
一个小故事,看懂MySQL索引原理!
我是小M,我在卡拉巴拉星球。
我喜欢数据,我立志成为一个数据管理者。
所以我来 Y 公司应聘,听说他们的数据量挺大的。
面试过程还是挺简单的。
我用 007 这三个数字就轻易打败了一堆吹嘘 996 的应聘者。
此刻,我独领风骚。
1
今天是我第一天上班,我笔直地坐在工位上,等着老板的宠幸。
下午两点。
Y 老板推门而入,打着哈欠看着我:“007,你背有问题?坐得这么直?”
“老板你好,我叫小M,不是叫 007 ,007 是我对公司的热爱,是我的毕生....”
“打住打住,看到你前面办公桌上十几条数据了么?”
“你的任务就是管理好它们,这些数据随时会增加、查阅、删除、更新的哦。”
我激动着、颤抖着回答:“Yes,Sir!”
2
花了10分钟的时间,我把桌上的数据都扫视了一遍。
是的,没错,就十几条数据我花了十分钟。
因为这是我的第一份工作,我热爱!
这些数据都来自一个叫 User 的部门,它们都有一样的结构:
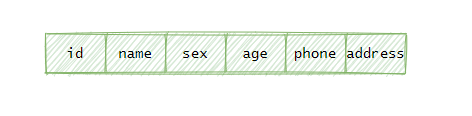
这堆数据的 ID 都是有规律的,我想着就按顺序把它排排坐,我用链表将它们相连。

每次查找数据,我从头开始遍历往后找就行了,有序,简单。
我真是个小天才。
就这样日复一日,年复一年,User 的数据在不断的增加,现在已经多达百条了。

这个链表也越来越长,每次老板来找我要数据,我查找的时间也越来越慢。
而且不仅是大老板,我发现好多小老板也来找我要数据。
我快要累死了,我的腰渐渐地也直不起来了。
3
5月1号深夜,今天是劳动节。
我依旧在公司加班。
我想不能再这样下去了,是时候祭出我的秘密武器了!
只有在夜深人静一个人的时候,我才能召唤它!
螺蛳粉!

