
全球首个智能超算排行榜来袭!中美日霸榜Top10,谷歌竟败给富士通!

新智元报道
新智元报道
编辑:QJP
【新智元导读】人工智能正逐渐取代数值计算成为最重要的数据分析和计算技术。以智能芯片和系统为基础的智能计算产业已成为国际科技和产业竞争的焦点,智能超级计算机更成为竞争的标杆。在这个背景下,急需制定智能芯片、系统以及智能超级计算机性能评价的标准。
国际测试委员会(BenchCouncil)在青岛举办的2020年国际测试委员会芯片和智能计算机联合大会上发布了 HPC AI500 智能超级计算机测试标准和 AIBench 智能芯片测试标准,这两个标准均由中科院计算所主导。
正如倪光南院士在2020年国际测试委员芯片大会开幕式致辞中指出的那样:“这些标准是控制计算机生态的关键 ”,同时将通过具体的性能排名引领产业良性竞争。
发布智能芯片、系统以及超级计算机排行榜的目的在于制定本领域竞争的规则。
当前美、欧、中、日都在争夺这个全新领域的标准。与其他组织主导的标准相比,中科院计算所主导的人工智能测试标准的科学性体现在以下三个方面:
(一)从大量的人工智能任务和模型中选择最有代表性的任务和模型作为测试工具;每个测试任务需要解决一个实际的挑战;
(二)评价指标不仅考虑性能,同时考虑对人工智能应用至关重要的精度;要求测试中止时达到当前最高的精度。将测试中止时所花费的时间也作为重要的性能指标;
