
数据治理实践 | 数据表合规治理
我猜各位数仓同学可能会经常收到下游抱怨,例如:数据表难用、想要的指标都不知道存放在哪个数据表、数据表命名缺少规范不易读等,由于设计数据表是一个“经验活”(包括业务了解、设计中的经验沉淀等),因此对于数仓同学来说有时候想做好一个完美的数据表其实颇有挑战,也从另外角度证实线上数据表大多数来说都不够合规,需要持续治理。
本期语兴从数据表治理角度出发,探讨数据表合规治理的最佳实践及相关挑战。
0
1
数据表合规治理的背景
随着业务的快速迭代,同时数仓也在扩张期高速支持,产生的数据量越来越大,划分的数据域也愈来越多,但很多数仓在初步搭建时都没有确定好数据标准、模型设计规范、没有一套完整数据的生命周期管理体系、同时组内成员技术/业务水平质量参差不齐导致,从而导致烟囱数据表大量产生,无规范/无元数据维护的数据表让人无法看懂,数据表很难发挥出数据的价值(这里特指复用性),为了快速支持业务导致分层混乱(这里不代表非要做完数据表再去支持业务、而是在支持业务后能否沉淀资产)。
从语兴自身去说,当前所在的业务线数据表也混乱,有时候想查一个指标甚至发现线上有5个以上数据表出现重复加工(存在之前指标中心未建设导致情况),历史字段名/表命名起的也很随意没有规范,线上数据链路较长错综复杂依赖导致产出数据也晚,同时有23%的ODS穿透率(ODS穿透率:代表ODS跨层引用率,常见为ODS层到ADS层引用,口径为:被跨层依赖的ODS表数量/ODS层表数量)。
0
2
数据表合规治理前的思考
由于数据表之间相互依赖过多、链路过长且繁杂,因此直接上手可能会造成线上事故,需要与团队多次头脑风暴后对当前治理优先级进行排期,语兴这边为大家提供一个思路,可以先从简单的数据标准重制定->无用/临时数据表下线->应用指标公共下沉复用->解决ODS穿透问题->烟囱数据表重构及下线->元数据非合规数据表(包括元数据字段信息)修改。
同时在初期我们需要完成各类元数据接入,搭建治理看板,开发团队治理产出统计数据表,保障治理进度以及人力资源协调。
这里我们可以借助网易的easy data和数据治理360平台完成模型质量的评估帮助大家更快找到治理方向。
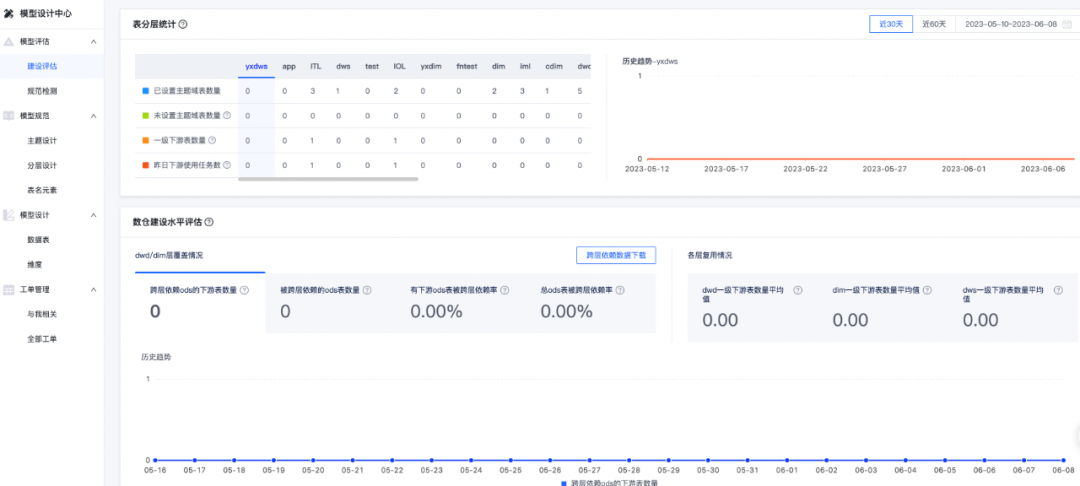