没错,就是它!
因为我发现,嗦了螺蛳粉之后,我的脑子特别清晰,思维特别地发散。
为此,我还特意去医院检查了下脑子,医生说从片子上看的话一切正常,不过从感觉上看我可能不太正常。
不管了,反正我知道,螺蛳粉确实能赋予我通透的头脑。
因为,此时我的脑子已经开始动起来了!
有了!
我忽然回想起,在大学里面有一门叫《数据结构》的课程里讲了二分法。
现在有近一千条有序的数据,我把它按每十条数据分为一组,于是我吭哧吭哧的一顿操作。
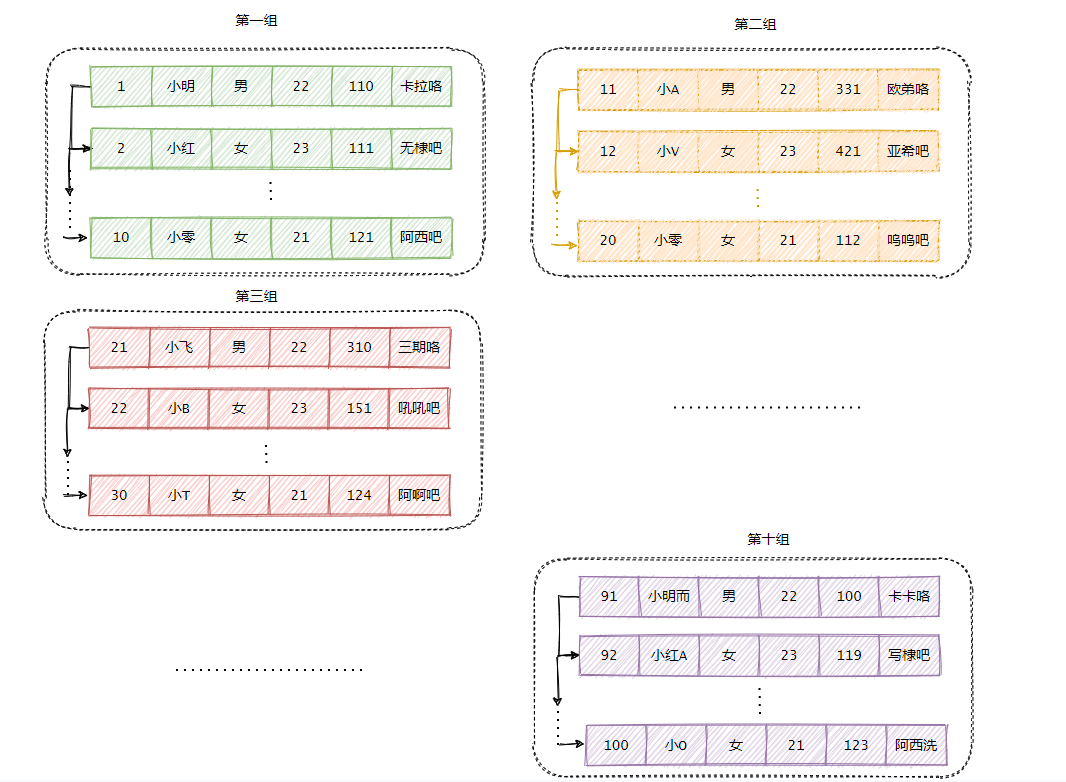
(为了美观,就画10组)然后我再为每一组都配置一个槽,每个槽记录了每组最大的那条记录的地址。
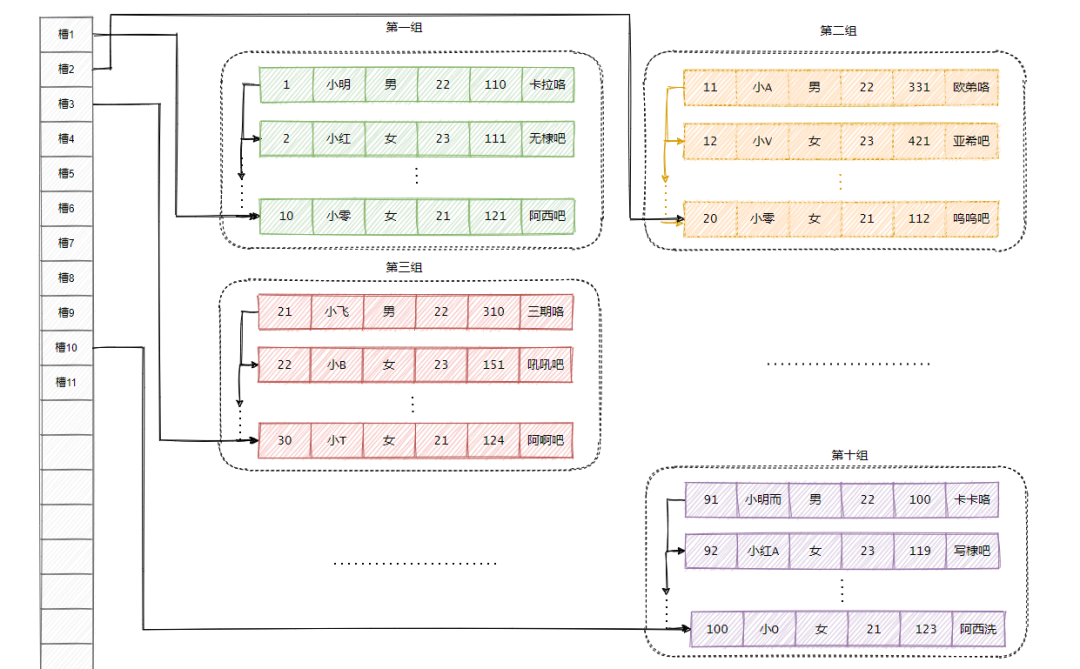
这样,我就可以通过二分法快速查找记录啦!
假设现在就10组数据,然后我要找 ID 等于 12 这条数据,我就:
先计算中间槽的位置 (1+10)/2=5,通过地址找到第五组,此时第五组ID是50,12<50,所以继续二分。(1+5)/2=3,通过地址找到第三组,此时第三组ID是30,12<30,所以继续二分。(1+3)/2=2,通过地址找到第二组,此时第二组ID是20,12<20,所以继续二分。(1+2)/2=1,通过地址找到第一组,此时第一组ID是10,12>10,现在能断定12在第二组。从图中看起来第一组和第二组是分开的?实际上地址是相连的,所以通过第一组最后一条数据,可以往后随着单向链表遍历,找到ID为12的这条数据。
是不是很方便?
总结的来说:
先通过二分法找到数据所在的槽。 然后再通过单向链表遍历得到数据。
在数据量很大的时候这种查找方式非常快速!
因为查找数据的时间复杂度从O(n)几乎简化成了O(lgn)!