(三)强调了测试的可重复性,排除了可重复性差的算法及模型。
智能芯片测试标准 AIBench 由中科院计算所联合阿里、腾讯、微软亚洲研究院、Paypal 等国内外17家知名企业共同发布。
AIBench 具体包含3个互联网人工智能场景和17个人工智能任务,是目前最全面的人工智能基准测试标准。
通过科学合理的实验,智能超级计算机测试标准 HPC AI500 榜单从人工智能基准测试标准AIBench 中选取了最有代表性的智能超级计算机测试程序:图像分类和极端天气分析(目标检测)。
考虑到模型精度在人工智能领域的重要性,HPC AI500 使用每秒有效浮点操作数(VFLOPS)作为主要的性能指标, 该指标是一个兼顾系统性能和模型精度的指标。
除了VFLOPS,HPC AI500同时还使用训练人工智能模型所需时间和相应模型所能达到的精度作为辅助指标。
全球首个智能超算放榜,前十里中美日占九成腾讯排第四
全球首个智能超算放榜,前十里中美日占九成腾讯排第四
依据 HPC AI500 性能评价标准,2020年国际测试委员会芯片大会发布了国际上第一个智能超级计算机排行榜。
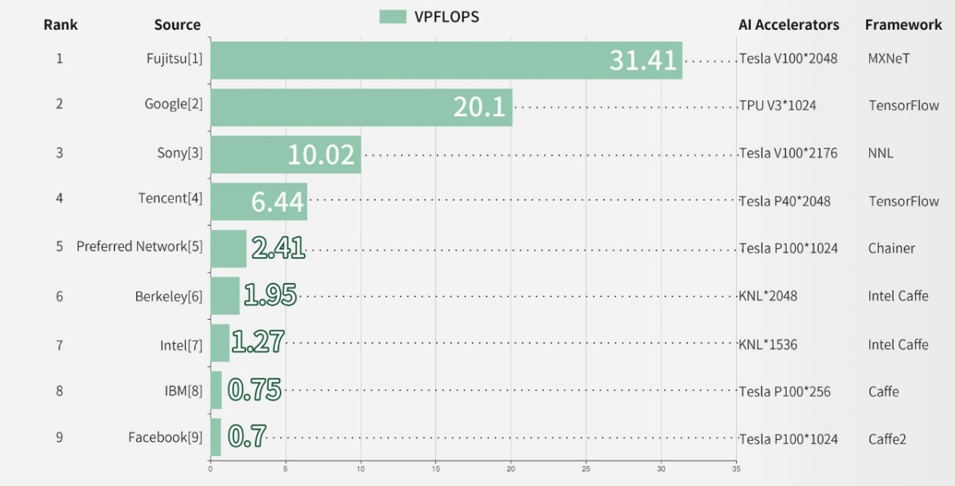 图:HPC AI500 VFLOPS排名
图:HPC AI500 VFLOPS排名
从 HPC AI500 排名来看,富士通、谷歌和索尼分列前三,腾讯位列第四。
