
【Redis 系列】redis 学习,sorted_set 初步探究梳理
sorted_set 是什么?
sorted_set 就是 zset ,是 redis 里面的数据之一,有序集合
有序集合是集合的一部分,有序集合给每个元素多设置了一个分数,相当于多了一个维度,redis 也是利用这个维度进行排序的
实际应用
redis-cli 连接上 redis-server ,使用 help @sorted_set 查看有序结合支持的命令
# redis-cli -p 6379
127.0.0.1:6379> ping
PONG
127.0.0.1:6379>
127.0.0.1:6379> help @sorted_set
BZPOPMAX key [key ...] timeout
summary: Remove and return the member with the highest score from one or more sorted sets, or block until one is available
since: 5.0.0
....
复制代码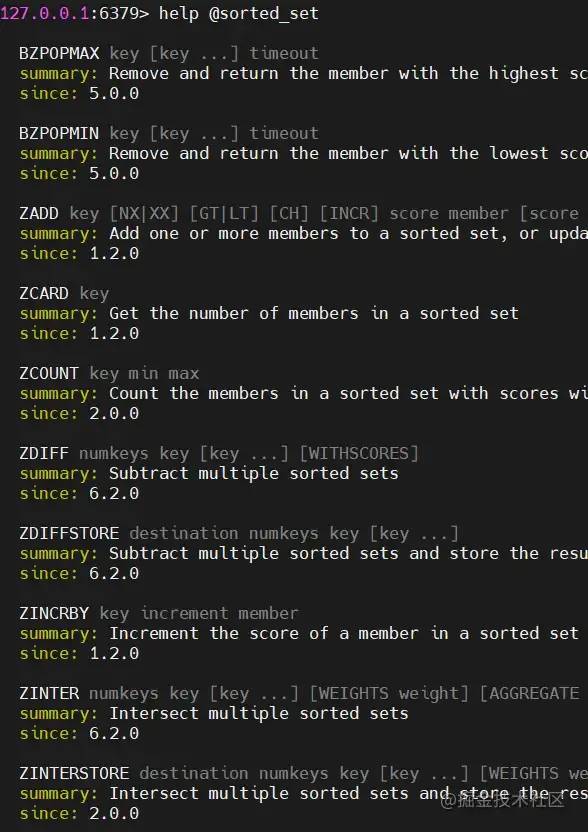
summary
对这个命令的概括
since
这个命令从 redis 哪一个版本就开始提供了
举个例子
在 sorted_set 中添加一个 key,这个key 里面有 3 个成员 ,3 个成员对应的分支如下:
| 成员 | 分值 |
|---|---|
| pig | 9 |
| dog | 2 |
| cat | 6 |
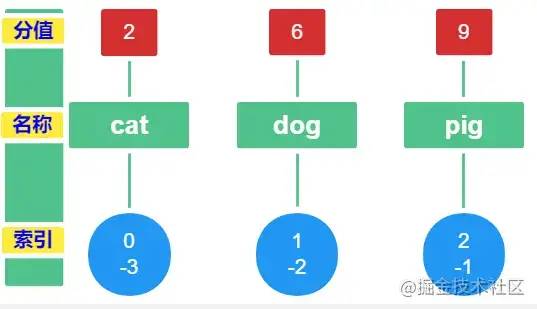
127.0.0.1:6379> zadd k1 9 pig 2 dog 6 cat
(integer) 3
复制代码获取有序集合的所有值,默认是按照有效到大的方式来展示,因为数据存入到 redis 内存中,物理内存的结果是从左到右,逐个递增的
127.0.0.1:6379> ZRANGE k1 0 -1
1) "dog"
2) "cat"
3) "pig"
复制代码获取排名从小到大的前 2 位怎么做?
127.0.0.1:6379> ZRANGE k1 0 1 withscores
1) "dog"
2) "2"
3) "cat"
4) "6"
复制代码获取从大到小的排名前 2 位呢?