我称之为页目录,我可真是个小天才呢!
4
就这样,日复一日,年复一年。
User 的数据量还在逐日增加。
我发现每次查询都需要掏出全部的名单来找。
我这小胳膊细腿的,都快抬不动了。
于是,在一个月黑风高的夜晚,我又掏出了螺蛳粉。
灵光乍现!
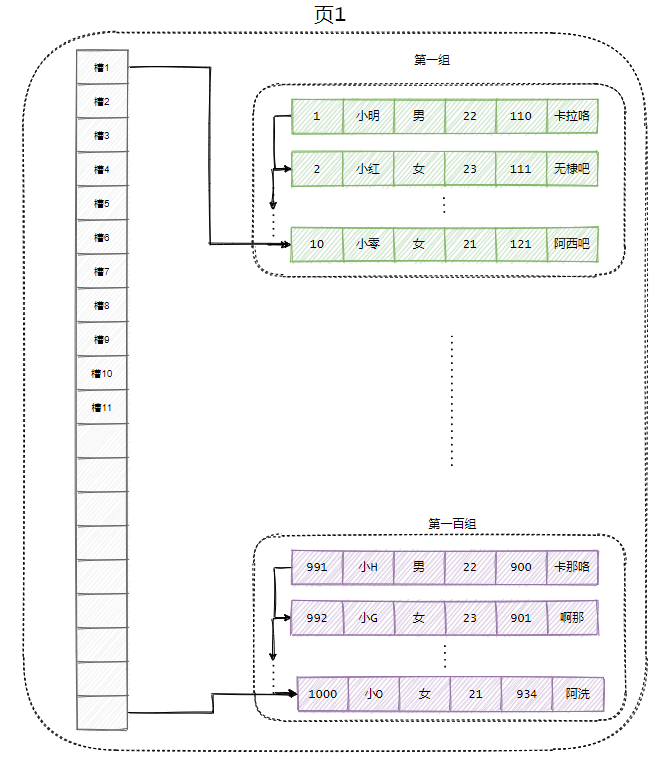
我以一千个数据为一个界限来分割数据,我将每一千个数据称之为页。
没错,我又想出了 idea,我将所有数据分为一页一页,每页之间用双向链表相连。
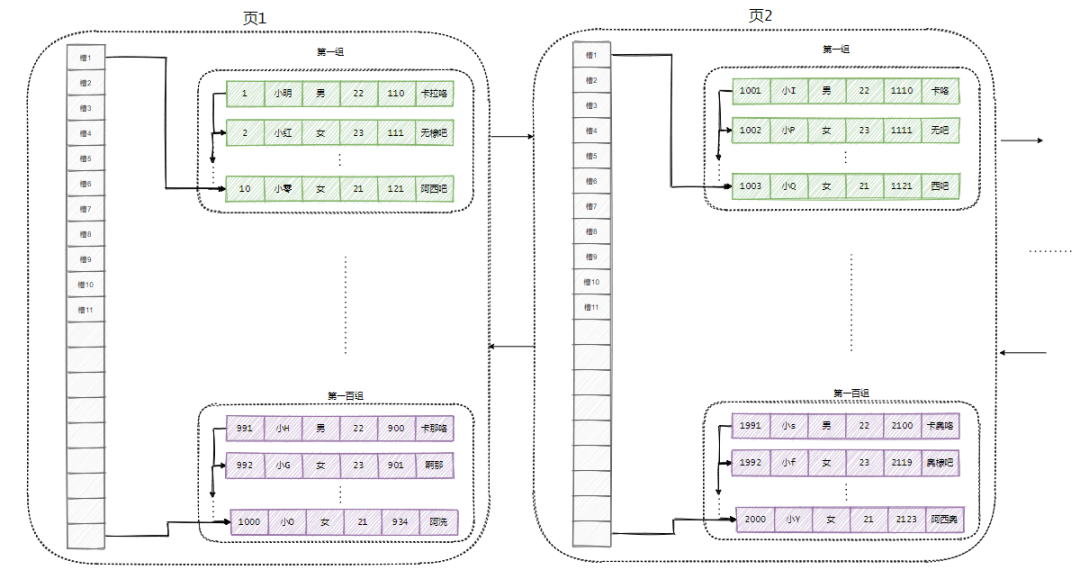
这样每次查询,我就不需要一次把有所数据都拉出来,我可以一页一页翻阅过去。
当然,页内部还是按照刚才那样分组访问。
现在我是这样查找数据的:
每次查数据我从第一页开始找。 然后按照页内查找的方式二分去查数据,找不到就通过链表访问下一页。
因此,访问速度并没有变快,只是每次不需要把数据全部捞出来,只要一页一页的捞。
我的胳膊得到了解放。
5
公司越来越大,User 的数据爆炸性增长。
分的页也越来越多,老板和小老板们开始抱怨了。
老板说,“我让你找个人,你找了1小时?你今年年终奖还想不想要了!”
