
工商银行核心应用 MySQL 治理实践
摘要:本文根据2020年DTCC数据库大会分享内容整理而成。工商银行在2014年就开始推广使用MySQL。时至今日,生产环境的MySQL节点数量已经发展到近万个;应用场景也从外围低等级应用,推广到核心高等级应用。此次与大家分享,为承接核心业务数据存储的重担,工商银行在MySQL应用治理方面的思路和方案。


现状与挑战
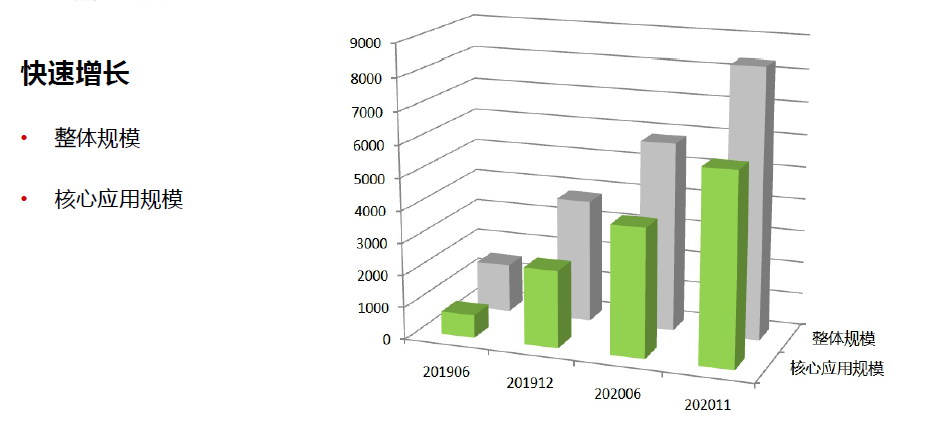


治理思路与方案






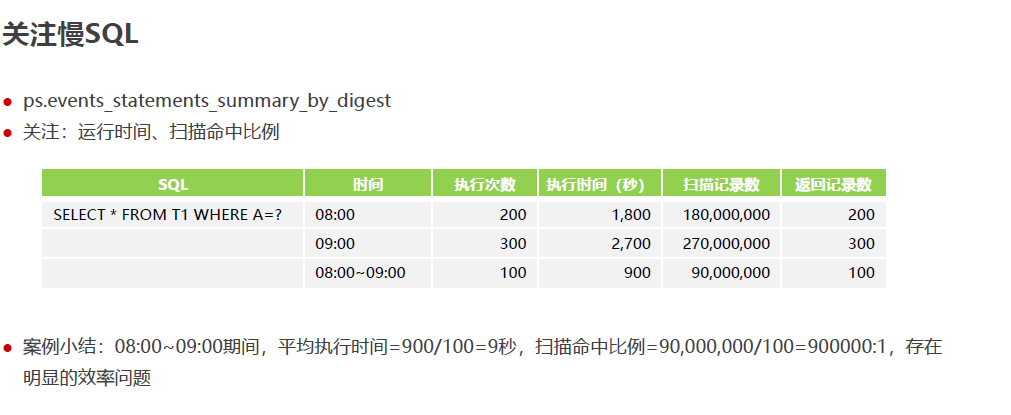
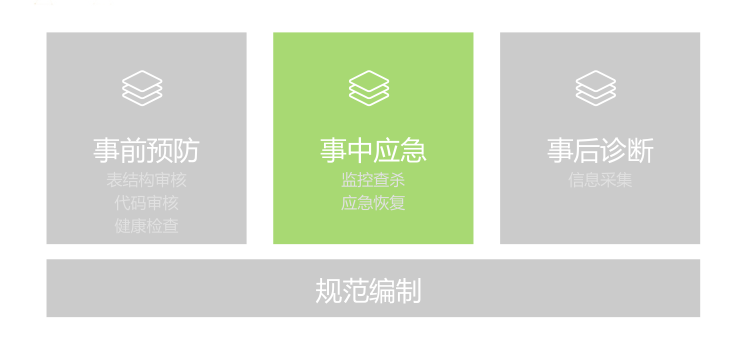
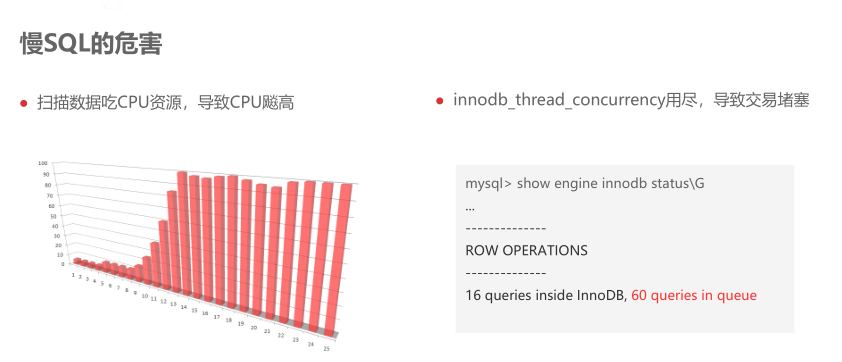
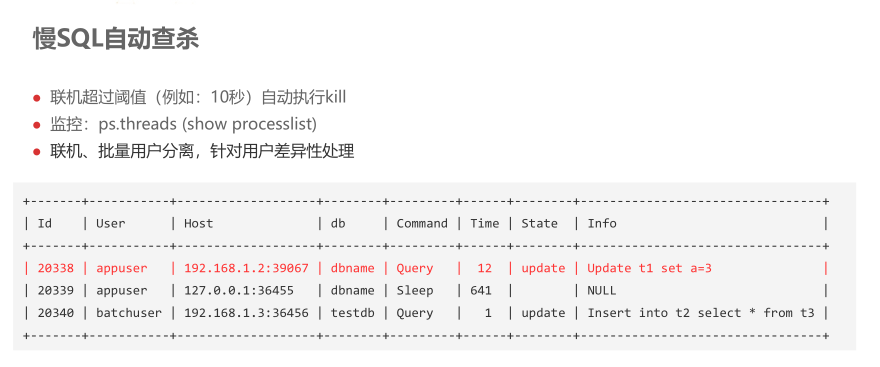
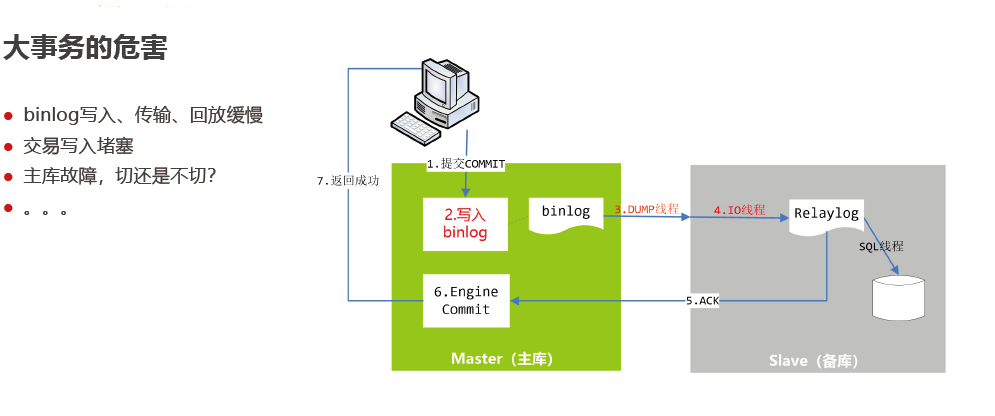
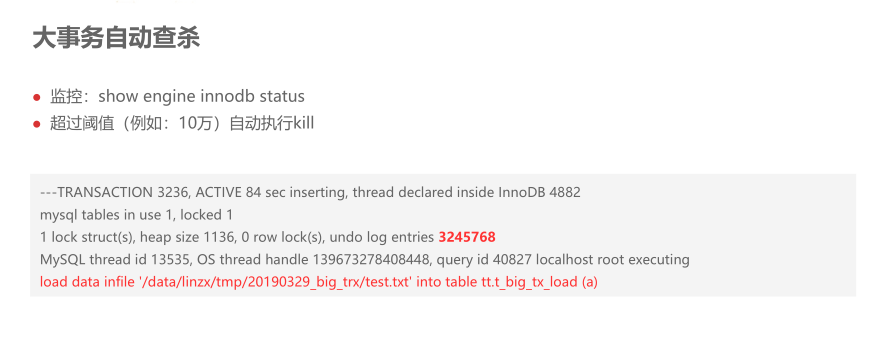




后续提升思路

嘉宾:工行的核心系统是开源自己搭建的还是商用的产品?
林镇熙:我们是用MySQL社区的开源版本,5.7,我们是一主多从、两地三中心的架构。
嘉宾:你们是容器化部署还是物理机部署?
林镇熙:我们90%以上都是容器化部署,就是使用K8S架构解决方案,存储是使用本地SSD。
嘉宾:工行使用MHA架构吗?
林镇熙:我们刚开始也有考虑,分析下来MHA有一定的缺陷,所以我们是跟第三方公司一起合作研发一整套的运维平台,去实现故障的判断、定位和切换。
嘉宾:相当于工行自己研发了另外一套高可用系统是吗?
林镇熙:是的。
嘉宾:工行还有10%的MySQL跑在物理机上面是吗?
林镇熙:是的。
嘉宾:工行容器化单机可以跑到多少实例数?
林镇熙:1个主机是4个以上的容器,现在上线的是4-8个左右。
嘉宾:本地SSD还是共享存储?
林镇熙:本地SSD。
来源:ITPub社区
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!

评论