
人像抠图已经满足不了研究者了,这个研究专门给动物抠图!
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
| 编辑:魔王
作者:Jizhizi Li、Dacheng Tao等
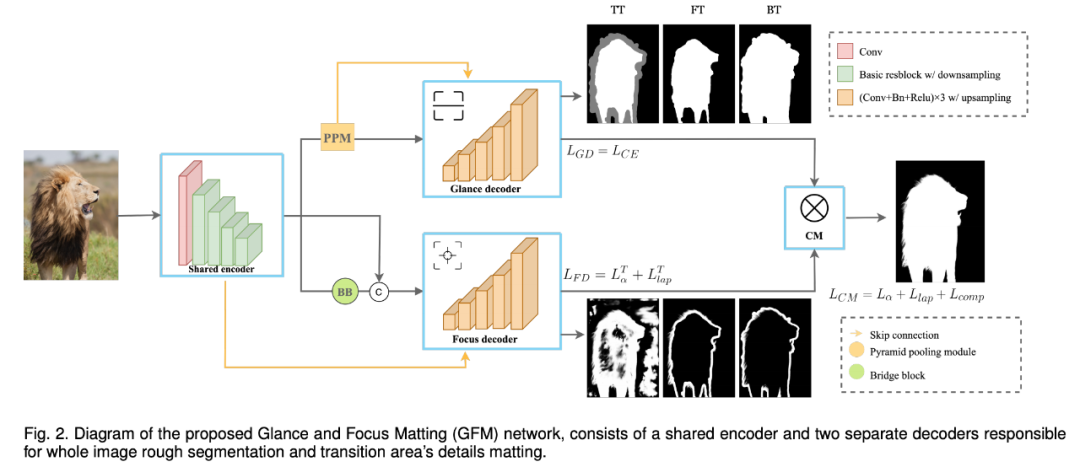
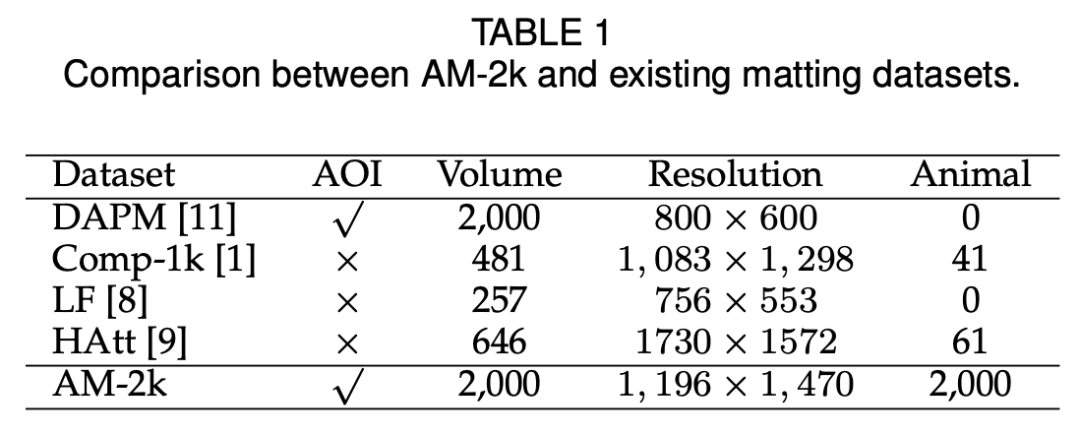