“唉,那个人在最后一页,我翻的要死才翻到,我太难了!”
虽说在心里抱怨,但是我知道这样下去不是办法。
头可断血可流,年终奖不可少!
别问,问就是螺蛳粉!
果不其然,螺蛳粉是无敌的。
解决法子有了!
每个页都标上独一无二的页号。
参考书本目录的设计,我还专门搞了一个页,页里面的存储就是目录!
我称它为目录页。
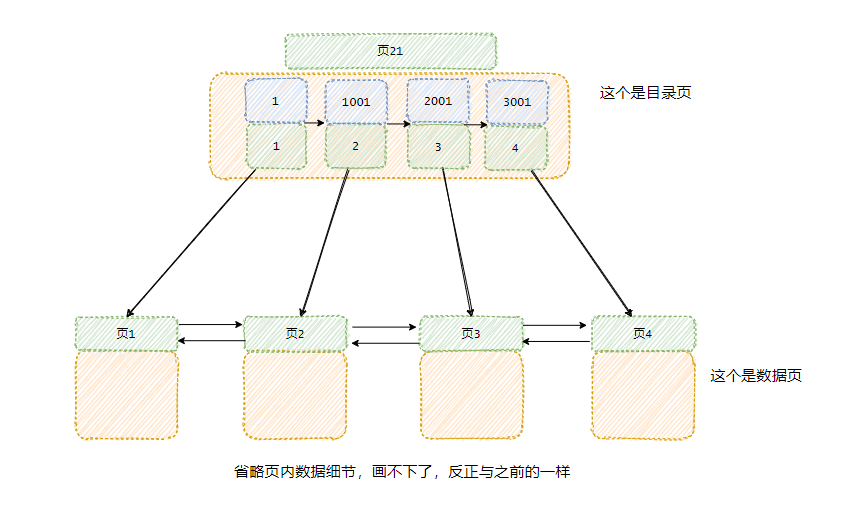
你看,这样我就能通过这个目录页找到对应的数据页。
比如:我现在要找 ID 为 500 的那条数据。
我遍历目录页数据就可以知道该条数据在页1。 然后就开始在页内通过老套路二分来查找数据!
可能有人觉得,目录页也是有大小的呀!装不下怎么办?
没事,和数据页一样,新增页呗!
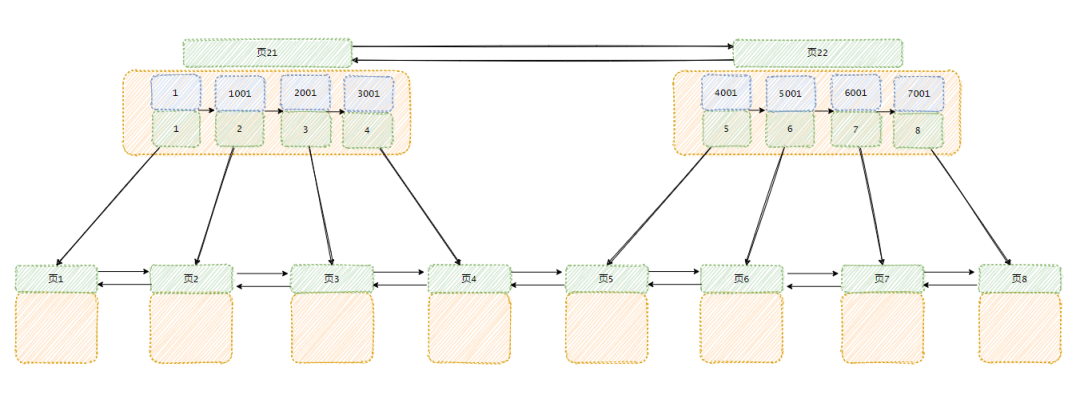
可能有人会问,那目录页多了,查找目录页也会变慢的呀!
你说的没错,但这可难不倒我这个小聪明!
我们可以再搞一级目录,我称之为目中目(开个玩笑~)!
