
一次神奇的 SQL 慢查询经历!

Java技术栈
www.javastack.cn
关注阅读更多优质文章
作者:dijia478
来源:www.cnblogs.com/dijia478/p/11550902.html
一、问题背景
现网出现慢查询,在500万数量级的情况下,单表查询速度在30多秒,需要对sql进行优化,sql如下:
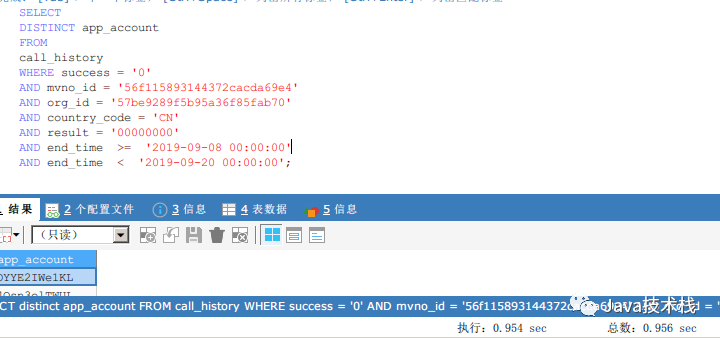
我在测试环境构造了500万条数据,模拟了这个慢查询。
简单来说,就是查询一定条件下,都有哪些用户的,很简单的sql,可以看到,查询耗时为37秒。
说一下app_account字段的分布情况,随机生成了5000个不同的随机数,然后分布到了这500万条数据里,平均来说,每个app_account都会有1000个是重复的值,种类共有5000个。
二、看执行计划
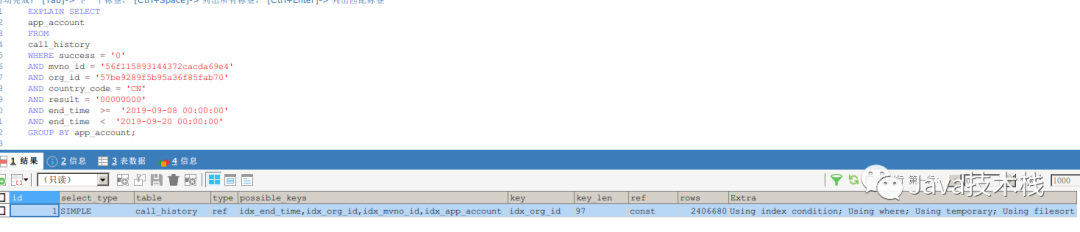 可以看到,group by字段上我是加了索引的,也用到了。使用方法见这篇《Explain 最完整总结》文章。
可以看到,group by字段上我是加了索引的,也用到了。使用方法见这篇《Explain 最完整总结》文章。
三、优化
说实话,我是不知道该怎么优化的,这玩意还能怎么优化啊!先说下,下面的思路都是没用的。
思路一:
后面应该加上 order by null;避免无用排序,但其实对结果耗时影响不大,还是很慢。
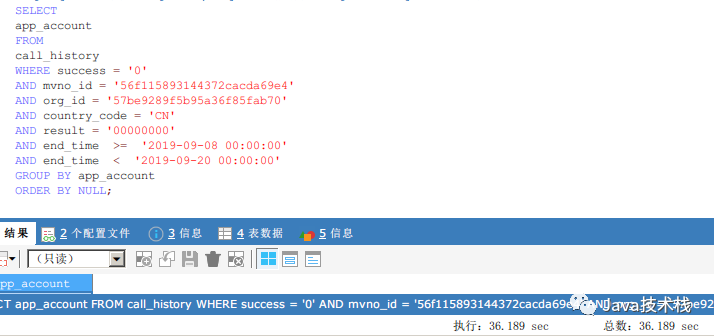
思路二:
where条件太复杂,没索引,导致查询慢,但我给where条件的所有字段加上了组合索引,也还是没用。
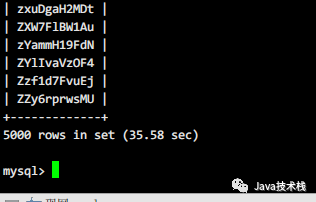
思路三:
既然group by慢,换distinct试试??
卧槽???!!!
这是什么情况,瞬间这么快了??!!!
虽然知道group by和distinct有很小的性能差距,但是真没想到,差距居然这么大!!!
大发现啊!!
四、你以为这就结束了吗
我是真的希望就这么结束了,那这个问题就很简单的解决了,顺便还自以为是的发现了一个新知识。关注公众号Java技术栈回复面试,可以获取我整理的 MySQL 及更多面试题答案。
但是!
这个bug转给测试后,测试一测,居然还是30多秒!?这是什么情况!!???
我当然是不信了,去测试电脑上执行sql,还真是30多秒。。。
我又回我的电脑上,连接同一个数据库,一执行sql,0.8秒!?
什么情况,同一个库,同一个sql,怎么在两台电脑执行的差距这么大!
后来直接在服务器上执行:
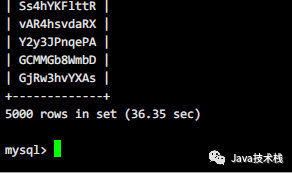
醉了,居然还是30多秒。。。。
那看来就是我电脑的问题了。
后来我用多个同事的电脑实验,最后得出的结论是:
是因为我用的SQLyog!
哎,现在发现了,只有用sqlyog执行这个“优化后”的sql会是0.8秒,在navicat和服务器上直接执行,都是30多秒。
那就是sqlyog的问题了,现在也不清楚sqlyog是不是做什么优化了,这个慢查询的问题还在解决中(我觉得问题可能是出在mysql自身的参数上吧)。
这里只是记录下这个坑,sqlyog执行sql速度,和服务器执行sql速度,在有的sql中差异巨大,并不可靠。
五、后续(还未解决)
感谢大家出谋划策,我来回复下问题进展:
1.所谓的sqlyog查询快,命令行查询慢的现象,已经找到原因了。是因为sqlyog会在查询语句后默认加上limit 1000,所以导致很快。这个问题不再纠结。
2.我已经试验过的方法(都没有用):
①给app_account字段加索引。
②给sql语句后面加order by null。
③调整where条件里字段的查询顺序,有索引的放前面。
④给所有where条件的字段加组合索引。
⑤用子查询的方式,先查where条件里的内容,再去重。
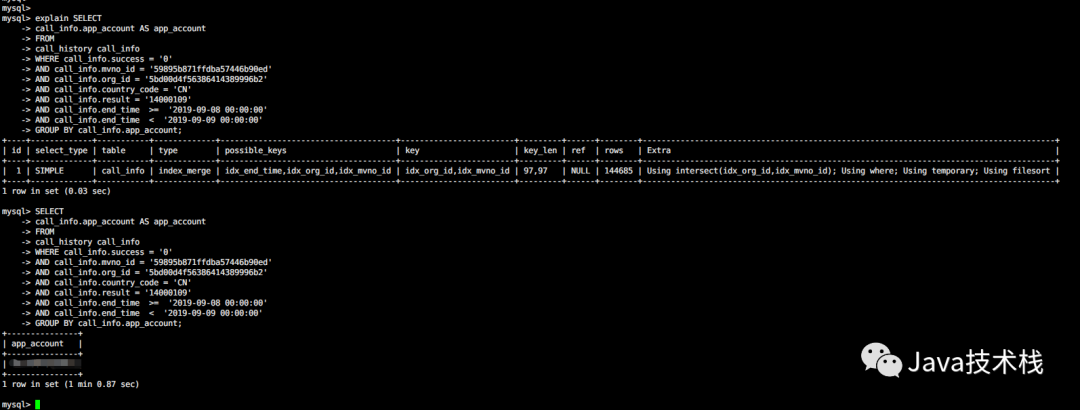
测试环境和现网环境数据还是有点不一样的,我贴一张现网执行sql的图(1分钟。。。):
六、最终解决方案
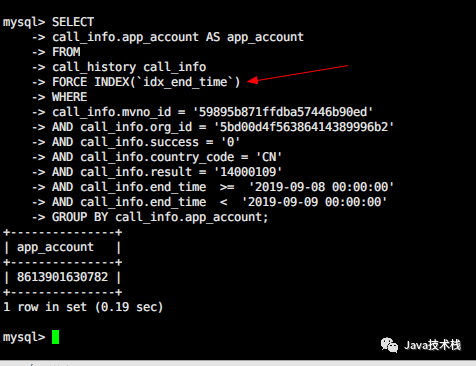
经过@言枫大佬!的提醒,我确实发现,explain执行计划里,索引好像并没有用到我创建的idx_end_time。
然后果断在现网试了下,强制指定使用idx_end_time索引,结果只要0.19秒!
至此问题解决,其实同事昨天也在怀疑,是不是这个表索引建的太多了,导致用的不对,原本用的是idx_org_id和idx_mvno_id。
现在强制指定idx_end_time就ok了!
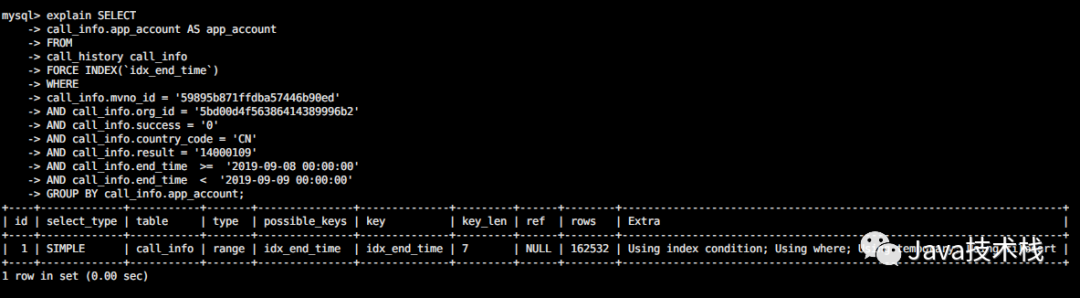
最后再对比下改前后的执行计划:
改之前(查询要1分钟左右):

改之后(查询只要几百毫秒):







关注Java技术栈看更多干货
