
PySpark——开启大数据分析师之路
导读
近日由于工作需要,突击学了一下PySpark的简单应用。现分享其安装搭建过程和简单功能介绍。

了解PySpark之前首先要介绍Spark。Spark,英文原义为火花或者星火,但这里并非此意,或者说它就没有明确的含义。实际上"名不副实"这件事在大数据生态圈各个组件中是很常见的,例如Hive(蜂巢),从名字中很难理解它为什么会是一个数仓,难道仅仅是因为都可用于存储?
当然,讨论spark名字的含义并无意义,我们需要知道的是Spark是大数据生态圈中的一个分布式快速计算引擎,这其中包含了三层含义:分布式、快速、计算引擎。分布式意味着它支持多节点并行计算和备份;而快速则是相对Hadoop中的MapReduce计算框架而言,官网号称速度差距是100倍;计算引擎则描述了Spark在大数据生态中定位:计算。
存储和计算是大数据中的两大核心功能。
大数据框架,一般离不开Java,Spark也不例外。不过Spark并非是用Java来写的,而是用Scala语言。但考虑Scala语言建立在Java基础之上,实际上Scala是可以直接调用Java的包的,所以从这点来讲Spark归根结底还是要依赖Java,自然环境依赖也需要JDK。也正是基于这些原因,Spark的主要开发语言就是Java和Scala。然后随着数据科学的日益火爆,Python和R语言也日益流行起来,所以Spark目前支持这4种语言。当Spark遇到Python就变成了PySpark,这也是我们今天介绍的主角。
Spark目前最新版本是3.0,于今年6月16日正式发布release版。
一般而言,进行大数据开发或算法分析需要依赖Linux环境和分布式集群,但PySpark支持local模式,即在本地单机运行。所以,如果为了在个人PC上练习PySpark语法功能或者调试代码时,是完全可以在自己电脑上搭建spark环境的,更重要的windows系统也是可以的!

实际上,安装PySpark非常简单,仅需像安装其他第三方Python包一样执行相应pip命令即可,期间pip会自动检测并补全相应的工具依赖,如py4j,numpy和pandas等。这里py4j实际上是python for java的意思,是Python和java之间互调的接口,所以除了pip命令安装PySpark之外还需配置系统的jdk环境,一般仍然是安装经典的JDK8版本,并检查是否将java配置到系统环境变量。相应的检验方法是在cmd窗口中键入java -version,当命令可以执行并显示正确的版本时,说明系统已完成java环境搭建。这是为PySpark运行提供了基础。

所以总结一下,安装pyspark环境仅需执行两个步骤:
安装JDK8,并检查系统配备java环境变量
Pip命令安装pyspark包
from pyspark import SparkContext
sc = SparkContext()
rdd = sc.parallelize([1, 2])
rdd.getNumPartitions()
# 输出4
Spark作为分布式计算引擎,主要提供了4大核心组件,它们之间的关系如下图所示,其中GraphX在PySpark中暂不支持。
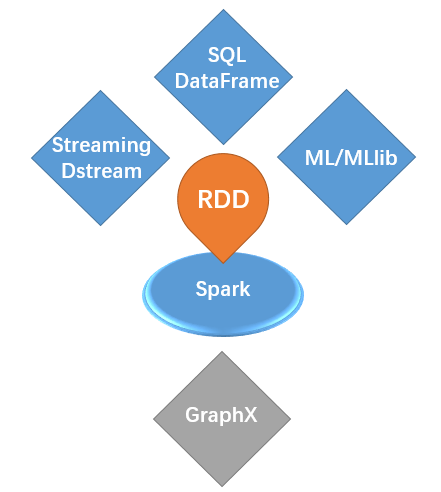
RDD(Resilient Distributed DataSet,弹性分布式数据集)是Spark中的核心数据结构(Spark core),是完成分布式任务调度的关键,从名字缩写中可以看出其有3大特性:弹性,意味着大小可变、分区数量可变;分布式,表示支持多节点并行处理;数据集,说明这是一个特殊的数据结构。
进一步的,Spark中的其他组件依赖于RDD,例如:
SQL组件中的核心数据结构是DataFrame,而DataFrame是对rdd的进一步封装。值得一提的是这里的DataFrame实际上和Pandas或者R语言的data.frame其实是很为相近的,语法、功能、接口都有很多共同之处,但实际上这里的DataFrame支持的接口要少的多,一定程度上功能相对受限;
Streaming组件中的核心数据结构是Dstream,即离散流(discrete stream),本质就是一个一个的rdd;
PySpark中目前存在两个机器学习组件ML和MLlib,前者是推荐的机器学习库,支持的学习算法更多,基于SQL中DataFrame数据结构,而后者则是基于原生的RDD数据结构,包含的学习算法也较少
了解了这些,PySpark的核心功能和学习重点相信应该较为了然。后续将不定期推出SQL和ML两大组件的系列要点分享。
相关阅读: