
状态机设计原则:清晰!清晰!还是清晰!
来源:裸机思维
作者:GorgonMeducer 傻孩子
【说在前面的话】
我们常说:状态机是一种思维方式、一种工具,同时它也是一种拥有极高自由度的语言,作为一种翻译思维的语言工具,不同人在使用状态机时也有类似的表达能力的问题。
【功能单一原则】
人类是视觉主导的“动物”,具体表现为:对于同样的信息,一张优秀的图片往往能让人秒懂,而对应的优秀文字描述哪怕写的简单易懂,人们通常也需要花费数倍的时间来阅读。这里的原因其实很简单——对于图片,人类是并行处理的;而对于建立在阅读之上才能理解的文字,人类采用的是一种“连蹦带跳”的顺序处理方式。并行和顺序处理的在时间效率上的差异,可见一斑。
在普通的应用逻辑中,使用状态图描述逻辑也具有这种“让人一目了然”的潜力;理论上,通过读图理解设计者意图的速度应该远高于直接阅读翻译后代码的速度——遗憾的是,实践中由于缺乏正确的设计原则指导,很多人绘制的状态图恐怕还不如代码看起来好懂。空口白牙,抽象的很,我们不妨举个例子:
一般来说,在全状态机开发下,永远都应该“先画图”,觉得逻辑没有问题的情况下,再“根据状态图来无脑的翻译代码”——这对一张白纸的初学者来说往往很容易做到;遗憾的是,对大部分已经有几年工作经验,习惯了线性逻辑开发的人来说就有点困难了。比如,当我们说要设计一个输出字符串的状态机,对很多人来说,首先出现在大脑中的不是一张状态图,而是类似如下函数的一个参考代码://! \brief 通过外设非阻塞的输出一个字节
extern bool serial_out(uint8_t cbByte);
void print_str(const char *pchStr)
{
if (NULL == pchStr) {
return ;
}
//! C语言中,字符串一般以 '\0' 作为结尾
while (*pchStr != '\0') {
//! 由于外设比较慢,输出不一定每次都成功
while(!serial_out(*pchStr));
pchStr++;
}
}
作为参考代码,显然,所有人都知道阻塞是大问题,只要把这个代码改为非阻塞的就行了,于是基于上述代码在脑海中先入为主的影响,很容易“逆向”出如下的状态图:
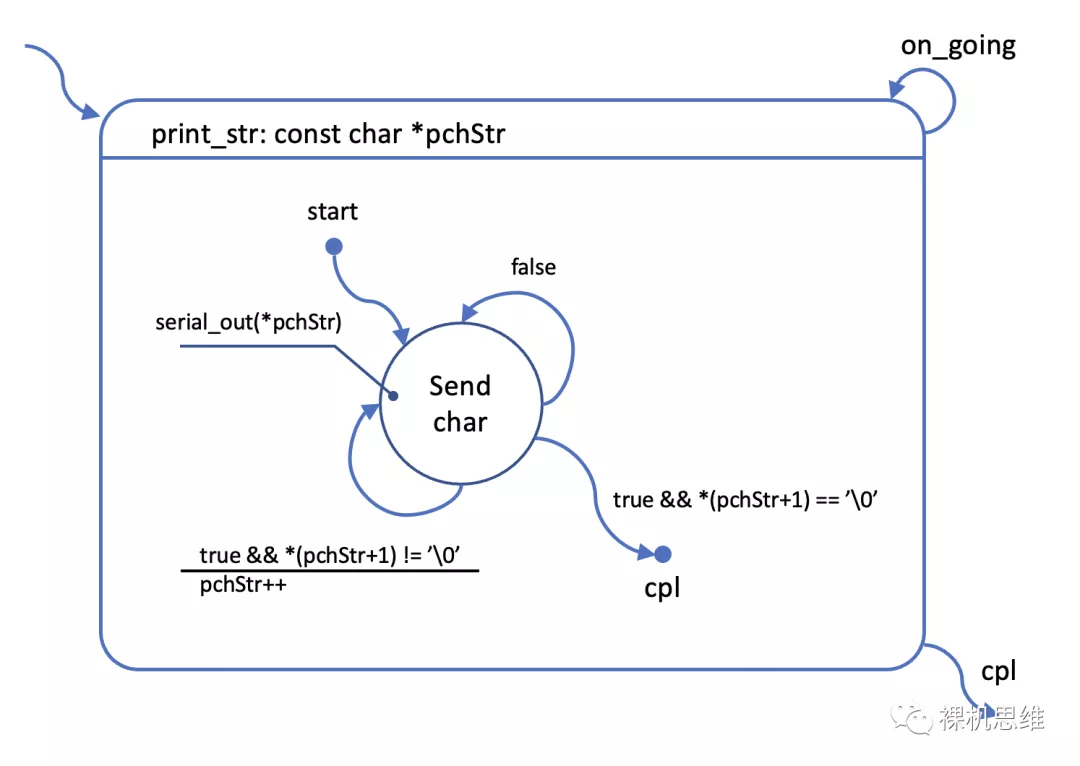
这个图从严格的语法意义上来说完全合格,只不过阅读起来有点痛苦——虽然只有一个状态,但猛然让一个第三人阅读,估计要花费不少的时间,可能的原因如下:
这个状态有三个跃迁
这个状态实际上拥有两个功能:
通过serial_out()函数输出字符
判断字符串的尾部
我们说这个图虽然语法上正确,但是违反了一个很重要的状态图设计原则——功能单一原则。所谓功能单一原则是指:每个状态的功能要尽可能单一,要避免将多个功能复合在同一个状态上,从而产生所谓的“超级状态”的情况。设计出超级状态并不是什么值得骄傲的本事,它单纯:
增加了旁人(以及几个月后的自己)阅读和理解状态逻辑的难度
增加了修改和扩展状态图的难度
增加了白盒分析的难度
几何状的增加了单一一个状态所拥有的跃迁的数量
回头再看前面的例子,很容易发现,它违反了状态功能单一原则:将字符输出和判断字符串尾部的功能集成进了同一个状态,从而产生了一个拥有3条跃迁的超级状态。基于状态功能单一原则,一个更好的设计如下:
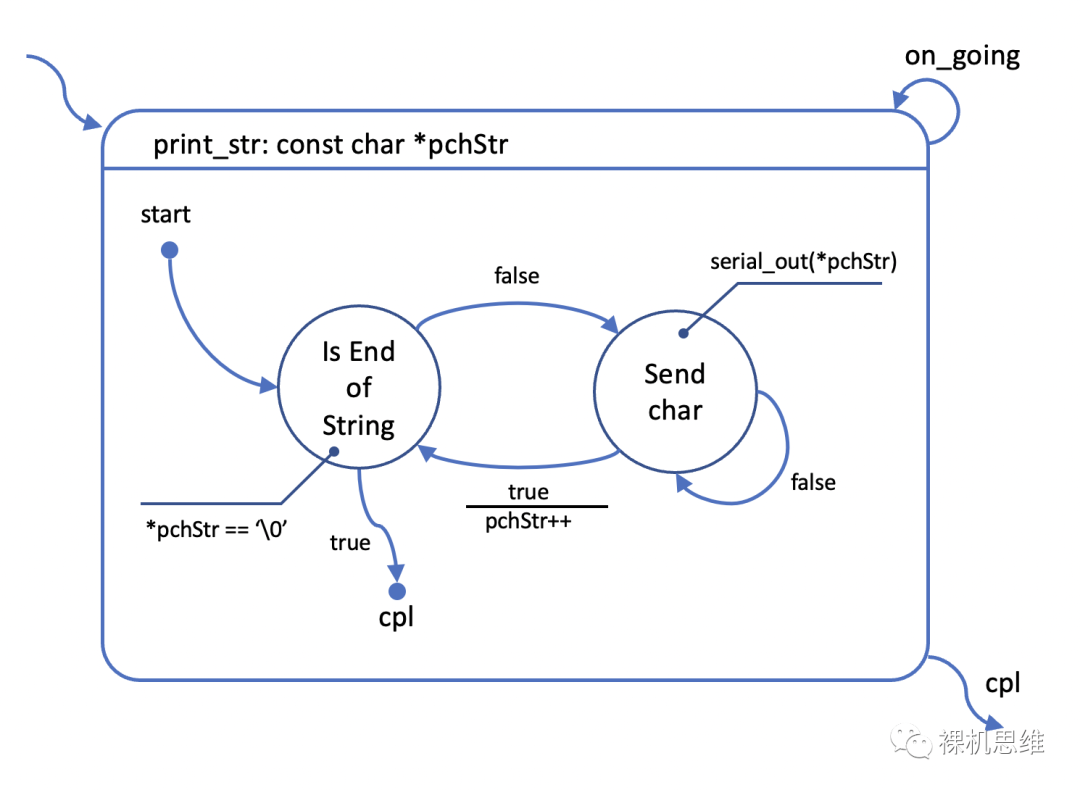
在这个图中,虽然状态数量变成了两个,但它们分工明确功能单一,阅读起来较为简单,也非常容易发现上一张图中不太容易发现的逻辑问题——比如前一个状态图如果字符串是空串“”,就会产生内存访问越界的致命bug,而通过拆分成两个状态,很容易注意到“IS End Of String”状态所处位置对空串的敏感度——这也是功能单一原则增强了白盒测试(肉眼看图找bug)能力的一个强有力的证明。
有的小伙伴可能会说,前一个状态图其实也不是很复杂啦,我就能看懂。对此,我想说:前面的例子终究只是一个为了介绍问题而引入的例子,本身不会太复杂,讲清楚问题就行了。而在实际应用中,在缺乏“功能单一”原则的限制下,鬼知道设计师会复合出怎样的“蜘蛛精”;
超级状态的成因之一是一部分人受到先前习惯的影响,虽然是设计状态机,但总是无法自控的“先有代码在脑海里”然后“再逆向”绘制出对应的状态图。这个习惯说实话很难克服,也非常容易理直气壮的产生“自以为是在优化代码”的超级状态。针对这种心理,我们不妨强调下状态机设计的正确流程:
状态机设计的第一步永远都是逻辑设计,追求的是清晰,此时绝不需要考虑所谓的代码翻译时如何才能做到最优;
状态图才是真正的源代码,而翻译后的C代码则是“汇编”;
任何针对状态机的修改都必须从状态图开始,完成逻辑修改后,无脑的翻译成代码来查看运行效果;
当且仅当状态机的逻辑已经经过验证,确认是正确无误的情况下,如果确实有用户需求或者系统性能没有达到要求,此时才进入状态图优化阶段——这里遵守的原则是:先优化状态图,最后万不得已的情况下才去优化翻译后的代码。
说了这么多,我们不妨再用一个例子实际操作一下:假设我们要设计一个状态机,从用户那里识别单词"OK"——其中一种最无脑的设计思路如下:
从逻辑的角度来说,很容易想到,对每一个字符来说,我们都有两个阶段:读取字符输入
判断字符是否是我们想要的目标字符
因此很容易无脑的画出如下的状态机:
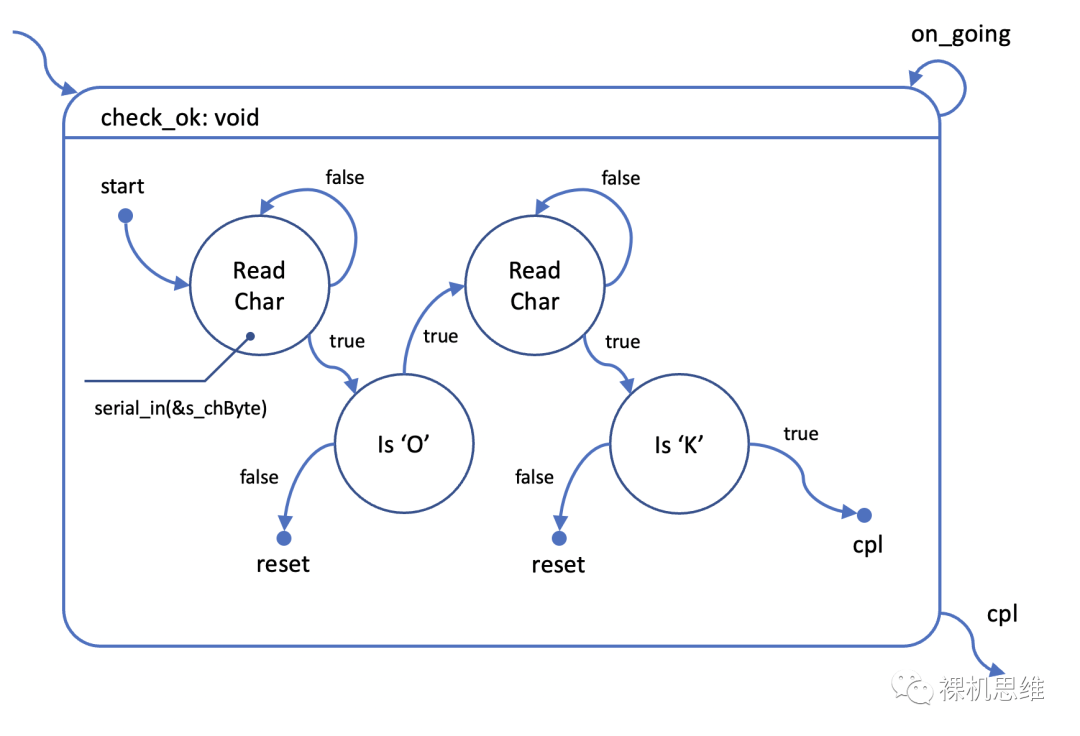
眼尖的小伙伴可能已经注意到,这个图中引入了一个新的名为reset的小圆点,它的功能也很直接:当跃迁到reset小圆点时,状态机复位,并返回on-going。一个系统中可以有多个reset小圆点。有的小伙伴可能要问,为啥不是“跃迁到状态机的第一个状态”而一定要使用reset小圆点呢?原因主要有二:
避免第一状态扇入过多,导致状态图太丑;
如果使用跃迁到第一个状态的方法,则每一个跃迁都可能要重复去做类似初始化的工作——每多一条跃迁就多了一个重复的内容——这里如果不是简单复制粘贴的话,可能还会出现在漫长的代码维护过程中出现“某些跃迁的动作与其它不一致”从而给自己挖坑的情况;使用reset可以确保状态机复位,从而安全的从唯一的start点进入,完成统一的初始化动作。
尽管有的小伙伴会说:“这个状态机看起来好蠢啊”,“这个状态机看起来一点通用性都没有”,但我要说,领会下精神啦,这只是我用来介绍方法论的例子,实际应用当然不会这么设计,但不管怎么说,这个状态机很清晰有木有?就是非常简单直接的“一二一二……”步骤的无脑叠加——而这种功能单一、逻辑清晰的无脑叠加正是状态机设计思维的一种体现——先逻辑清晰,一切都对了再考虑要不要优化。