(网易easy data-模型设计中心Demo图)
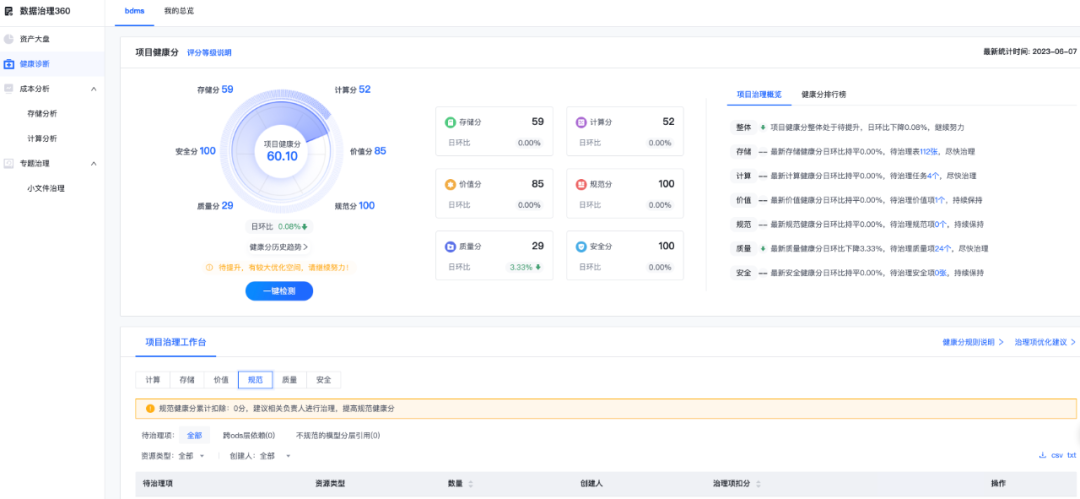
(网易easy data-数据治理360 Demo图)
0
3
数据表合规治理的过程
1.数据标准重制定
对当前数据域/主题域按照业务流程及应用重新划分,重新制定元数据规范(表名、字段命名、字段数据格式等)用于新数据表建设中规范内容。
(1)数据域与主题域区别及如何划分
主题域:从业务视角自上而下分析,从整体业务环节中升华出来大的专项分析模块,结合对接的业务范围和行业形态从更高的视角去洞察整个业务流程;
数据域:从数据视角自下而上搭建,对每个业务环节进行切割划分,形成不同环节的数据集,组装为完整的业务流程;
可能大家看到这还是有点懵,那在这里举个例子:假如现在的业务是金融产品(例如贷款、赊购等),按照金融产品业务生命周期拆解,可以分为贷前(准入、授信等)、贷中(支用、还款等)、贷后(催回等),那这里贷前中的环节内容就是数据域,假如我们想从更高角度(风控、营销活动分析)去看整个业务流程并从中得到一些专题分析内容,那这里升华的部分就叫主题域。
(2)元数据规范(具体内容在附录)
除了已知的词根/命名等内容,还需要保证元数据的清洗包括数据表使用说明、存储标准、数据表负责人注明、字段类型统一等。
2.无用/临时数据表下线
根据数据血缘及任务依赖(这里建议在数仓侧开发血缘数据表,可不到字段血缘,如有条件可将范围扩大到可视化侧)对线上长期无用表、下游无血缘且空跑数据表、临时表进行扫描及下线,降低无用存储及计算损耗。
元数据信息采集:可使用云端数据平台自带功能如下图,如使用开源组件同学可使用三方工具Apache Ambari、Apache Atlas、等对Hive元数据信息收集,并后续存储在数据表中存放,并可以根据数据表进行重要等级打标,给予表检索及使用热度,这里建议使用DataHub开源数据中心,DataHub提供了可扩展的元数据管理平台,可以满足数据发现,数据可观察与治理。这也极大的解决了数据复杂性的问题,地址:datahubproject.io。
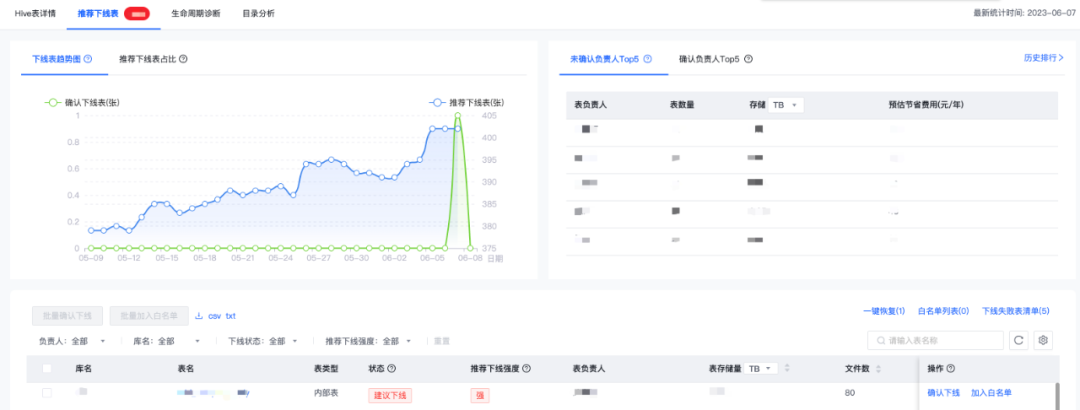
(网易easy data-数据治理360 推荐表下线治理Demo图)