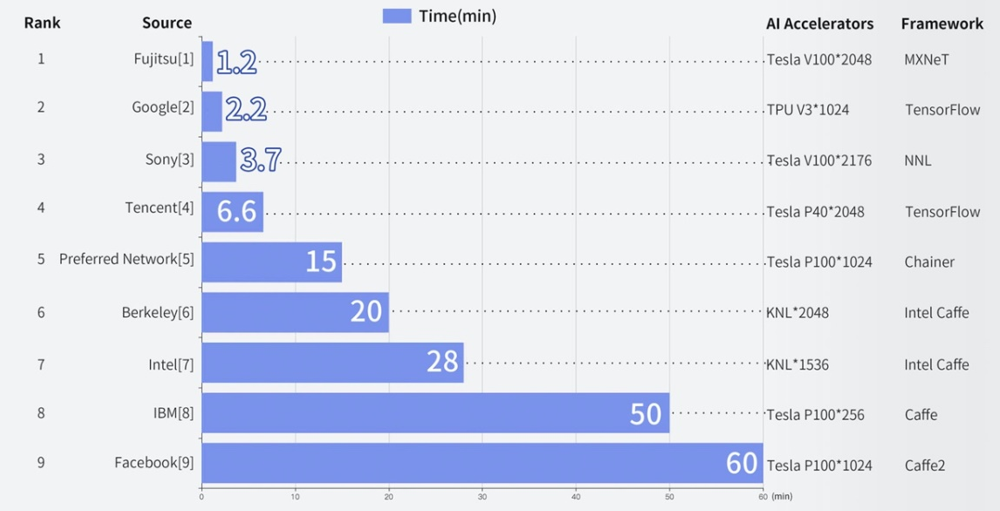 图:在不同超级计算机上训练人工智能模型所需的时间
图:在不同超级计算机上训练人工智能模型所需的时间
最快的富士通依靠2048块TeslaV100 GPU和新颖的通讯算法优化在1.2分钟完成了图像分类模型训练。
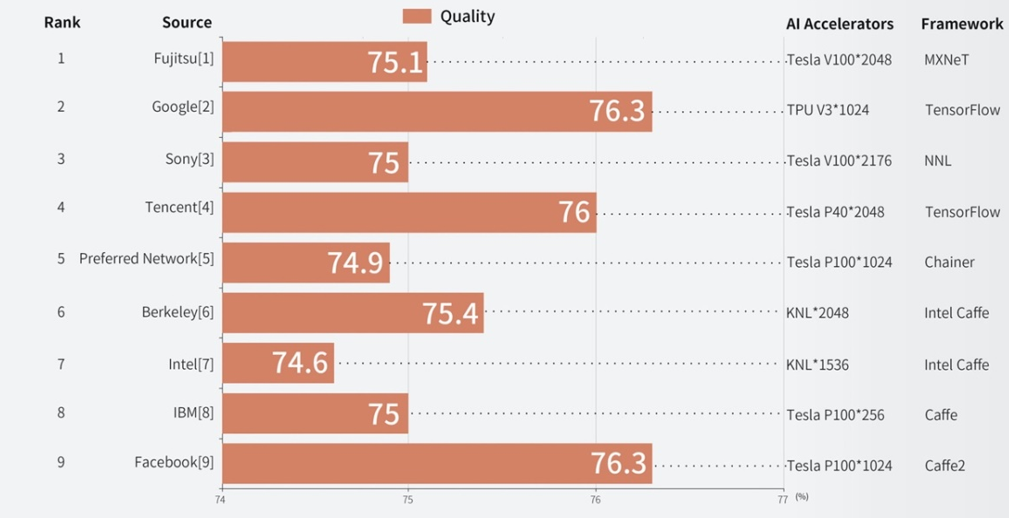 图:在不同超级计算机上训练人工智能模型达到的精度
图:在不同超级计算机上训练人工智能模型达到的精度
目前,中、美、日包揽了榜单的前九名,并且都在加大投入,争夺智能超计算机的主导权,但谁都没有确立真正的领先地位。
大会同时还发布了智能芯片性能榜单,该排行榜从最全面的人工智能性能评价标准 AIBench 中选择了三个代表性负载:图像分类、目标检测和学习排序 进行测试。
基于这些测试,对20多款主流人工智能芯片进行了性能排名:
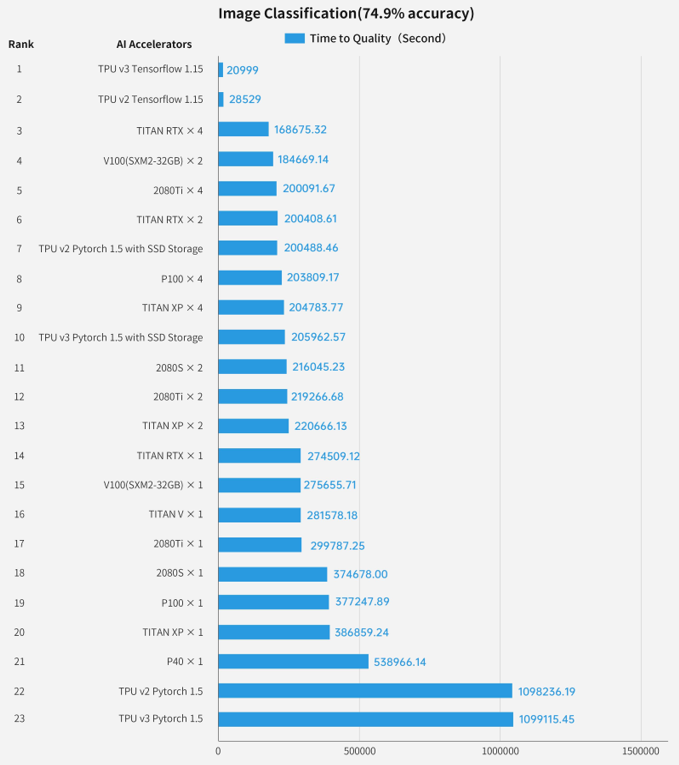 图:智能芯片排行榜,使用图像分类负载测试
图:智能芯片排行榜,使用图像分类负载测试
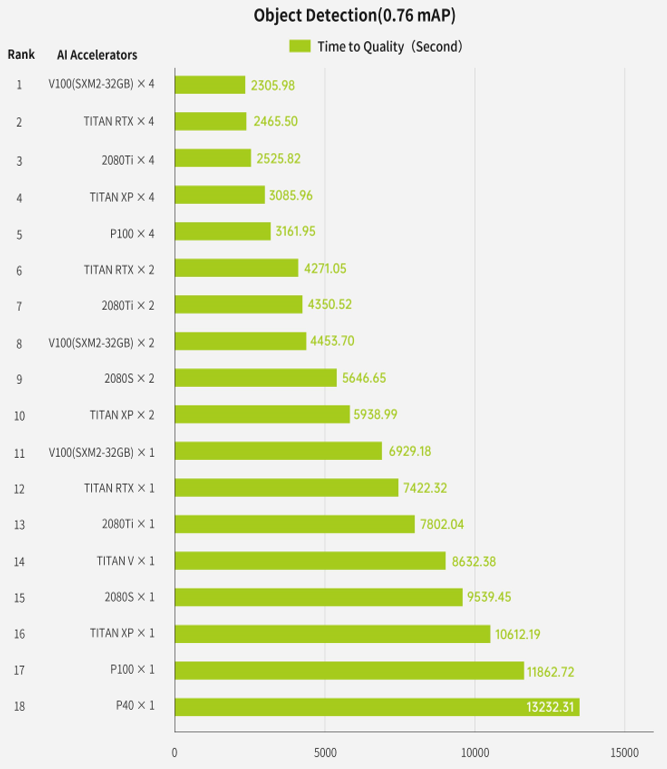 图:智能芯片排行榜,使用目标检测负载测试
图:智能芯片排行榜,使用目标检测负载测试
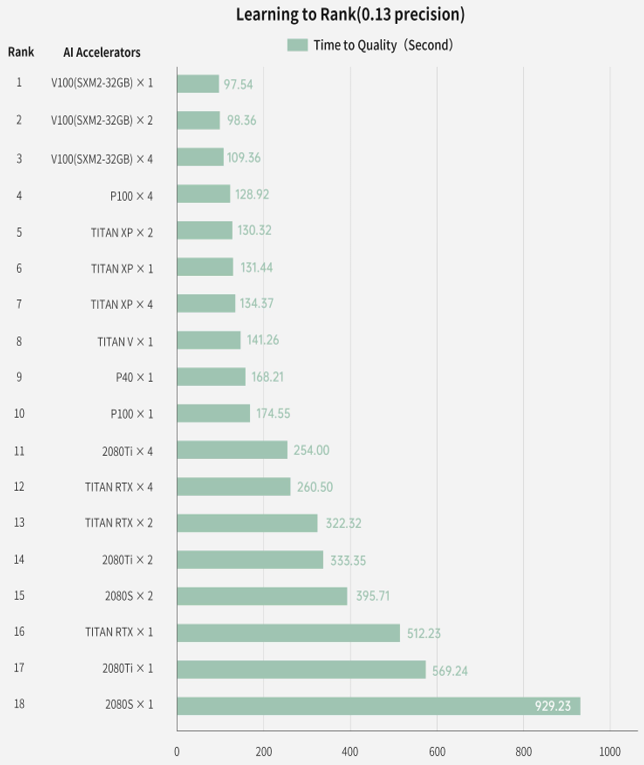 图:智能芯片排行榜,使用学习排序负载测试