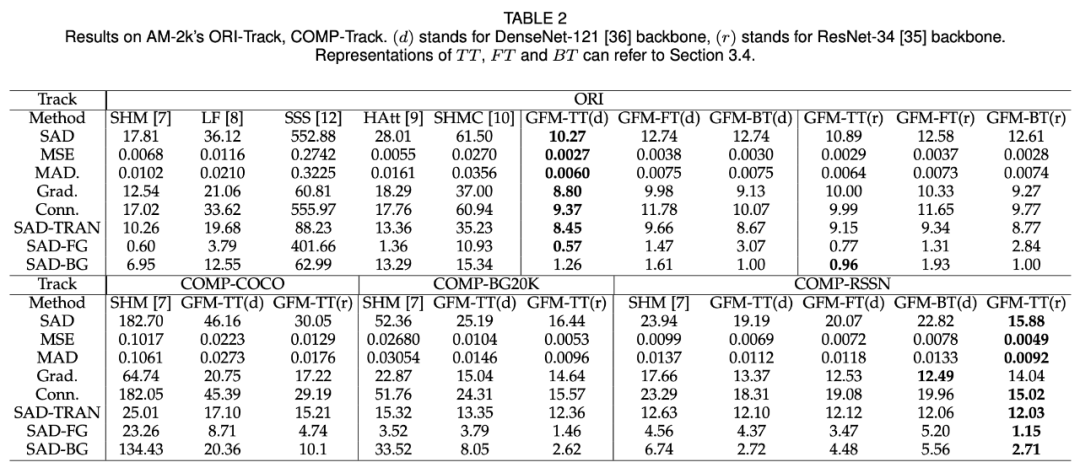
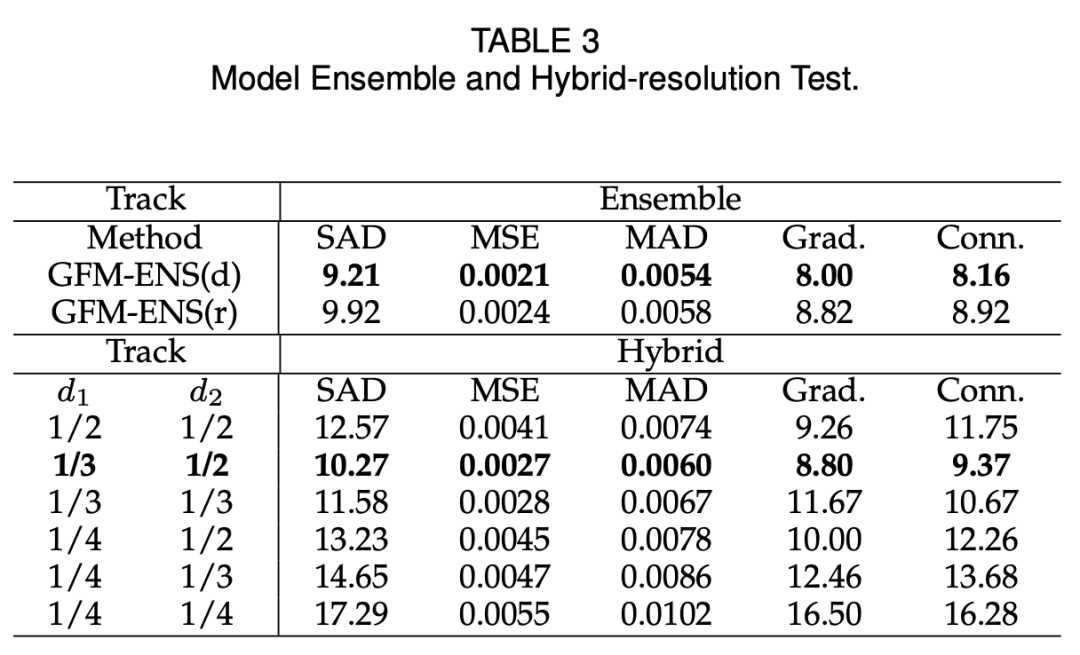
相比于人像抠图,长相各异、浑身毛茸茸的动物似乎难度更大。IEEE 会士 Jizhizi Li、陶大程等人开发了一个专门处理动物抠图的端到端抠图技术 GFM。






