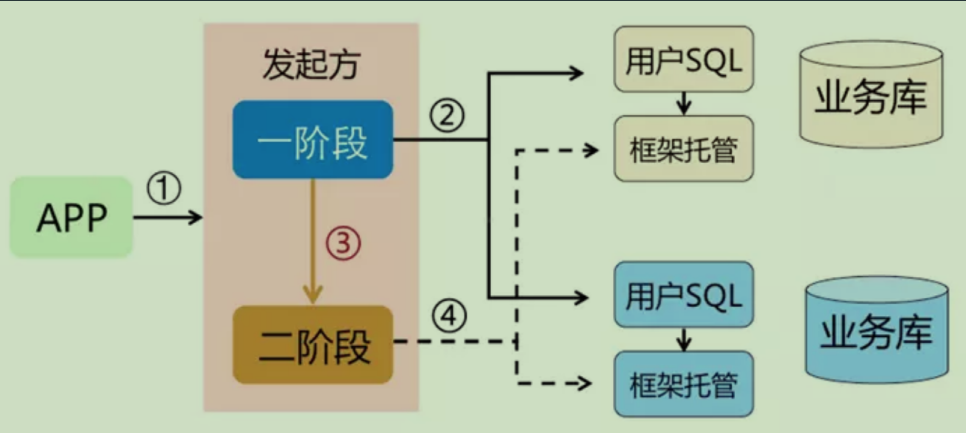
在第一阶段的时候执行业务SQL,并且将SQL造成的影响保留下来。
第二阶段如果发生异常,就会通过保留的影响用反向SQL恢复回去。
缺点:生成反向SQL如果是在特别复杂的情况下,可能会处理不了。
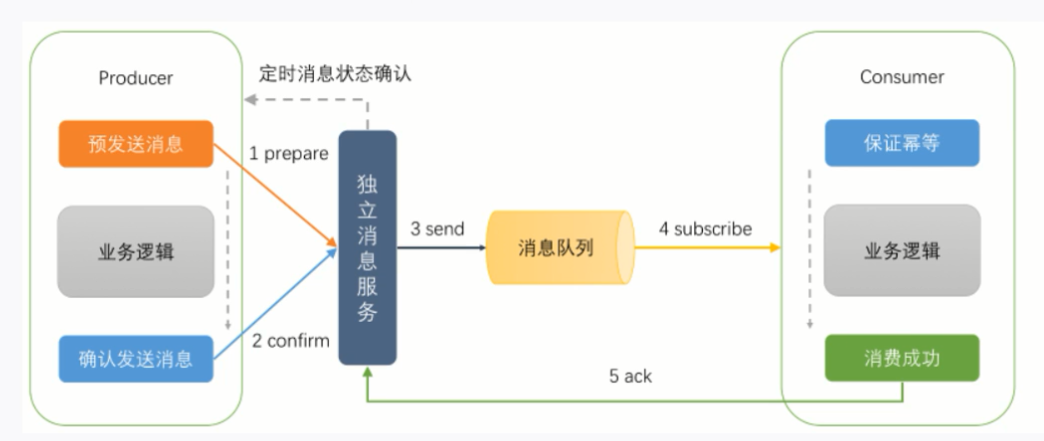
4. 可靠消息最终一致性
服务A发送一个prepared消息给mq,如果发送失败则取消操作
消息发送成功则开始执行本地事务
本地事务执行成功就向mq发送确认消息,执行失败就发送回滚消息
如果mq没有接收到确认消息,mq会去轮询未确认的prepared消息,然后去查询服务A是否执行成功,然后确定是重试还是回滚
如果mq成功收到确认消息,那么他会被服务B消费到,并且服务B可以通过ACK机制保证服务B执行成功.
如果服务B实在是无法执行成功,可以通知服务A回滚,或者发送报警消息让手工补偿.
5. 本地消息表
服务A执行业务代码,并往自己的消息表插入一条数据
服务A执行成功后,会向MQ发送一条数据,去调用服务B的方法
服务B收到后,先往自己的消息表插入一条数据,然后去执行业务代码
如果服务B业务代码执行成功,那么更新自己的消息表的状态并且通知服务A更新消息表状态
如果服务B业务代码执行失败,那么服务B不用做什么
服务A会有一个定时任务定时轮询自己的消息表,将失败的消息再发给MQ,让服务B重新在执行一次(服务B保证接口幂等性)
通过不断的重试,保证最终一致性
这个方案大量使用来消息表,对于高并发的场景不太友好.