然而,没有对比就没有伤害,我们再来看看一个反例——当我们先有代码在脑海里“挥之不去”,再“逆向”出状态图时会发生什么。
一个很容易想到的“最优”代码如下:
fsm_rt_t check_ok(void)
{
uint8_t chByte;
...
switch (s_tState) {
...
case RCV_O:
if (!serial_in(&chByte)) {
break;
}
if (chByte != 'O') {
CHECK_OK_RESET_FSM();
break;
}
s_tState = RCV_K;
case RCV_K:
if (!serial_in(&chByte)) {
break;
}
if (chByte != 'K') {
CHECK_OK_RESET_FSM();
break;
}
CHECK_OK_RESET_FSM();
return fsm_rt_cpl;
}
return fsm_rt_on_going;
}
受其影响,“逆向”出的状态图如下:图片
看到这个状态图,很多小伙伴估计要不淡定了?“傻孩子你是不是打自己脸了?”“这个图看起来明明看起来更直接啊?状态更少,而且对应的代码明显更优化啊!”
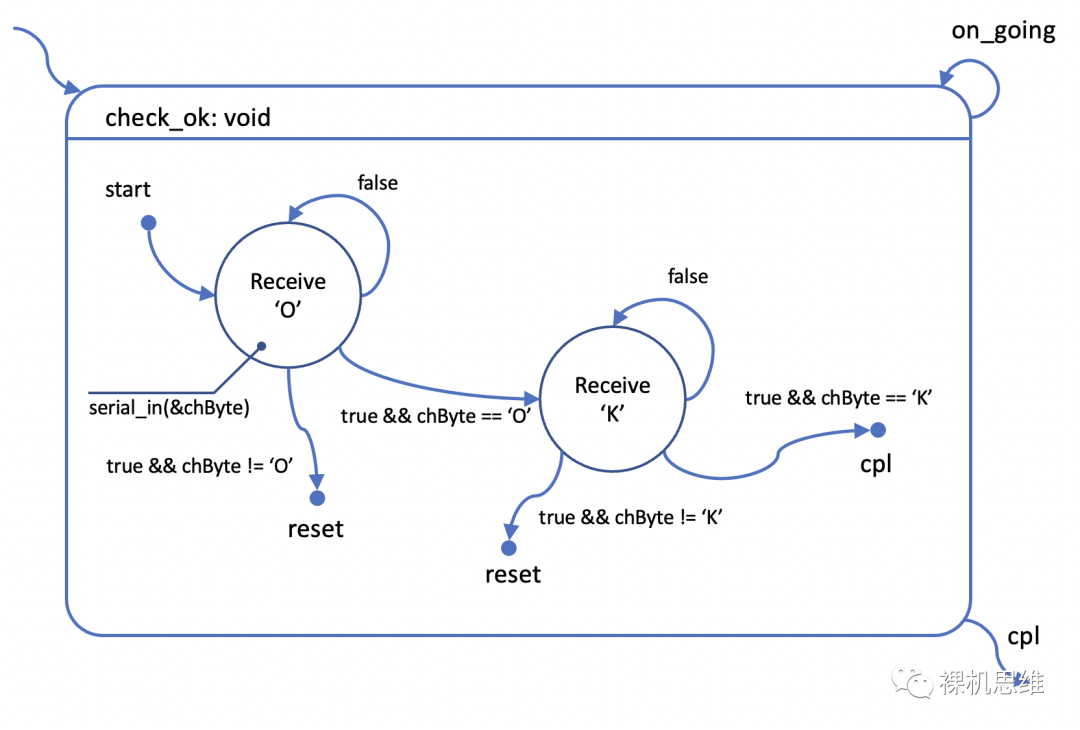
别急别急,好汉先看完下面的内容再打不迟。
【如何在“结构清晰”和“性能优化”之间取得平衡】
在前面的讨论中,我们遇到了状态机设计的一个非常实际的问题:在追求逻辑清晰的时候,似乎由于状态的增多,代码执行的性能受到了某种影响——它表现在当翻译成switch状态机时,增加了太多不必要的状态切换,从而影响了当前状态机的执行效率。比如:
这里,每次成功阅读到一个字符后,在翻译成switch状态机后,居然要到下一次才能对字符进行判断,而判断后居然又要退出状态机,再下一次才能开始新的一轮字符读取——这个状态机也实在太“卑微”了。考虑到《实时性迷思(2)——“时间片轮转”的沙子》中推导出的结论:非必要的频繁任务切换会浪费大量的处理器时间,从而影响系统的实时性,这里由状态切换导致的频繁CPU出让(yield)实际上并非好事。
难道我们必须要在“逻辑清晰”和“性能优化”中做出取舍么?
先别着急下结论,分析上面的原因容易发现:
遵循状态功能单一原则会产生多个简单状态,逻辑清晰,阅读简单;
现有的状态切换过程中根据翻译方式的不同“有可能”出让CPU时间给其它任务;
那么,如果有一种方法能在状态切换的过程中明确“标注”不要出让CPU控制权(避免yield)是否就能解决问题了呢?比如,我们把此类切换从实线箭头修改为虚线箭头——表示此类切换不“主动”出让CPU控制权,则修改后的图如下所示:
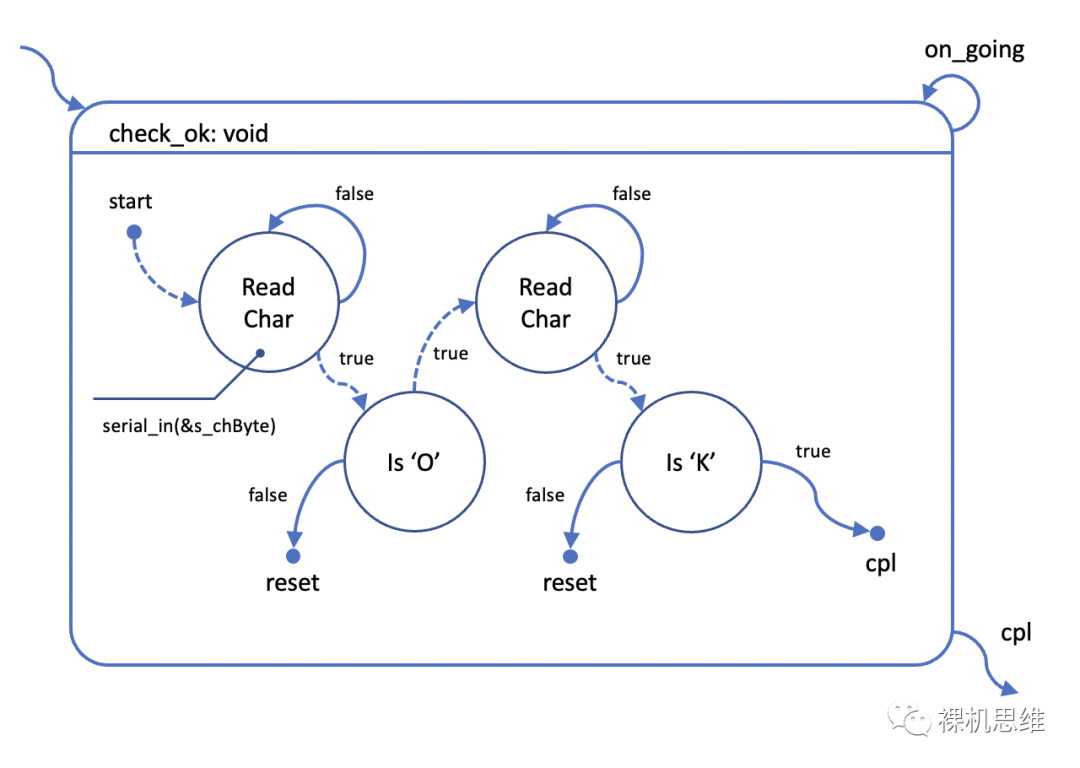
那么在switch状态机中,这类“不让出CPU”的切换,实际上就是“切换任务的同时确保不会退出状态机函数”。要想做到这一点有两种方式:
使用goto
使用switch的fall-through特性
如果你对switch的fall-through特性感到一头雾水,可以去找一本经典的C语言教程看一看,或者参考这里的博文(https://c-for-dummies.com/blog/?p=3607)
实际上,这里并不需要比较二者的优劣。一般来说,fall-through具有瀑布一般一泻千里不能回头的特性;而goto则适用于那些需要“逆流而上”的场合。作为例子,我们不妨使用新的方法翻译前面的状态图:
fsm_rt_t check_ok(void)
{
uint8_t chByte;
...
switch (s_tState) {
case START:
s_tState = READ_CHAR_0;
// break; //!< fall-through实现虚线切换
case READ_CHAR_0:
if (!serial_in(&chByte)) {
break;
}
s_tState = IS_O;
// break; //!< fall-through实现虚线切换
case IS_O:
if (chByte != 'O') {
CHECK_OK_RESET_FSM();
break;
}
s_tState = READ_CHAR_1:
// break; //!< fall-through实现虚线切换
case READ_CHAR_1:
if (!serial_in(&chByte)) {
break;
}
s_tState = IS_K;