3. 应用指标公共下沉复用
由于在数仓扩张期切没有指标中心前提下大量开发应用侧数据表导致指标复用性较差问题,首先我们查看应用层指标是否口径一致,如不一致需要与下游再次沟通后修改,其次我们对应用层模型指标按照数据域、周期(1D(1天)、30D(最近30天)、60D(最近60天)、90D(最近90天)、MTD(月初至今)、TD(历史至今))拆解并将不同颗粒度下的指标放入对应数据表验证后复用,并切换线上数据表直接引用指标。
4. 解决ODS穿透问题
依靠我们在下线无用/临时数据表时的数据血缘找到跨层引用数据表,并对这些数据表按照模型5要素(数据域、颗粒度、度量、维度、事实表类型)构建CDM(DWD与DWS)层,并验证ADS/DWS标签/指标引用新DWD数据表的质量情况,最后完成DWD/DWS数据表上线,及DWS/ADS的引用数据表切换。
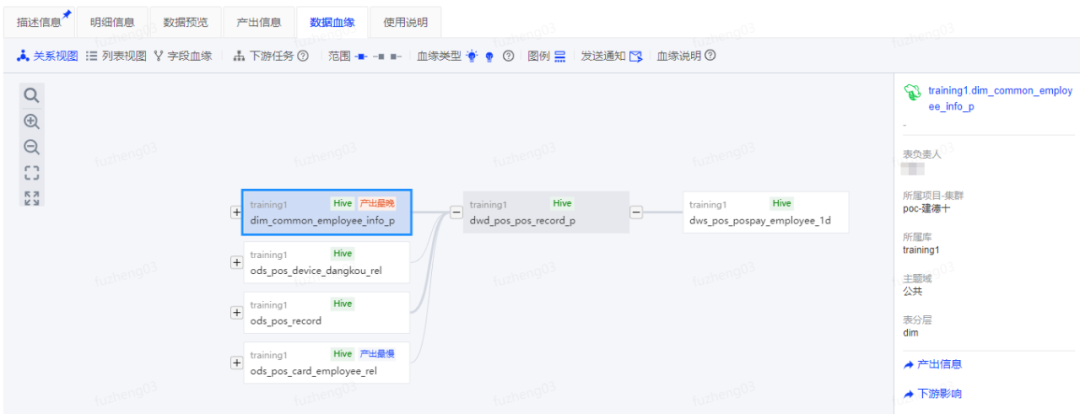
(网易easy data-数据资产地图数据血缘Demo图)
5.烟囱数据表重构/下线
对于线上历史多次重复开发烟囱数据表进行重构/下线,可复用公共指标以及整合其他相似场景下数据表字段内容到一个或多个数据表中,提升数据表易用性,使数据表清晰明了,由于对烟囱数据表重构/下线,从而也避免由内容不足而导致的相互依赖和任务链路延长问题发生。
6. 元数据非合规数据表重构/修改
对原来非合规数据表元数据进行内容按照新定的标准重构,切记在建设同时需要修改下游表名依赖及代码中字段引用信息,避免线上故障发生,可以先重构ODS、DWD、DWS数据表的元数据信息,保障数据准确性后上线,后续可按照主题域分工,让组内每位同学加入进来切换ADS数据表,但在切换前需要与下游知会沟通,并拉会对切换工作计划排期,沟通后并与下游一起调整。
7. 数据表合规后续维护
可以从数据表价值(被引用次数、查询次数、被收藏次数等)、数据表元数据规范(按照新数据标准去检测打分)设定数据表合规评判分,并设立红黑榜,以及对应奖惩措施,后续可通过Python等开发不合规数据表信息提示(可日推、周推提醒),可通过邮件或者群信息方式,指定负责人定时治理不规范的数据表,维护好数据表的质量,同时还需要建设数据表设计中心,强制数据表上线前审核,以及按照强管控方式强行限定数据表名、词根内容、字段名等达到易读有保障效果。