6. 最大努力型通知
类似银行的支付回调,会多次回调直到成功。
这种方案适用于允许有些事务失败的情况,如记录日志等.
三、分布式事务框架
1. Seata
Seata是阿里巴巴和蚂蚁金服联合打造的分布式事务框架。其AT事务的目标是让开发者像使用本地事务一样使用分布式事务。
核心组件:
TM 事务管理者:开启提交或回滚全局事务
TC 事务协调者:维护全局和分支事务的状态,指示全局提交或回滚。
RM 资源管理者:管理执行分支事务上的资源,向TC注册分支事务、上报分支事务状态、控制分支事务的提交或回滚。
Seata管理的分布式事务的典型声明周期: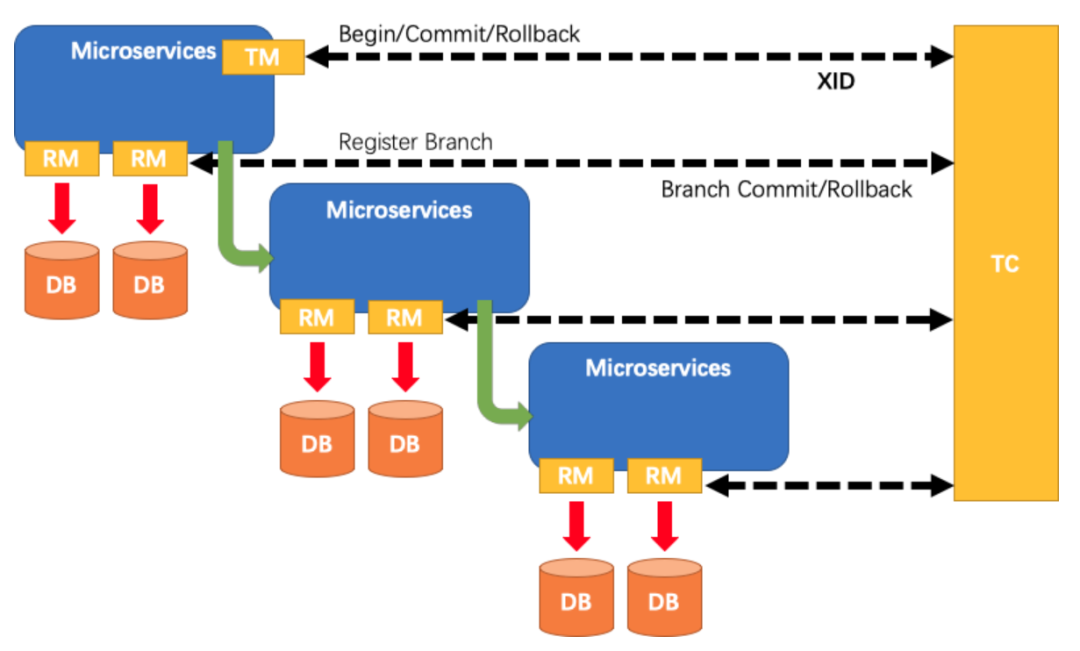
TM要求TC开始一个全新的全局事务。
TC生成一个代表该全局事务的XID。XID贯穿整个微服务的调用链。
TM要求TC提交或回滚XID对应的全局事务。
TC驱动XID对应的全局事务下的所有分支事务完成提交或回滚。
Seata支持 XA、TCC、Saga模式,但支持的主要方式是 AT。
2. ShardingSphere对分布式事务的支持
ShardingSphere 通过整合常用的几个事务开源实现,如Atomkkos、Narayana,为本地事务、两阶段事务和柔性事务提供统一的分布式事务接口,并弥补当前方案的不足,提供一站式的分布式事务解决方案是ShardingSphere的设计目标。
使用实例:https://gitee.com/mmcLine/spring-cloud-transaction
里面readme有详细的项目介绍。
作者 | 女友在高考
来源 | cnblogs.com/javammc/p/15098694.html
