
FAIR提出Barlow Twins:最简单的无监督学习方法
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
AI编辑:我是小将
本文作者:王珣
https://zhuanlan.zhihu.com/p/355523266
本文已由原作者授权转载
从Kaiming的MoCo和Hinton组Chen Ting的SimCLR开始,自监督学习(SSL)成了计算机视觉的热潮显学。凡是大佬大组(Kaiming, VGG,MMLAB等),近两年都是搞了几个自监督方法的。从一开始的新奇兴奋地看着Arxiv上新发布的SSL方法(像MoCo, SwAV, BYOL, SimSiam等这些方法着实有趣),但是有一些相关的文章多少有些泛滥了,让人很难觉得有趣。最近FAIR的一个新工作,着实让我惊叹,觉得很有意思,颇为叹服。关键的是这个方法特别简单,应当可以称之为最简单的SSL。文章名字是:《 Barlow Twins: Self-Supervised Learning via Redundancy Reduction》:https://arxiv.org/abs/2103.03230
藉此机会,我也自己梳理一下SSL在这不到两年的时间里的个人认为比较重要的认知变化的节点:从SimCLR为起点,以这篇BarLow Twins为暂时的终点。个人感觉,从这个历史线上去看SSL的发展非常有趣,整个圈子对于SSL的认知在不断打脸的过程中不断深入。
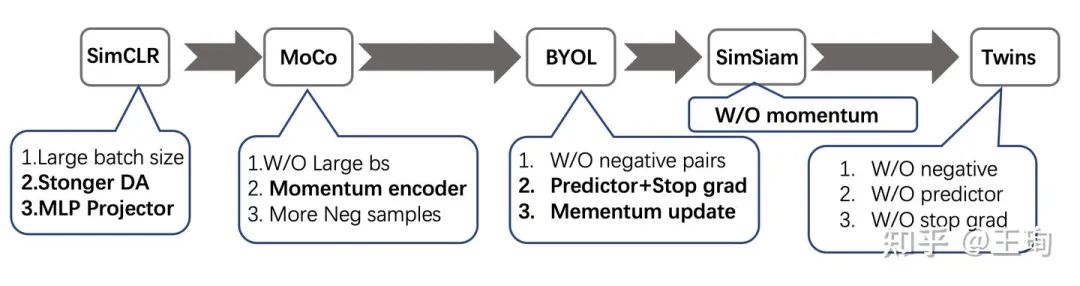
1. 首先是2020年初的SimCLR, 这个文章的核心贡献有二:一是提供了使用google的丰富的计算资源和工程力,使用高达4096的mini-batch size,把SSL的效果推到了supervised方法差不多的效果(预训练模型做下游任务);二是细致的整理了一些对SSL效果提升很有用的tricks: 如更长的训练,多层MLP的projector以及更强的data augmentations。这些有用的trick在后来的SSL的论文中一直被沿用,是SSL发展的基石,而第一个点,则是指出了大力出奇迹,为未来的论文指出了改进的路,或者树立了一个进击的靶子。
2. MoCo 共有两版本,原始版本是2019年末恺明放出来的。在SimCLR出现后之后,又吸收SimCLR的几个SSL小技巧,改进出了V2版,但是整体核心方法是没有变化的,V2仅仅是一个2页试验报告。相比于SimCLR大力出奇迹,恺明设计了一个巧妙的Momentum encoder 和 Dynamic queue 去获得大量的负样本。这里的momentum encoder 采用了动量更新机制,除了文章里的说法,另一层的理解是:其实momentum encoder相当于是teacher, 而dynamic里是来自不同mini-batch的样本,所以teacher需要在时间维度上对于同一个样本的输出具有一致性,否则,要学习的encoder 也就是student,会没有一个稳定的学习目标,难以收敛;当然另一方面,teacher 也不能一直不变,如果teacher一直不变,student就是在向一个随机的teacher学习。综合以上,动量更新机制是一个相当好理解的选择。
阶段小结:抛开细节,SimCLR和MoCo的核心点,都是认为negatives(负样本)非常重要,一定要有足够多的负样本,只不过实现方式略有不同。SimCLR 拿着TPU,直接把batch size搞到4096,一力降十会;恺明则是巧妙设计Momentum机制,避开了硬件工程的限制,做出了可以飞入寻常百姓家的MoCo。再次重申,这时候的认识,还是停留在需要大量的负样本,来提升SSL model的效果这个历史局限里。