图:智能芯片排行榜,使用学习排序负载测试
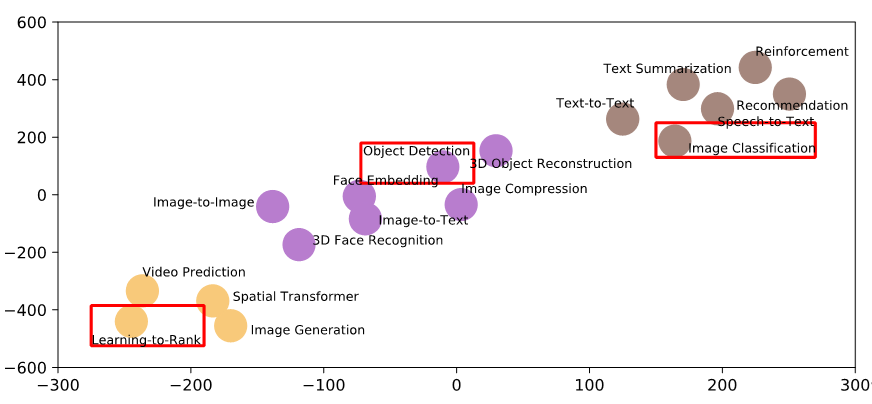
基于这些测试,对近20款主流人工智能芯片进行了性能排名。 最后,还使用 K-Means 对AIBench 全部负载的系统特征进行聚类,并使用 t-SNE 展示聚类结果:
智能超算榜单深度分析:我国AI芯片软件有点「头重脚轻」
智能超算榜单深度分析:我国AI芯片软件有点「头重脚轻」
通过对榜单的分析,我国智能超级计算产业的发展面临以下机遇和挑战:
1、未来随着机器的进一步性能提升,有可能在数百毫秒内完成模型的训练(学习),从而有望从速度上追赶人类的学习能力。这将使得智能超级计算机真正成为国之利器。但这需要从体系结构、系统软件、算法、应用等领域进一步开展基础研究和技术研发。
2、我国智能训练芯片的水平与国外还存在较大差距。目前国内上榜的系统均基于国外的芯片。其中,英特尔CPU配合英伟达GPU是当前智能超级计算机的主要选择。谷歌发布的TPU也展现出了相当的竞争力,以TPU为训练芯片构建的超算系统在榜单中排行第二名。
3、智能超级计算机需要均衡发展全方面的技术,智能芯片仅仅是构建系统的基础。首先,充分发挥芯片的性能需要基于特定芯片的体系结构开发基础操作(算子)库;其次,基于算子库的编程框架要求高效和易用,不仅能够最优化的调度算子,同时支持丰富的人工智能算法、模型和应用;最后,超级计算机往往由成千上万计算节点组成,节点间的通信的优化也至关重要。低效的通信往往会造成集群资源利用率低下,从而降低性能。
