
【关于Bert】 那些的你不知道的事(下)
作者简介
作者:杨夕
论文名称:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
论文链接:https://arxiv.org/pdf/1706.03762.pdf
代码链接:https://github.com/google-research/bert
推荐系统 百面百搭地址:
https://github.com/km1994/RES-Interview-Notes
NLP 百面百搭地址:
https://github.com/km1994/NLP-Interview-Notes
个人 NLP 笔记:
https://github.com/km1994/nlp_paper_study
个人介绍:大佬们好,我叫杨夕,该项目主要是本人在研读顶会论文和复现经典论文过程中,所见、所思、所想、所闻,可能存在一些理解错误,希望大佬们多多指正。
引言
本博客 主要 是本人在学习 Bert 时的所遇、所思、所解,通过以 十二连弹 的方式帮助大家更好的理解 该问题。
十二连弹
【演变史】one-hot 是什么及所存在问题?
【演变史】word2vec 是什么及所存在问题?
【演变史】fastText 是什么及所存在问题?
【演变史】elmo 是什么及所存在问题?
【BERT】Bert 是什么?
【BERT】Bert 三个关键点?
【BERT】Bert 输入表征长啥样?
【BERT】Bert 预训练任务?
【BERT】Bert 预训练任务 Masked LM 怎么做?
【BERT】Bert 预训练任务 Next Sentence Prediction 怎么做?
【BERT】如何 fine-turning?
【对比】多义词问题及解决方法?
问题解答
【BERT】Bert 是什么?
BERT(Bidirectional Encoder Representations from Transformers)是一种Transformer的双向编码器,旨在通过在左右上下文中共有的条件计算来预先训练来自无标号文本的深度双向表示。因此,经过预先训练的BERT模型只需一个额外的输出层就可以进行微调,从而为各种自然语言处理任务生成最新模型。
这个也是我们常说的 【预训练】+【微调】
【BERT】Bert 三个关键点?
基于 transformer 结构
大量语料预训练:
介绍:在包含整个维基百科的无标签号文本的大语料库中(足足有25亿字!) 和图书语料库(有8亿字)中进行预训练;
优点:大语料 能够 覆盖 更多 的 信息;
双向模型:
BERT是一个“深度双向”的模型。双向意味着BERT在训练阶段从所选文本的左右上下文中汲取信息
举例:
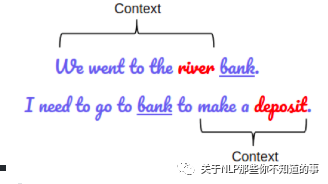

【BERT】Bert 输入输出表征长啥样?
input 组成:
Token embedding 字向量: BERT模型通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入;
Segment embedding 文本向量: 该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合;
Position embedding 位置向量:由于出现在文本不同位置的字/词所携带的语义信息存在差异(比如:“我爱你”和“你爱我”),因此,BERT模型对不同位置的字/词分别附加一个不同的向量以作区分
output 组成:输入各字对应的融合全文语义信息后的向量表示

【BERT】Bert 预训练任务?
预训练 包含 两个 Task:
Task 1:Masked LM
Task 2:Next Sentence Prediction
【BERT】Bert 预训练任务 Masked LM 怎么做?
动机:
双向模型 由于 可以分别 从左到右 和 从右到左 训练,使得 每个词 都能 通过多层 上下文 “看到自己”;
方法:Masked LM
做法:
s1:随机遮蔽输入词块的某些部分;
s2:仅预测那些被遮蔽词块;
s3:被遮盖的标记对应的最终的隐藏向量被当作softmax的关于该词的一个输出,和其他标准语言模型中相同


【BERT】Bert 预训练任务 Next Sentence Prediction 怎么做?

【BERT】如何 fine-turning?

【BERT】BERT的两个预训练任务对应的损失函数是什么(用公式形式展示)?
Bert 损失函数组成:
第一部分是来自 Mask-LM 的单词级别分类任务;
另一部分是句子级别的分类任务;
优点:通过这两个任务的联合学习,可以使得 BERT 学习到的表征既有 token 级别信息,同时也包含了句子级别的语义信息。
损失函数
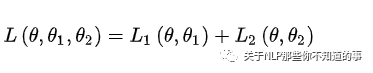
注:θ:BERT 中 Encoder 部分的参数;θ1:是 Mask-LM 任务中在 Encoder 上所接的输出层中的参数;θ2:是句子预测任务中在 Encoder 接上的分类器参数;
在第一部分的损失函数中,如果被 mask 的词集合为 M,因为它是一个词典大小 |V| 上的多分类问题,所用的损失函数叫做负对数似然函数(且是最小化,等价于最大化对数似然函数),那么具体说来有:
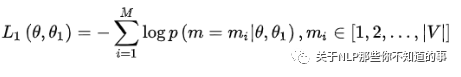
在第二部分的损失函数中,在句子预测任务中,也是一个分类问题的损失函数:
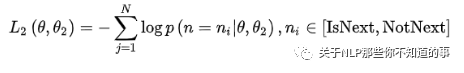
两个任务联合学习的损失函数是:
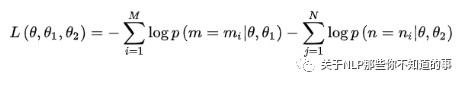
【对比】多义词问题及解决方法?


参考
CS224n
关于BERT的若干问题整理记录
所有文章
五谷杂粮
NLP百面百搭
Rasa 对话系统
知识图谱入门
转载记录