下面这个是正确的,使用 ZrevRANGE 来获取
127.0.0.1:6379> ZrevRANGE k1 0 1 withscores
1) "pig"
2) "9"
3) "cat"
4) "6"
复制代码下面这个是错误的
127.0.0.1:6379> ZRANGE k1 -2 -1 withscores
1) "cat"
2) "6"
3) "pig"
4) "9"
复制代码例子2
咱们对以下几个学生设置分数,按照权重来做一个排名
| k1 | 分数 |
|---|---|
| xiaoming | 90 |
| zhangsan | 40 |
| lisi | 60 |
| k2 | 分数 |
|---|---|
| xiaohong | 30 |
| zhangsan | 70 |
| wangwu | 50 |
127.0.0.1:6379> flushall
OK
127.0.0.1:6379> zadd k1 90 xiaoming 40 zhangsan 60 lisi
(integer) 3
127.0.0.1:6379> zadd k2 30 xiaohong 70 zhangsan 50 wangwu
(integer) 3
127.0.0.1:6379> ZUNIONSTORE unkey 2 k1 k2 weights 0.5 1
(integer) 5
复制代码按照权重来排序,k1 占比 0.5 , k2 占比 1,计算排名,实际例子可以用来计算按照权重的总分
127.0.0.1:6379> ZUNIONSTORE unkey 2 k1 k2 weights 0.5 1
(integer) 5
127.0.0.1:6379> Zrange unkey 0 -1 withscores
1) "lisi"
2) "30"
3) "xiaohong"
4) "30"
5) "xiaoming"
6) "45"
7) "wangwu"
8) "50"
9) "zhangsan"
10) "90"
复制代码k1 和 k1 取成员的最大值来进行排名,实际例子可以是多个科目成绩的最高分进行排名
127.0.0.1:6379> ZUNIONSTORE unkey2 2 k1 k2 aggregate max
(integer) 5
127.0.0.1:6379> zrange unkey2 0 -1 withscores
1) "xiaohong"
2) "30"
3) "wangwu"
4) "50"
5) "lisi"
6) "60"
7) "zhangsan"
8) "70"
9) "xiaoming"
10) "90"
复制代码那么我们思考一下,sorted_set 的排序是如何实现的呢?