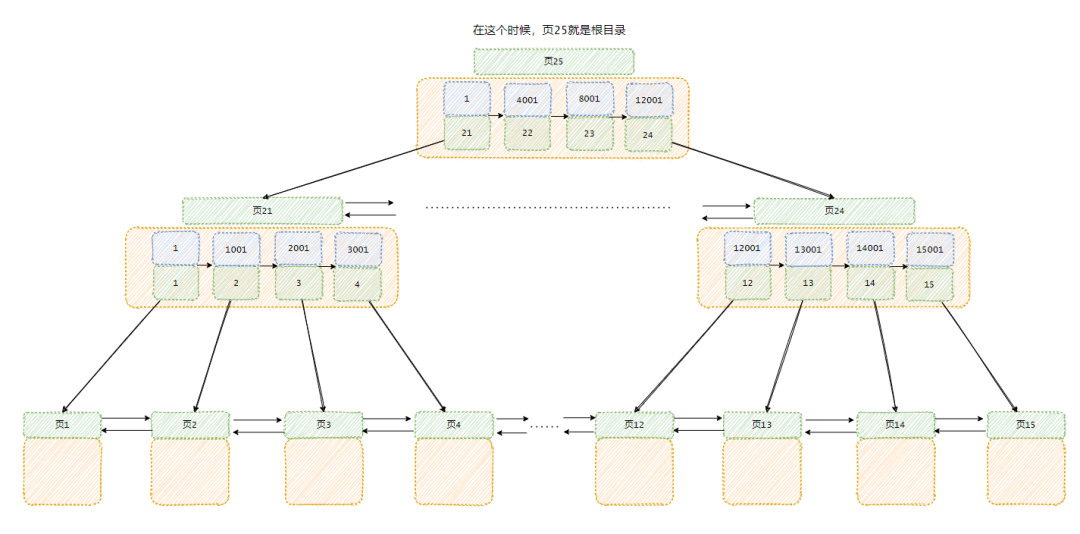
这样,每次我从根目录开始查询,只要几次查询我就能找到想要的数据!
我称这整一个为索引!

Y 老板看到了我的设计之后,拍了拍我的脑袋,“007,有一手啊,我看你这结构看着像一棵树,我这个人又喜欢吹牛 B,你看这玩意叫 B 树怎么样?”
“不行老板,我觉得这 B 格不够高,要么叫B+树吧?”
“行啊,007,年终奖我提前发给你!”
“叮铃,支付宝到账,0.1元。”
我:“...........”
“对了 007 ,这 User ID 太不好记了,下次我打算只告诉你名字,让你找。”
我内心:“@#%^&%........”
故事未完,敬请期待 ~
哈哈,第一次写这类故事,有点意思。
这篇主要写的是关于MySQL InnoDB 聚簇索引的设计,阐述了 MySQL 的数据到底是如何查找的。
我记得之前阿里的面试官就问过我这个问题,让我说说数据在索引上是如何找到的,越细越好。
嘿嘿,这下知道了吧。
不过,由于故事的原因,有些描述都是不准确的,比如上面说的什么每一千条数据分为一页。
我下面统一更正一下并补充一些点,看好了啊!
MySQL 一页默认16 KB,所以不是按数量的,是按总的记录数所占的空间。 页内记录是单向链表连接,页之间是双向链表连接。 当一页数据存满了之后需要进行页分裂,也就是拆分下记录变成两个页。 页分裂操作也可能导致多个页都满了,比如你往一个页中间插入数据,挤出一条数据到下一页,然后下一页也满了,发生级联,影响性能,所以建议主键有序,这样不会往中间的页插入数据。 MySQL页内默认会有一条最大记录和一条最小记录不存储数据,就是这样设计的,和链表dummy节点类似。 一页除了存储数据还有一些元数据,比如FileHeader、PageHeader等等,太细了讲了你现在记得住,过两星期也记不住,我也一样。 一条记录也有很多细节。
像大部分人可能知道 InnoDB B+树索引的设计。
也能说出为什么要用 B+ 树,但是很少会说到页内的二分查找。
其实这样的设计很常见,像 Kafka 的索引也采用了二分,一般数据量大了,数据有序的情况都会上二分。
下次面试官问你,你就把这个跟他说说,面试官会觉得,啧啧真细啊。
对了,我上述讲的只是索引结构大致布局,想要看详细的可以看《从根儿上理解 MySQL》,比如 FileHeader 有什么字段啊啥的。
不过,我个人觉得没必要这么细,反正记不住,精髓掌握的即可。
如果你喜欢这样故事类的文章,可以留言让我知道,我之后多往这方面写。