
啊?排序字段的大小也会影响排序性能???面试官都惊了!!
来源:juejin.cn/post/6957281846593847309
导读
作为一个交友平台,我们还是以它的核心功能,即搜索用户来开启今天的分享。
假设我们要搜索年龄在18到24之间的女生,同时要求按年龄排序,如果平台注册用户达到千万级,那么,我们一般会对这个搜索结果分页,避免结果页加载很慢,所以,为了实现这个功能,基于用户表,我们会写这样一条SQL:
SELECT * FROM user WHERE age >= 18 AND age <= 24 AND sex = 0 ORDER BY age LIMIT 0, 50
对索引实践有较多经验的同学应该已经想到了,如果我要在用户规模达到千万级时,还要保证这条SQL的查询效率,我们肯定会加一个覆盖索引index_age_sex(age,sex),保证查询大规模用户时,性能杠杠滴!
那么,为什么使用覆盖索引,查询性能就好呢?所以,今天我就先讲解一下什么是覆盖索引及MySQL使用覆盖索引查找记录的过程,了解这个过程后,我们就知道为什么使用覆盖索引查找更快了。
覆盖索引
覆盖索引就是将排序字段加入索引中,保证该索引树的节点包含排序字段。
对于覆盖索引index_age_sex(age,sex)是如何查找的,通过这个查找过程我们会发现很重要的一点:
index_age_sex索引树的叶子节点包含排序字段age,保证了age自身已排序。
所以,MySQL只需要2步就可以查找到满足条件的有序结果:
遍历
index_age_sex索引树中的叶子节点,找到满足条件的记录主键id通过上面的主键id到聚簇索引的叶子节点查找对应的记录
正是排序字段在索引树叶子节点有序,减少了不必要的排序过程,所以,大大提升了SQL查询的效率。
如果此时,通过上面的用户搜索,我找到了喜欢的女生,然后关注了她,彼此通过平台的聊天功能聊得也很好。但是,之后有一段时间工作忙,没有及时再跟对方有更多的沟通,忙完之后,你想再找她聊天,由于你只是模糊记得她的账号中的一部分,同时,记得她的昵称前半部分字母比较小,于是,你试图通过在自己关注列表中搜索昵称关键字来快速查找她,此时的查询SQL变成:
SELECT * FROM user WHERE user_name LIKE "%am%" AND age >= 18 AND age <= 24 AND sex = 0 ORDER BY age, user_name LIMIT 0, 50
假设现在我们的用户表user中已经添加了索引index_un_age_sex(user_name,age,sex),表示给字段user_name、age和sex添加了一个联合索引index_un_age_sex,但是根据上面覆盖索引的查找过程,我们发现上面这条SQL,由于查询条件中user_name为字符串两端模糊匹配,所以,无法通过索引index_un_age_sex查找用户,即无法命中索引index_un_age_sex,这在大规模用户的场景下,势必影响查询性能。那么,此时,我们有什么办法解决这个问题呢?
我们先用explain语句来分析上面这条SQL,我们看到explain结果中出现了Using index condition; Using where; Using filesort,像下面这样:

Using index condition; Using where; Using filesort是什么意思?其实,这个关键字描述了这样一个过程:
MySQL先使用索引
index_age_sex过滤出部分用户记录,对应上面关键字中的Using index使用条件中的
user_name字段模糊匹配,从步骤1的结果中再过滤出部分用户记录,对应上面关键字中的Using where对上一步得到的用户记录进行排序,对应上面关键字中的
Using filesort
这下你大概知道Filesort是怎么一回事了。
Filesort
Filesort表示MySQL使用了临时文件对where条件过滤的中间结果进行排序。我们就以上面使用Filesort的SQL为例,看一下具体的排序过程:
1.命中索引index_age_sex(字段age和sex的联合索引),在索引树index_age_sex中查找age >= 18 AND age <= 24 AND sex = 0的用户记录。
2.顺序遍历上一步中的查找结果,查找满足user_name LIKE "%am%”的记录。
3.顺序遍历上一步中的查找结果并排序,这里MySQL使用了快速排序,MySQL给每个线程分配一块内存用于排序,这块内存区域叫做sort_buffer。关于快速排序,很多同学在大学里已经学过了,我就不详细讲解这个过程了,只说一下两种情况:
(1) 当SELECT中的字段 + 排序字段的值大小小于等于参数max_length_for_sort_data,在sort_buffer中写入全字段,然后,对排序字段排序。
比如:本章《覆盖索引》中的SQL,SELECT子句为*,假如SELECT中的字段 + 排序字段的值大小小于等于参数max_length_for_sort_data,即表全部字段大小总和小于等于参数max_length_for_sort_data,MySQL将user表中满足查询条件的记录的所有字段写入sort_buffer,然后,依次对字段age和username排序,最终得到排序后的完整结果。
(2) 当SELECT中的字段 + 排序字段的值大小大于参数max_length_for_sort_data,在sort_buffer中写入排序字段+主键ID,然后,对排序字段排序,最后,根据主键ID到聚簇索引取出对应记录。
比如:本章《覆盖索引》中的SQL,SELECT子句为*,假如SELECT中的字段 + 排序字段的值大小大于参数max_length_for_sort_data,即表全部字段大小总和大于参数max_length_for_sort_data,MySQL将user表中满足查询条件的记录age、username和id写入sort_buffer,然后,依次对字段age和username排序,排序后,根据主键id到聚簇索引获取对应记录。
对比上面两种排序的过程,我们发现采用下面的方案进行排序,会多一次回表(聚簇索引查找)的过程,如果聚簇索引在磁盘上,那么就会产生磁盘IO,影响性能。
所以,我们可以采用下面两个手段避免回表查询:
SQL中的SELECT部分中的字段尽量不要用
*,而是指定字段,确保SELECT中的字段 + 排序字段的值大小小于等于参数max_length_for_sort_data,这样MySQL就会采用上面的(1)方案排序如果一定要使用
*,那么,务必保证表中字段的总长度不超过max_length_for_sort_data,这样MySQL也会采用上面的(1)方案排序
那么,是不是只要保证SELECT中的字段 + 排序字段的值大小小于等于参数max_length_for_sort_data,排序性能一定是最好的呢?
假如本章《覆盖索引》中的排序字段username,我们设计它的长度为32字节和200字节,同时保证了SELECT中的字段 + 排序字段的值大小小于等于参数max_length_for_sort_data,那么,两种字段长度的设计对排序性能有什么不同的影响呢?
这时,我就不得不提一下这个排序比较的过程,通过这个过程的讲解,我来揭开上面这个问题的答案!
排序比较
MySQL对排序字段进行排序对比时使用了C函数库的memcmp,因为memcmap充分利用了64位CPU的特性,所以,性能非常高!为什么呢?
这里我就以64位CPU为例,看一下memcmp的比较过程,memcmp函数转化为汇编指令后,主要包含了下面这些过程:
通过MOV指令,从内存中读取用于比较的两个入参地址,并将地址分别写入两个rax寄存器 通过NOP指令,对上面的rax寄存器中的地址做内存对齐 通过CMP指令,对没有对齐的部分,单字节(byte)比较 通过CMP指令,针对对齐的部分,以32个字节为单位,通过冗余指令,做4次8字节(qword)比较,为什么以32字节单位,拆分4次比较两个入参地址?下面我会讲到。 通过CMP指令,针对步骤4中不足32个字节的部分,以8个字节为单位,做8字节(qword)比较 通过CMP指令,针对步骤5中最后剩余不足8个字节的部分,做单字节(byte)比较
我先以上面的第一步的MOV指令为例,看下指令在CPU中的处理过程。
下图是Intel的Nehalem处理器的内核架构,我们从上到下看一下MOV指令的处理过程: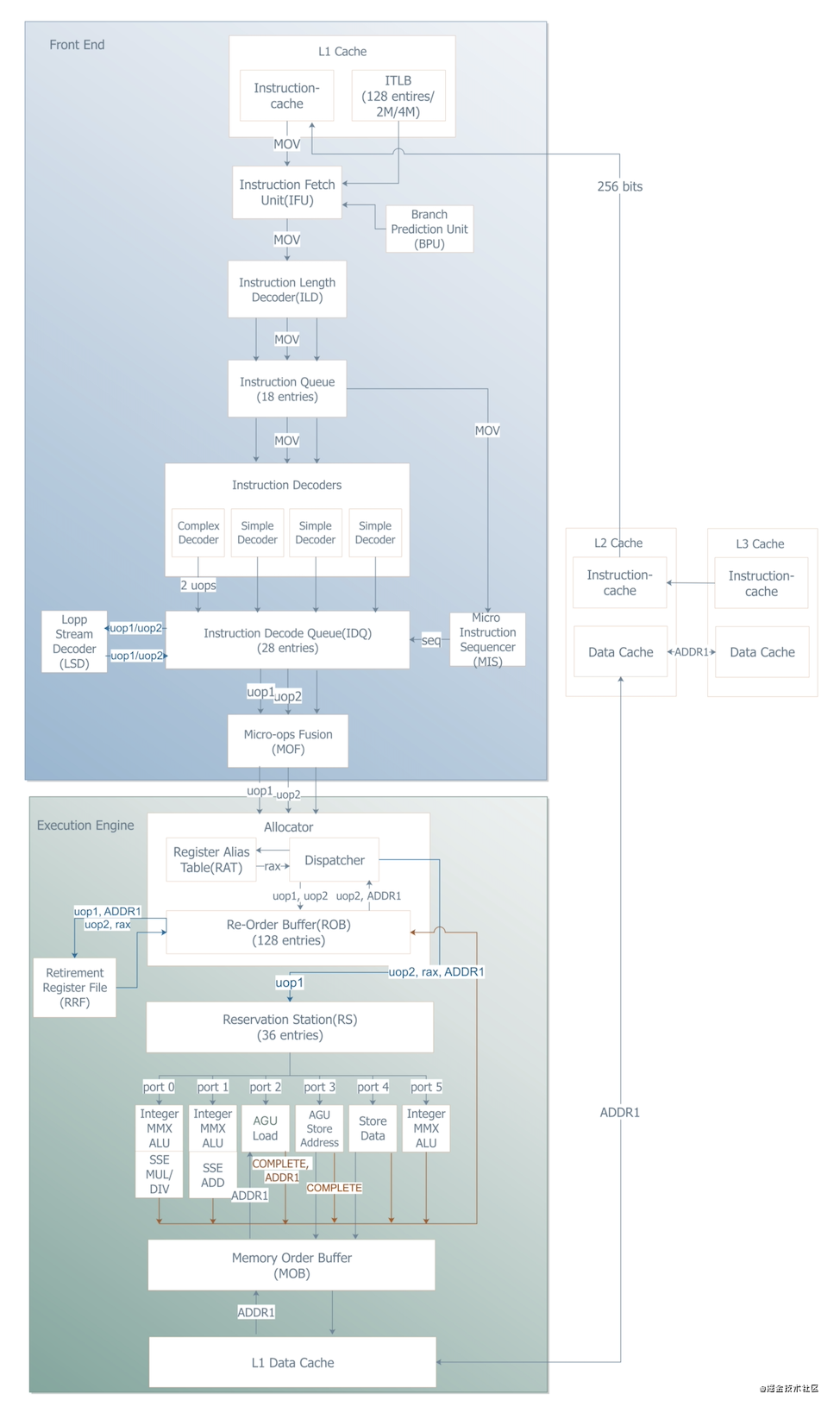
1.指令提取单元(IFU)从ITLB读取指令MOV在CPU L1 Cache中的位置
2.指令提取单元(IFU)从分支预测单元(BPU)读取if...then中分支then中的起始指令,由于MOV指令操作不涉及if条件,所以,该读取结果为空
3.指令提取单元(IFU)根据步骤1得到的位置到CPU L1 Cache中的Instruction Cache中找到指令MOV,并提取MOV
4.指令提取单元(IFU)将MOV指令传递给解码器(ILD)
5.解码器(ILD)对指令MOV进行预解码,校验指令长度等,如果超过指定长度,会做其他处理,ps:这个将来我会在其他文章中详细讲解。
6.解码器(ILD)将MOV指令传递给指令队列(Instruction Queue)进行缓冲,ps:当指令非常多时,指令队列可以收集一批指令后,在一个时钟周期批量将这批指令下传,一批4条指令
7.指令队列将MOV指令传递给指令解码器(Instruction Decoders)进行解码,指令解码器包含4个解码器:1个复杂解码器(Complex Deocder)和3个简单解码器(Simple Decoder),前者用于解析复杂的一条指令,将其解析为1 ~ 4条微指令(不包含1),后者将一条简单指令解析为一条微指令,微指令一般缩写为uop。上面memcmp函数中的MOV指令含义是从内存中读取用于比较的两个入参地址,并将地址分别写入两个rax寄存器,属于复杂指令,所以,这条MOV指令被解析为两条微指令uops:从内存中读取入参地址uop1和将地址写入rax寄存器uop2
8.指令解析器将分解的两个uops传递给指令解码队列(IDQ),进行指令去重
指令解码队列(IDQ)依次将两个uops传递给循环检测器(LSD),循环检测器检查uop是否存在类似while这样的循环语句,如果存在,对循环中重复的uop去重。由于 uop1和uop2均不存在循环,所以,循环检测器直接返回uop1和uop2给指令解码队列(IDQ)微指令序列号生成器给 uop1和uop2生成两个序列号,将序列号传递给指令解码队列,分配给uop1和uop2
9.指令解码队列将uop1和uop2传递给MicroOps Fusion,做微指令聚合。对于有些指令相同的,在这里就聚合为一条微指令 + 指令个数。uop1和uop2不相同,所以,不做聚合。
10.至此,CPU完成了指令MOV的执行前工作,这个过程一般称作Front End。接着,Fusion将uop1和uop2传递给分配器Allocator,进行微指令执行单元分配
(1)Dispatcher分别将微指令uop1和uop2写入重排序缓冲区(ROB),等待指令执行结果。
(2)Dispatcher同时将微指令写入中继器(RS),对于uop1和uop2,这个写入是有区别的:
uop1是一个内存读取操作,所以,写入重排序缓冲区的uop1是完整微指令:uop1 ADDR1,ADDR1为读取的内存地址。又因为uop1无依赖前置数据,所以,Dispatcher将uop1完整指令同时写入中继器(RS),待执行。uop2是一个写寄存器操作,写入源数据当前不存在,所以,Dispatcher不会将uop2的完整指令写入中继器(RS)