sorted_set 排序实现原理
排序是通过 skiplist 跳表来实现的,skiplist 是一个类平衡树
skiplist 本质上也是一种查找结构,用于解决算法中的查找问题
Redis内部数据结构详解 这本书中有说到,查找问题的解法有如下 2 类:
基于各种平衡树
基于哈希表
skiplist 跳表 不属于上述任何一个,他可以说是一个 类平衡树
咱们来举个例子:
例如有如下跳表,总共有 3 层
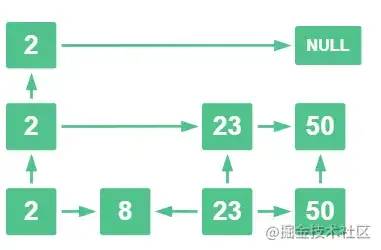
现在要将 15 这个数字插入这个跳表
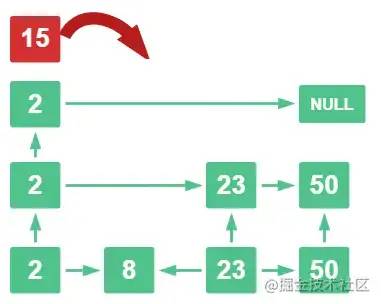
用 15 去第一层看,比 2 大,那么往下走
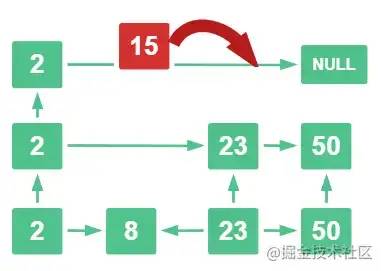
15 比 23 小且比 2 大,那么往下走
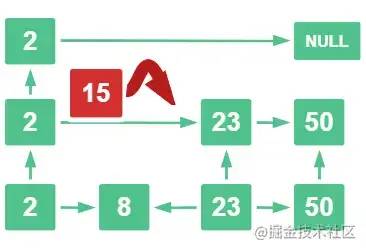
15 比 23 小,比 8 大,那么 15 就插入这里了
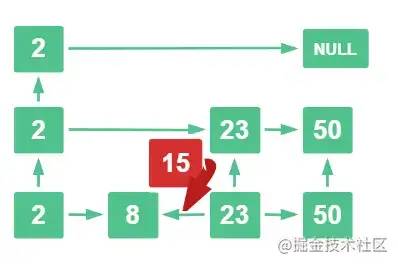
插入这里,第三层 8 的指针 指向 15, 23的指针也指向 15
第二层 2 的指针 指向 15,15 指向 23
第三层 2 的指针也指向 15, 15 指向 NULL
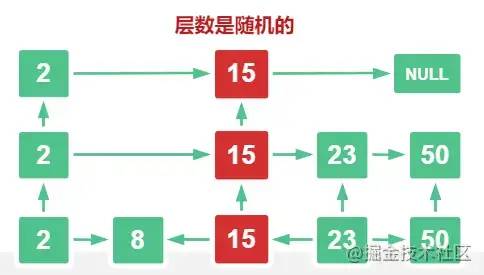
根据上面这个例子,我们可以明白,skiplist 就是一个特殊的链表,叫做跳表,或者是跳跃表
我们还发现,这么多层链表,就是最下面这一层的链表元素是最全的,其他层都是稀疏的链表,这些链表里面的指针故意跳过了一些节点(越高层的链表跳过的节点越多)
这就使得我们在查找数据的时候能够先在高层的链表中进行查找,然后逐层降低,最终降到第一层链表来精确地确定数据位置
这种方式过程中是跳过了很多节点的,因此也就加快了我们的查找速度
无论是增删改查,都是需要先查询的,先明确查找到需要操作的位置,再进行操作
skiplist和平衡树、哈希表的比较
| skiplist | 平衡树 | 哈希表 | |
|---|---|---|---|
| 算法实现难度 | 简单 | 较难 | |
查找单个key | 时间复杂度为O(log n) | 时间复杂度为O(log n) | 在保持较低的哈希值冲突概率的前提下 查找时间复杂度接近O(1) 性能更高一些 |
| 范围查找 | 适合 | 适合 | 不适合 |
| 范围查找是否复杂 | 非常简单 只需要在找到小值之后 对第1层链表进行若干步的遍历就可以实现 | 复杂 需要对平衡树做一些改造 | |
| 插入和删除操作 | 简单又快速 只需要修改相邻节点的指针 | 可能引发子树的调整 | |