// break; //!< fall-through实现虚线切换
case IS_K:
if (chByte != 'K') {
CHECK_OK_RESET_FSM();
break;
}
CHECK_OK_RESET_FSM();
return fsm_rt_cpl;
}
return fsm_rt_on_going;
}
通过观察可以发现,上述代码借助fall-through的特性取得了跟前一章节参考代码几乎无异的执行性能——实际上,聪明的你已经发现,在确有必要的情况下,可以在状态机的优化阶段对上述代码进行进一步的优化,从而得到与此前参考代码一模一样的结果:
fsm_rt_t check_ok(void)
{
uint8_t chByte;
...
switch (s_tState) {
...
case RCV_O:
if (!serial_in(&chByte)) {
break;
}
if (chByte != 'O') {
CHECK_OK_RESET_FSM();
break;
}
s_tState = RCV_K;
case RCV_K:
if (!serial_in(&chByte)) {
break;
}
if (chByte != 'K') {
CHECK_OK_RESET_FSM();
break;
}
CHECK_OK_RESET_FSM();
return fsm_rt_cpl;
}
return fsm_rt_on_going;
}
至此,我们实际上明确了状态机的日常设计步骤:
按照状态功能单一原则,以逻辑清晰为基本目标,再完全不考虑优化的情况下,完成状态机的设计和调试;
在完成了状态机逻辑正确性验证的前提下,在必要的情况下,可以对状态图进行性能优化;
如果经过上述步骤,性能仍然达不到要求,可以对翻译后的代码进行进一步的等效优化。
注意,以上过程是单向不可逆的。一般会把步骤1和步骤2视作“一次迭代”,敏捷开发中可能会允许用户进行多次迭代。
【条件太多怎么办】
很多时候,虽然借助“虚线切换”可以在性能和清晰度上获得一定的平衡,但如果一个状态机状态数量太多,难免会让人眼花缭乱。就前面的状态图check_ok来说,这只是识别两个字符,如果字符一多,图岂不是直接爆炸了?
也许不是一个很好的例子,但如果真的能省略掉图中“IS_O”和“IS_K”两个状态,并且仍能保证清晰的逻辑,岂不美哉?为了应对这种情况,我们引入了新的图例:公共条件(common condition)和子条件(sub condition)。那么,如何理解这两个新的概念呢?此前,我们的状态模型上,每个跃迁都由两部分组成:跃迁的条件(condition)和跃迁时执行的一次性动作(action):
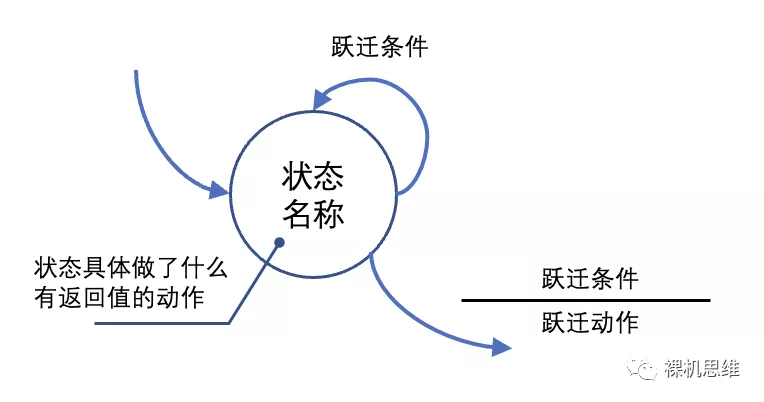
这一模型可以应对大部分较为简单的情况,但实际应用中,一个状态的所涉及的具体行为可能会产生不止一个返回值,比如:
serial_in(&chByte);
就产生了两个有效的返回值:
serial_in() 函数的 boolean值,表示读取成功还是失败;
当读取成功时,保存在 chByte 中的字符也就成了一个我们要判断的返回值;
对于这种源自同一个状态的动作而产生的多个返回值,我们可以借助前面所说的“公共条件”和“子条件”的方式加以简化:
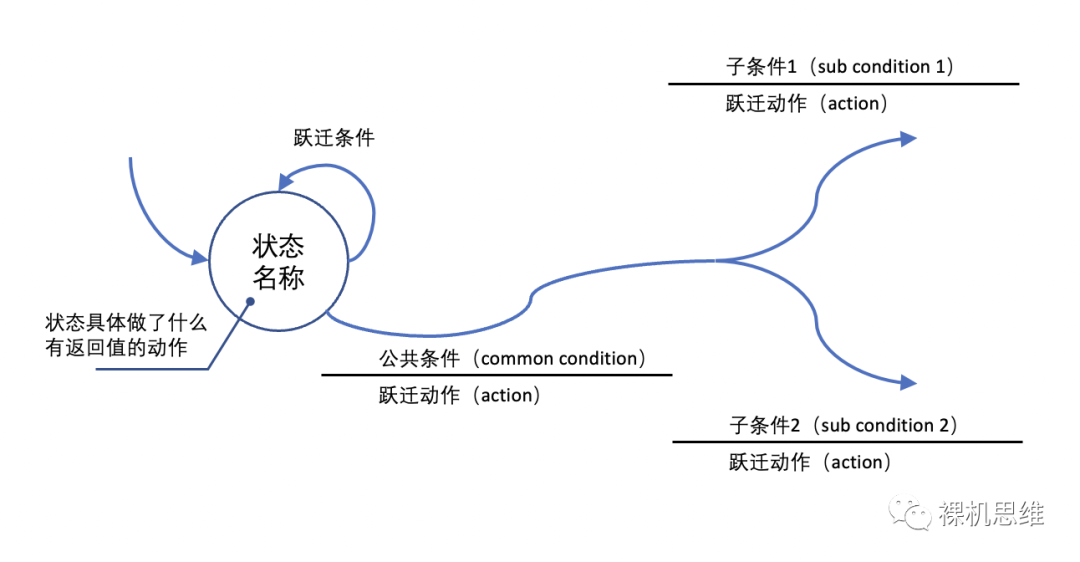
根据这一方式,修改前面的状态图如下:
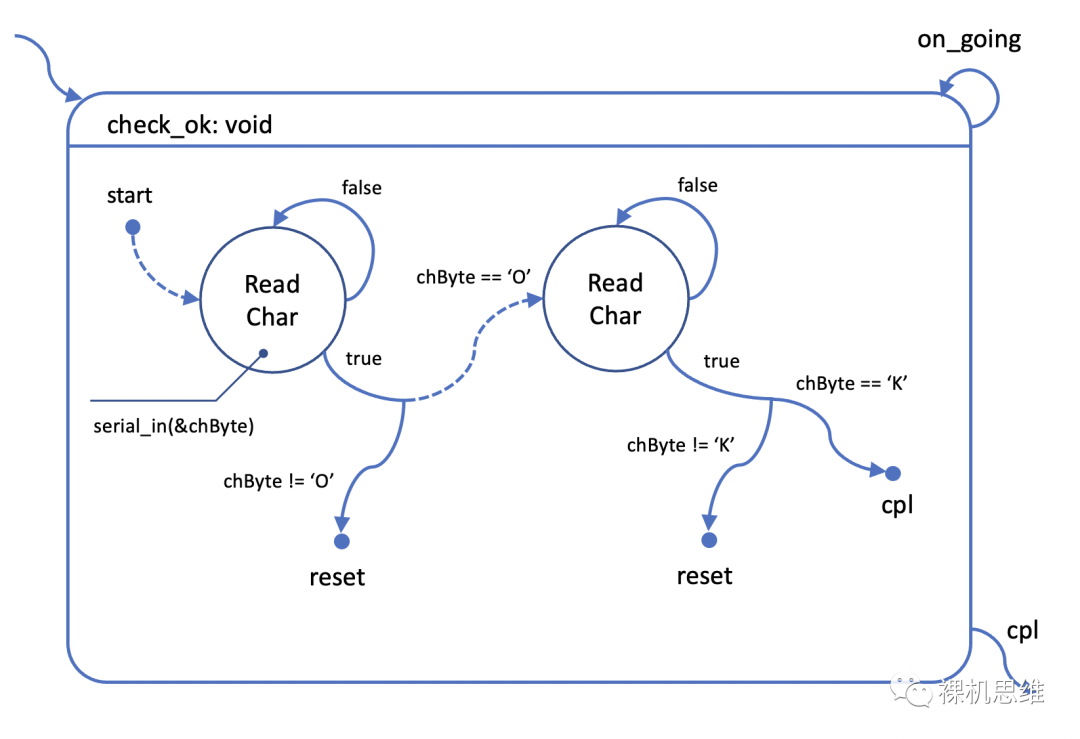
怎么样,是不是又清晰又简单呢?它的switch状态机代码如下:
fsm_rt_t check_ok(void)
{
uint8_t chByte;
...
switch (s_tState) {
case START:
s_tState = READ_CHAR_0;
// break; //!< fall-through实现虚线切换
case READ_CHAR_0:
if (!serial_in(&chByte)) {
break;
}
if (chByte != 'O') {