11.中继器分析哪些微指令有依赖关系,哪些没有依赖关系,有依赖关系的串行执行,无依赖的并行执行。由于,当前中继器中只包含uop1,所以,只给uop1分配执行单元,即通过port2端口,将uop1完整指令传递给AGU Load执行单元,执行uop1,即该执行单元从内存排序缓冲区(MOB)中读取地址为ADDR1,如果不存在,再从CPU L1 Data Cache中读取,L1 Data Cache中没有,继续从L2 Cache读取,L2 Cache没有,就从L3 Data Cache中读取,CPU三级缓存中都没有,那只能通过地址总线从内存中读取ADDR1
12.当AGU Load执行单元成功读取到ADDR1后,发送完成状态COMPLETE和ADDR1到重排序缓冲区(ROB)
13.重排序缓冲区将uop1执行结果(状态)和ADDR1写入回退寄存器文件(RRF)
14.重排序缓冲区移除微指令uop1
15.此时,重排序缓冲区中有了ADDR1和步骤10写入的uop2,于是,重排序缓冲区将uop2和ADDR1传递给Dispatcher,Dispatcher从寄存器别名表中命名一个rax寄存器,构造完整的uop2指令,即uop2 rax, ADDR1,表示将ADDR1写入rax寄存器,然后,将完整指令写入中继器(RS),准备执行uop2。
16.中继器通过port 3端口分配AGU Store Address执行单元执行uop2,将ADDR1写入rax寄存器
17.执行单元执行成功后,将结果状态COMPLETE写入重排序缓冲区
18.重排序缓冲区将uop2执行结果(uop2,rax)写入回退寄存器文件(RRF),记录下rax寄存器中的值ADDR1
19.重排序缓冲区移除微指令uop2
通过上面的步骤,你应该了解一条指令在CPU中的处理过程,那么,回到上面的一个问题:为什么memcmp函数,要以32字节单位,拆分4次比较两个入参地址呢?
从上图可以发现,右侧L2 Data Cache和底部L1 Data Cache连接在一起,用来传输数据,而这个传输的带宽为256bit,即一次最多可以传输32个字节的数据,所以,将入参地址以32字节为单位执行
uop1微指令,可以充分利用L2 Data Cache和L1 Data Cache之间的带宽。结合上面的步骤11,由于CPU每个时钟周期可以同时从中继器(RS)中挑选可并发执行的4条微指令并发执行,所以,将相同的比较指令CMP拆分4次,同时对比较的入参地址的4个部分并发比较,最后将比较结果汇总。这样,原来串行执行4次的比较任务变成的并行的一次执行,性能将大大提升。
结合上面memcmp函数中MOV指令在CPU中的处理过程,我们知道如果用于比较的排序字段长度超过32字节,而此时该字段值不在CPU L1 Cache中,那么,CPU不得不分多次将字段值写入L1 Cache,影响了性能,所以,建议排序字段的大小不要超过32字节。
小结
通过本章内容的讲解,我们知道了一些排序优化的方法:
将排序字段加入索引,实现覆盖索引,避免排序 SQL中SELECT字段 + 排序字段的值大小小于等于参数 max_length_for_sort_data,可以避免回表查询,提升性能排序字段大小尽量不要超过32字节,充分利用64位CPU的特性,提升排序性能
思考题
关于《覆盖索引》中的那条SQL:
SELECT * FROM user WHERE user_name LIKE "%am%" AND age >= 18 AND age <= 24 AND sex = 0 ORDER BY age, user_name LIMIT 0, 50
本章中,使用了快速排序对age,username排序,有没有更好的办法,提升排序的性能?
更多精彩文章请关注