| 内存占用 | 灵活 个节点包含的指针数目平均为 1/(1-p),具体取决于参数p的大小 | 平衡树每个节点包含2个指针(分别指向左右子树) |
我们查看到 redis src/server.h 中有对 skiplist 的结构定义
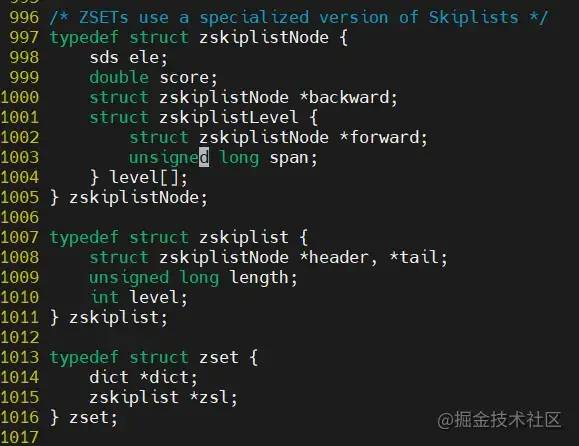
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
复制代码zskiplist ,跳跃表
| length | 跳跃表 长度 |
| level | 目前跳跃表的最大层数节点 |
zskiplist 定义了真正的skiplist结构:
头指针
header和尾指针tail。链表长度
length,即链表包含的节点总数这里需要注意一点:
新创建的
skiplist包含一个空的头指针,这个头指针不包含在length计数中level表示skiplist的总层数,就是所有节点层数的最大值
zskiplistNode , 跳跃表的节点
| score | 分值 |
| backward | 后退指针 |
| forward | 前进指针 |
zskiplistNode 定义了 skiplist 的节点结构:
存放的是
sds,zadd命令在将数据插入到skiplist里面之前先进行了解码,这样做的目的应该是为了方便在查找的时候对数据进行字典序的比较score字段是数据对应的分数backward字段是指向链表前一个节点的指针(前向指针),每一个节点只有1个前向指针,所以只有第1层链表是一个双向链表。level[]存放指向各层链表后一个节点的指针(后向指针)每层对应1个后向指针,用
forward字段表示。span值 ,是每个后向指针还对应了一个 span,它表示当前的指针跨越了多少个节点span用于计算元素排名(rank)
关于 redis 源码中,创建节点,插入节点,删除节点的源码都在 src/t_zset.c 里面,详细的源码流程感兴趣的可以细细品读一下,还在品读中
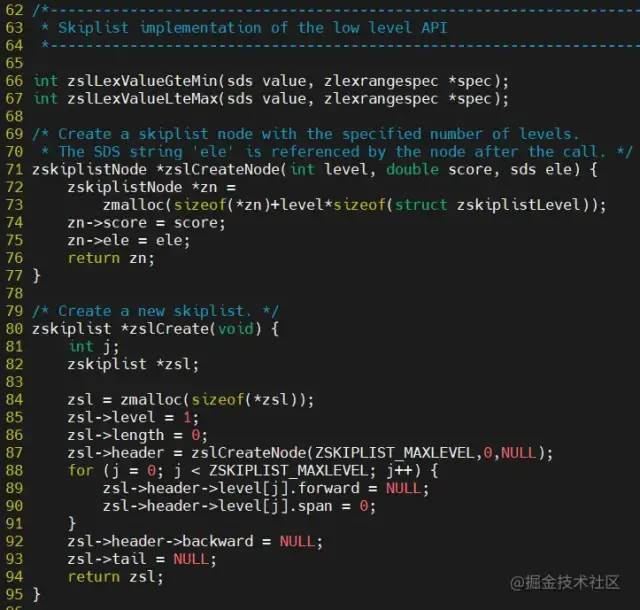
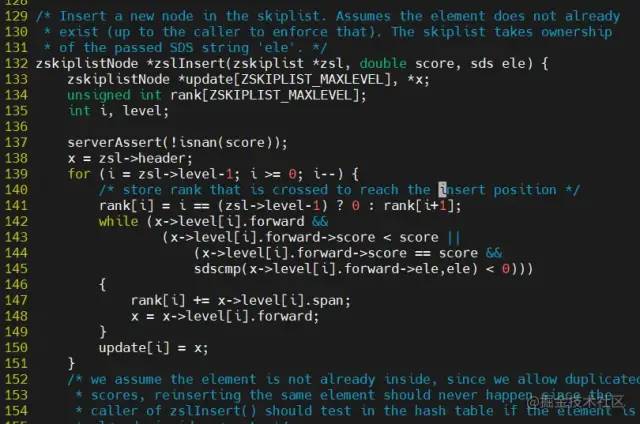
参考资料:
redis_doc
reids 源码
src/t_zset.c和src/server.h
欢-迎点赞,关注,收藏
朋友们,你的支持和鼓励,是我坚持分享,提高质量的动力
作者:小魔童哪吒
链接:https://juejin.cn/post/7002267427086008327
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。