3. BYOL 是Deep Mind 在2020年发布的工作,文章的核心点就是要破除“负样本迷信”,BYOL认为不使用负样本,照样可以训练出效果拔群的SSL model。但是如果直接抛弃负样本,只拉近正样本对的话,model 会容易陷入平凡解:对于任意样本,输出同样的embedding。为了在没有负样本的帮助下,解决这个问题。BYOL 在Projector之上,增加了一个新的模块,取名Predictor。整体可以理解为在MoCo的基础上,但是不再直接拉近正样本对(即同一个样本,不同增强后的输出)的距离,而是通过Predictor去学习online encoder 到 target encoder (即moco里的momentum encoder)的映射。另外,对target network梯度不会传递,即Stop-Gradient。(注:在MoCo中,momentum encoder也是没有梯度回传的,不过MoCo这么没有给momentum encoder回传梯度是因为queue里面的负样本来自过去的mini-batch, 本身计算图没有办法保存,没有办法回传梯度,而如果只回传正样本对的梯度,会很不合理。而BYOL是只考虑正样本对,如果梯度对于online encoder 和 target encoder都回传,是没有特别不合理的点的,因此Stop-Gradient是作者的一个特别的设计。)
4. SimSiam 是在BYOL的再次做减法,这里在BYOL的基础上去除了momentum更新的target encoder, 直接让target encoder = online encoder。指出了predictor+stop-gradinent 是训练强大SSL encoder的一个充分条件。
再次的阶段小结:在这个阶段,认识进展到了可以没有负样本的阶段,但是不使用负样本,模型就会有陷入平凡解的风险。为此,BYOL设计了predictor 模块,并为之配套了stop-gradient技巧;SimSiam通过大量的试验和控制变量,进一步做减法,去除了momentum update。让模型进一步变得简单。再次总结,就是predictor模块,避免了直接拉近正样本对,对于梯度的直接回传,让模型陷入平凡解。BYOL 和 SimSiam 在方法上都是很不错的,试验也做得很可信充分,可是对于方法的解释其实做的还不够,可能是要寻求一个扎实的解释也确实很难。可以参见从动力学角度看优化算法(六):为什么SimSiam不退化?- 科学空间|Scientific Spaces,也是很有意思的解释。此时已经进入到了摆脱了负样本了,但是在不使用负样本的情况,要想成功训练好一个SSL model,需要引入新的trick: 即predictor+stop-gradient。难免有点像无用功,但是技术其实是在螺旋进步的。
5. 最后,终于到了这次的主角:Barlow Twins。在不考虑数据增强这种大家都有的trick的基础上, Barlow Twins 既没有使用负样本,也没有动量更新的网络,也没有predictor和stop gradient操作。Twins 所做的是换了一种视角去学习表示,从embeddig本身出发,而不是从样本出发。优化目标是使得不同视角下的特征的相关矩阵接近恒等矩阵,即让不同的维度的特征尽量表示不同的信息,从而提升特征的表征能力。这种做法,感觉和以前传统降维(如PCA)的方法是有共通之处的。
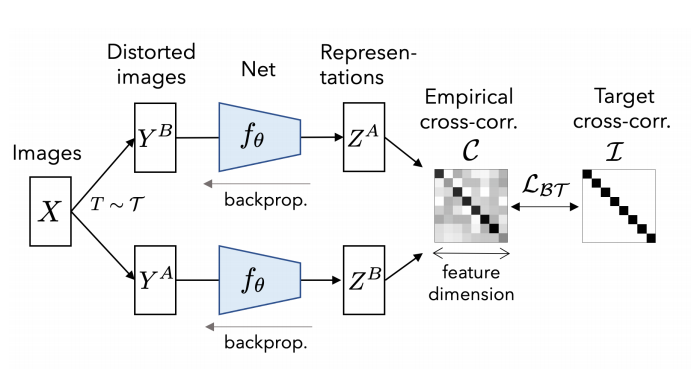




那么Twins 方法和以上的基于正负样本对的所有方法的区别,不严格(抛去特征normalize,BN等操作来说)的来说,可以用一句话,或者说两个式子来概括。
过去的方法大多基于InfoNCE loss 或者类似的对比损失函数,其目的是为了是的样本相关阵接近恒等矩阵,即

而Twins的目的是为了让特征相关阵接近恒等,即:

对于对比损失类方法,比如SimCLR或MoCo需要很大的Batchsize或者用queue的方式去模拟很大的batchsize, 而Twins需要极大的特征维度(8192)。这种特性和以上两个公式是完全对应且对称的。一个需要大  ,一个需要大
,一个需要大  。
。
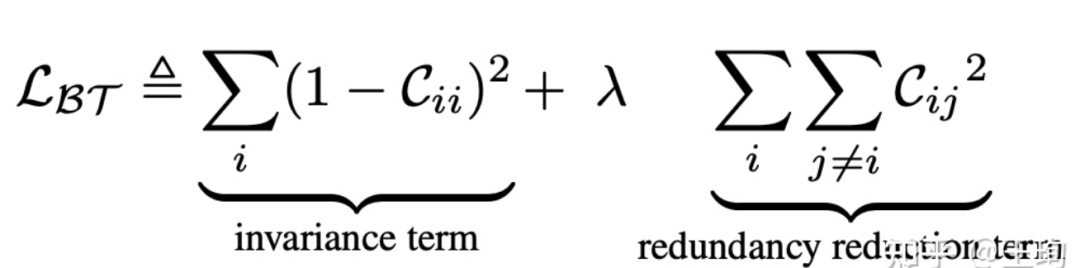
另外,另一个有意思的点是Loss里面的超参数,在论文里,超参数  是通过搜索得到的,然后发现在等于0.0002=1/5000是效果不错。其实,这里的loss略微改写,是可以省却这个不必要的超参数的。损失函数的第二项里的求和换成平均即可。首先,里面的求和换成平均等价于原来公式中
是通过搜索得到的,然后发现在等于0.0002=1/5000是效果不错。其实,这里的loss略微改写,是可以省却这个不必要的超参数的。损失函数的第二项里的求和换成平均即可。首先,里面的求和换成平均等价于原来公式中  ,虽然数字和搜出来并非完全相等,但是,这种超参数,从经验来说,在数量级上可以是完全一致了。可以合理的想像猜测在搜索这个超参数时,作者本人也是从数量级跨度去搜的。效果上,
,虽然数字和搜出来并非完全相等,但是,这种超参数,从经验来说,在数量级上可以是完全一致了。可以合理的想像猜测在搜索这个超参数时,作者本人也是从数量级跨度去搜的。效果上,  应当不会有差。那么,一个有意思的问题,为什么是平均呢?我认为是平衡“正负样本”(对于Twins其实没有这个概念了,为了方便,类别来说,指的其实是对角线和非对角线)的梯度,InfoNCE其实是通过softmax形式来隐式的获得了梯度之间的平衡,而这里是直接累加,对应的梯度回传也是直接累加,如果不用平均,或者说没有极小且合适的 。“负样本对”梯度将会占据主导,结果就是,我们的相关矩阵的非对角线大多已经接近0,loss第二项确实优化得很好,但是第一项没有长进。也就是说对角线元素距离“梦想中的1”会比较远。如果我以上的臆测分析是对的,那么就可以用平均去换掉loss内部求和,为保证公式的对称性,左一项也可以稍作等价改写,具体的Loss形式可以如下:
应当不会有差。那么,一个有意思的问题,为什么是平均呢?我认为是平衡“正负样本”(对于Twins其实没有这个概念了,为了方便,类别来说,指的其实是对角线和非对角线)的梯度,InfoNCE其实是通过softmax形式来隐式的获得了梯度之间的平衡,而这里是直接累加,对应的梯度回传也是直接累加,如果不用平均,或者说没有极小且合适的 。“负样本对”梯度将会占据主导,结果就是,我们的相关矩阵的非对角线大多已经接近0,loss第二项确实优化得很好,但是第一项没有长进。也就是说对角线元素距离“梦想中的1”会比较远。如果我以上的臆测分析是对的,那么就可以用平均去换掉loss内部求和,为保证公式的对称性,左一项也可以稍作等价改写,具体的Loss形式可以如下:

这样子,省掉一个较为难调的超参数,公式上更加对称,会让Twins显得更简洁合理。
总结:从历史线上来看,从需要大量的负样本的SimCLR和MoCo,到通过特殊技术(stop-grad+predictor)实践说明了负样本的不必要性的BYOL和SimSiam,最终到了Twins, Twins切换了一直以来从对比学习去看待SSL的训练,而是从特征本身出发。删繁就简,可以认为相比于最简单的裸InfoNCE,仅仅是换了一个loss function。另外,大的维度相比于增加batchsize的代价要小得多,只是encoder最后几层比较大,需要大一点的显存,而不是成倍的显存。
推荐阅读
谷歌提出Meta Pseudo Labels,刷新ImageNet上的SOTA!
"未来"的经典之作ViT:transformer is all you need!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
CondInst:性能和速度均超越Mask RCNN的实例分割模型
mmdetection最小复刻版(十一):概率Anchor分配机制PAA深入分析
MMDetection新版本V2.7发布,支持DETR,还有YOLOV4在路上!
无需tricks,知识蒸馏提升ResNet50在ImageNet上准确度至80%+
不妨试试MoCo,来替换ImageNet上pretrain模型!
mmdetection最小复刻版(七):anchor-base和anchor-free差异分析
mmdetection最小复刻版(四):独家yolo转化内幕
机器学习算法工程师
一个用心的公众号