4、专有芯片是带来性能飞跃的一种有效途径。例如单个TPU v3(谷歌研制)在图像分类应用中只需要5.8个小时,而英伟达V100则需要76.6个小时,性能差异达13倍多。但是专有芯片对应用支持的通用性不足。虽然谷歌官方不断支持新的应用,但无法追赶上人工智能算法的变化。
5、智能软件生态与智能芯片同等重要。谷歌的TPU在训练图像分类模型时,使用自行研制的TensorFlow框架,只需要5.8个小时,但是使用开源框架PyTorch却需要将近13天。即使对PyTorch开发的程序进行优化,也仍然需要2天半,性能仍差10多倍。但PyTorch在GPU上获得的性能并不逊色于TensorFlow。从这个角度来说,孤立的评价智能芯片或者系统框架的性能会误导用户。
6、我国智能芯片软件生态薄弱,存在头重脚轻的现象。尽管我国在人工智能应用方面有着大量的人力投入,但在人工智能系统软件、编译、通讯库等领域投入严重不足。百度、华为等国内厂商推出的深度学习框架,流行度远远不如国外的TensorFlow和PyTorch等。
中科院领衔AIBench硬刚MLPerf,基准测试能由中国主导吗?
中科院领衔AIBench硬刚MLPerf,基准测试能由中国主导吗?
