
中科院自动化所副所长刘成林教授:模式识别,从初级感知到高级认知

来源:AI科技评论 本文约8500字,建议阅读10+分钟
本文与你分享模式识别的内涵、演化、研究现状以及未来值得研究的方向。


一、什么是模式识别?
一类是狭义的,就是根据某种客观标准对目标进行分类和标记,这里主要是指分类。 另一类是广义的,就是对数据中的目标、现象或事件进行分类或者描述。这个描述就是一个比较复杂的感知过程,因为描述实际上要对模式的结构进行理解。
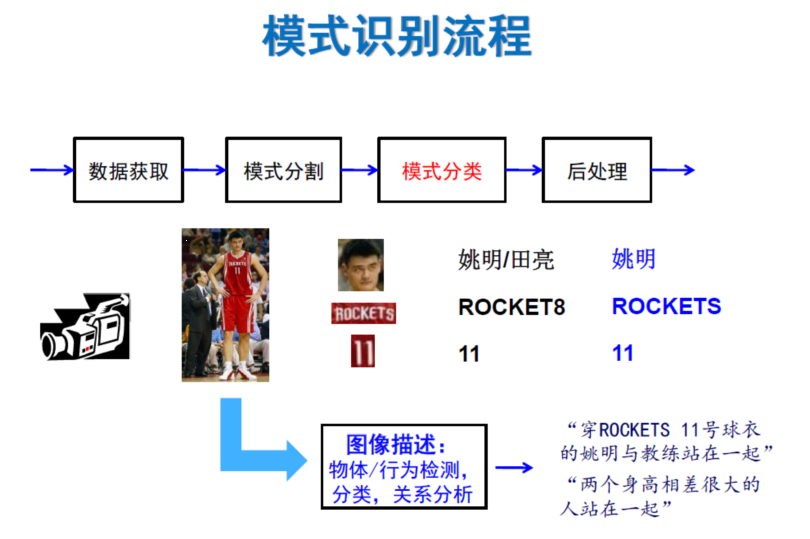


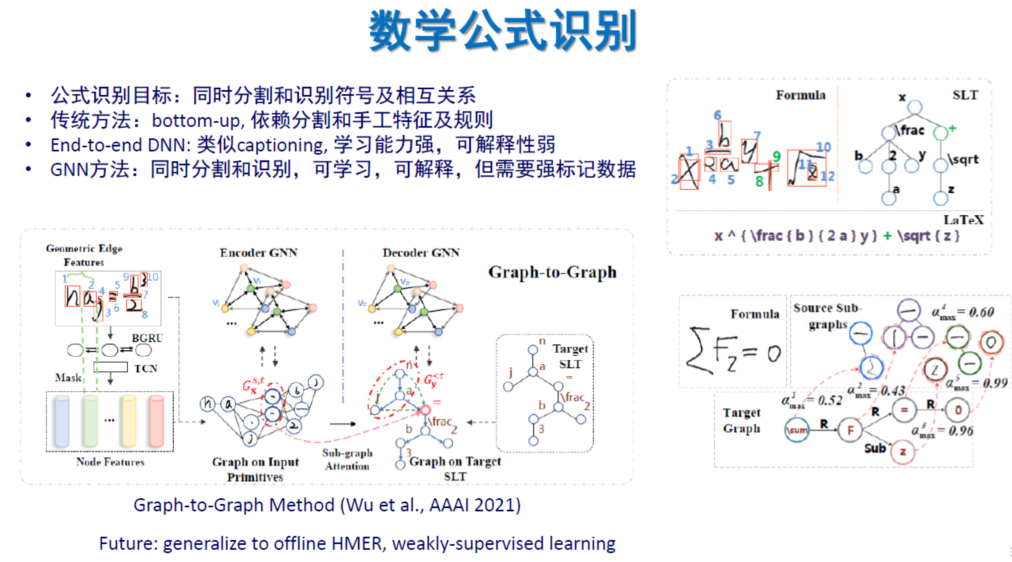
结构表示模型。目前主流的结构是神经网络+结构(如Graph或图神经网络),可以扩展到更多结构形式,如树、贝叶斯网等。跨模态学习(如视觉+语言)中往往需要用到结构表示,并且可结合符号知识。
结构模型学习。包括图匹配度量学习、半监督学习、弱监督学习、开放环境增量学习、小样本学习、领域自适应、跨模态学习等。目前流行的自监督学习可以为结构学习提供预训练特征表示模型,从而大为简化结构模型的学习。
语义理解应用。模式结构理解或语义理解很多时候要与应用结合起来,比如智能机器人或无人驾驶等,它的感知要与认知紧密结合、与决策结合,因为要把视觉信息结合背景知识才能做一个准确判断。
编辑:黄继彦
校对:林亦霖
评论