CHECK_OK_RESET_FSM();
break;
}
s_tState = READ_CHAR_1:
// break; //!< fall-through实现虚线切换
case READ_CHAR_1:
if (!serial_in(&chByte)) {
break;
}
if (chByte != 'K') {
CHECK_OK_RESET_FSM();
break;
}
CHECK_OK_RESET_FSM();
return fsm_rt_cpl;
}
return fsm_rt_on_going;
}
是不是似曾相识?这不就是之前的所谓最优代码么?
【八状态准则】
借助前面介绍的方法,我们不仅能优雅的设计出逻辑清晰的状态图、兼顾翻译后代码的性能,还能在不影响逻辑清晰度的情况下减少状态的数量。至此这里“粗暴的”提出一个名为“八状态”的经验准则,即:
一个优秀的状态机通常不应该拥有超过八个以上的状态;
如果你的状态机超过了八个状态,那么一定存在状态图层面的优化可能;
除了前面介绍过的能够减少状态的方法以外,将一部分高度相关(可能也重复出现)的状态提取成为子状态机,往往也能有效的减少状态的数量。
【后记】
使用状态图来设计状态机,其本意就是利用人类的视觉优于阅读能力的特性来降低设计难度。为了确保这一初衷能够贯彻始终,“逻辑清晰”就成为状态图设计的核心原则。
本着清晰第一的原则,首先要确保状态机逻辑正确,也就是常说的:先让功能跑起来没有问题;然后再考虑所谓的优化的问题。此外,对于有经验的老工程师来说,要尝试克服设计状态图时满脑子都是具体代码实现的弊端——至于这样,才能真正拥抱使用状态机进行开发的思维方式。
嵌入式编程专辑 Linux 学习专辑 C/C++编程专辑 Qt进阶学习专辑
关注我的微信公众号,回复“加群”按规则加入技术交流群。