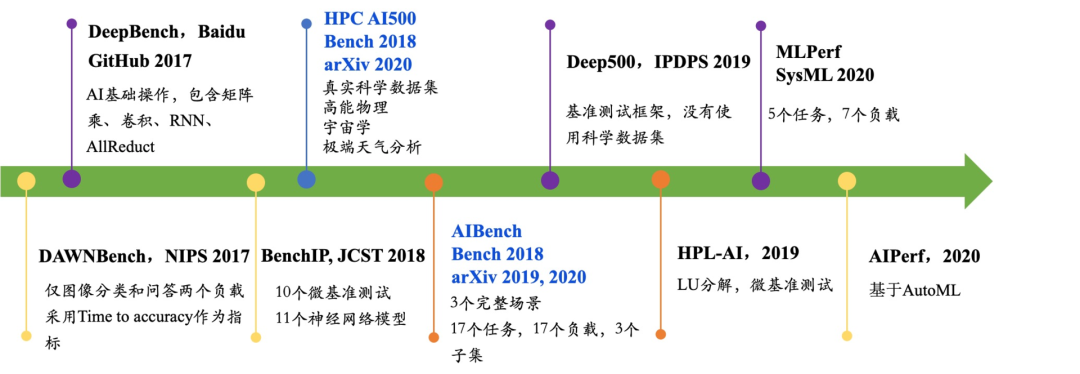 图:国际和国内主要人工智能标准发展时间轴
图:国际和国内主要人工智能标准发展时间轴
国际测试委员会(BenchCouncil)是一个非营利性的国际标准组织,旨在促进源芯片、人工智能、大数据和区块链等新技术的评价、验证、研讨、孵化和推广。
国际测试委员会发布的人工智能测试标准(HPC AI500 和 AIBench),中科院计算所都起着主导作用。
从时间上来看,与图灵奖得主David Patterson参与的斯坦福、Google、哈佛的联合项目 MLPerf 是同一时期的工作,由于有直接的竞争关系,这些标准屡屡遭遇坎坷。

从论文提交以及 ArXiv 上公开的时间来看,AIBench 等标准均早于 MLPerf。
AIBench 在提交给体系结构领域权威会议HPCA 2020工业版审稿时,4个审稿人同时都同意接受,但最后主席以作者不是来自工业界的错误理由直接拒稿。作者向HPCA委员会申述,程序委员会主席两次变更理由。
同样,另外一篇论文投稿到体系结构领域权威会议 Micro 2020,三个评阅人同意录用。尽管论文获得高分,最终也被拒绝。

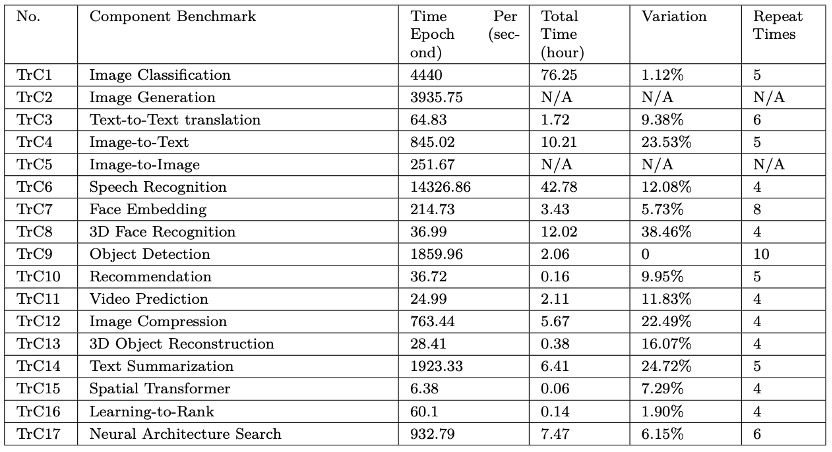 图:对AIBench 17个负载进行的可重复性测试。表格从左至右依次为负载的编号、负载名、遍历一次数据所需时间、训练总时间、多次运行中训练总时间的差异。从图中可以看出,随机性最高的算法3D Face Recognition 高达38.46%。AutoML的核心算法Neural Architecture Search达到了6.15%。HPC AI500选择的两个算法Image Classification和Object Detection随机性最低。
图:对AIBench 17个负载进行的可重复性测试。表格从左至右依次为负载的编号、负载名、遍历一次数据所需时间、训练总时间、多次运行中训练总时间的差异。从图中可以看出,随机性最高的算法3D Face Recognition 高达38.46%。AutoML的核心算法Neural Architecture Search达到了6.15%。HPC AI500选择的两个算法Image Classification和Object Detection随机性最低。IEEE Fellow和基准测试大拿,给AIBench打几分?
IEEE Fellow和基准测试大拿,给AIBench打几分?