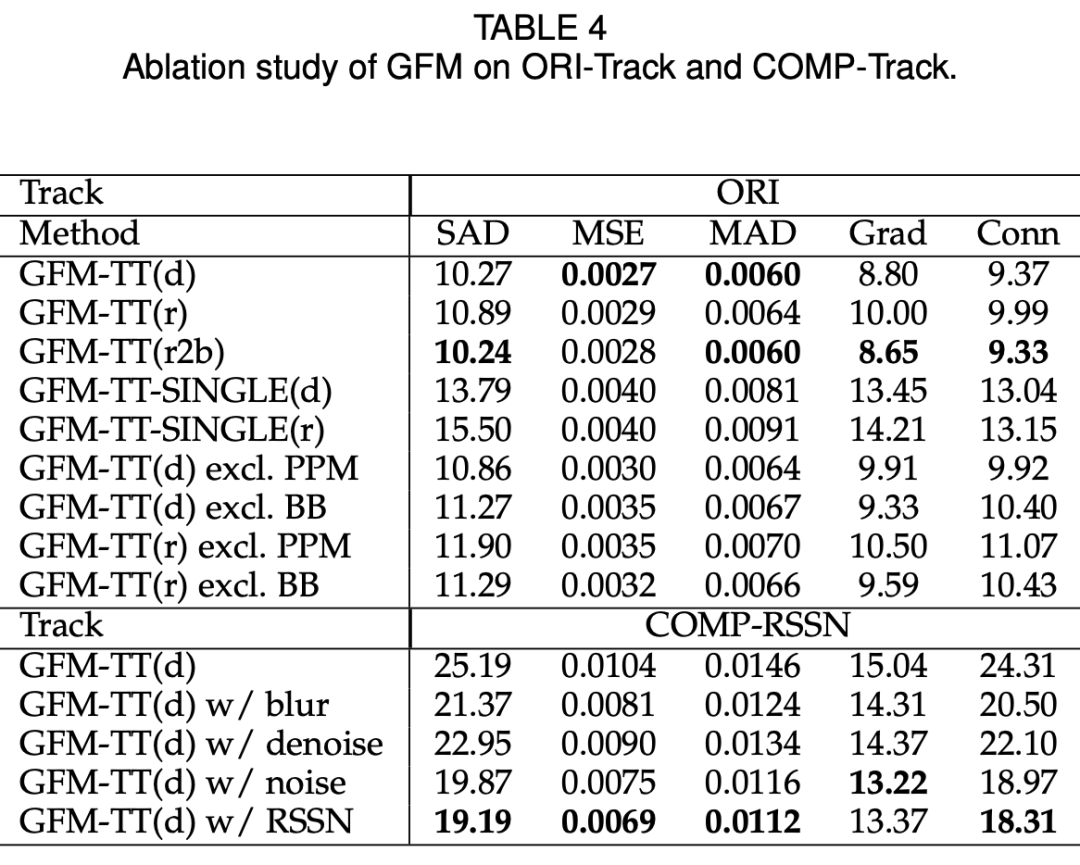
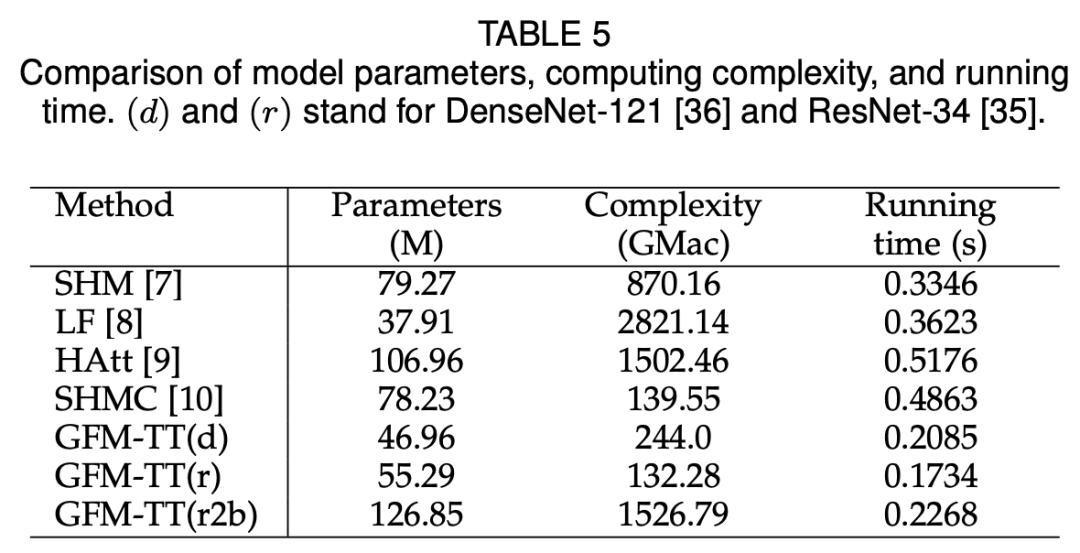
论文地址:https://arxiv.org/pdf/2010.16188v1.pdf
GitHub 地址:https://github.com/JizhiziLi/animal-matting
评论