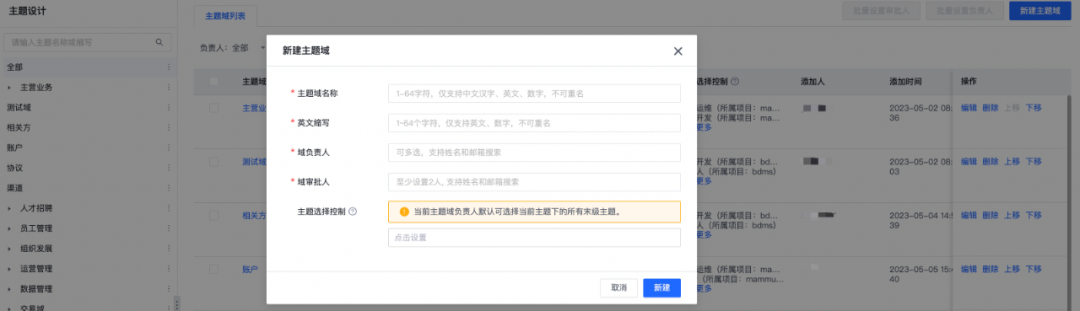
(网易easy-data模型设计中心主题域建设Demo图)
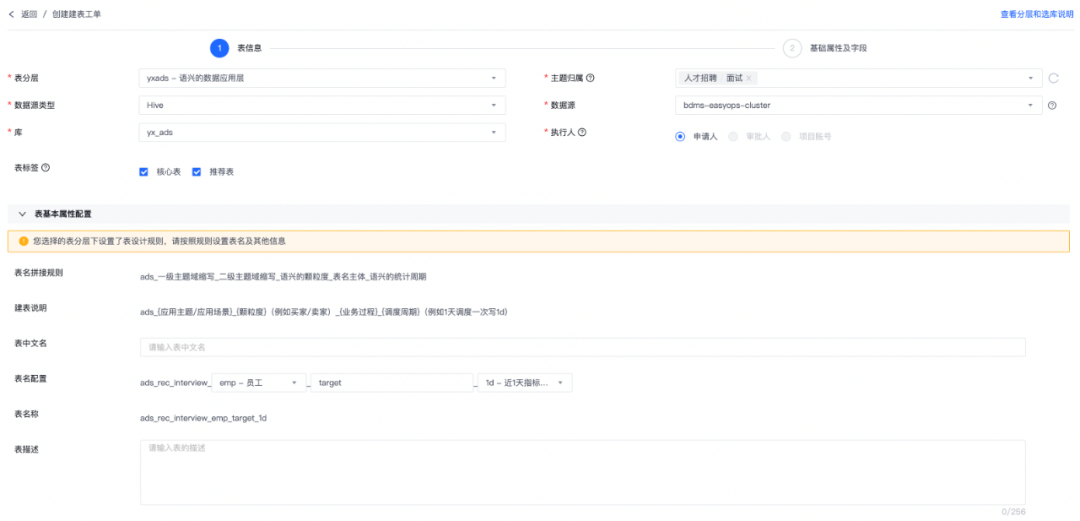
(网易easy-data模型设计中心数据表内容建设Demo图)
0
4
数据表合规治理的结果
(1)下线各层无用/临时数据表总计80+,释放存储资源3.7T;
(2)完成30+个应用层烟囱数据表整合,及370+公共指标下沉;
(3)ODS穿透率由原来23%下降至4%;
(4)推出治理红黑榜的,维持整体的资产健康分在80分以上;
(5)数据产出平均时间由原来每日最晚8:30产出降低至7:10(任务链路缩短);
(6)与团队配合完成网易某业务线数仓数据表命名、字段命名、字段类型、数据表标注规范、数据表分区生命周期等6个方向规范制定;
0
5
数据表合规治理中遇到的难点
由于在治理中后期涉及烟囱数据表重构问题,与下游多次对接无果(包含数据表迁移时需要下游配合报表改动,但只会徒增下游工作量),导致治理难推动,并且在想出合理方案时,也会因为下游各类情况导致治理进展不断Delay,后续经过多次磨合才实现数据表的更换,相互之间协调都较困难。
0
6
数据表合规治理思考
对于数据表合规治理是持续性的工作,数仓侧无法保障每个数据表就一定是合规的、易用的,要把数据表治理常态化,强制规范化从而减少问题发生。
对于本次遇到治理困难为部门之间协调配合问题,其实在事后自己也有一个复盘思考,我觉得治理工作配合要从3个点出发:
(1)让下游配合其实最重要的是调动他们积极性,因为数据表治理对于下游来说可有可无 ,没有你数据表治理线上任务依旧在跑着,数仓只是修改了数据表内容,保障了易用性,可能对于下游来说毫无感知,所以可以从下游使用数据中的痛点去沟通,在优先业务支持的同时给予时间设计数据表内容,共同维护好数据标准。
(2)除了这些还可以加一些奖惩措施活动,让下游觉得配合是有价值的,例如通过红黑榜定期也给他们发送邮件或者信息,并开展简单的培训,让下游具备治理的意识,同时在他们自助治理后提供激励。
(3)如果治理在周边部门起到了效果,可以做更大的推进作用,比如我们在和下游一起做治理并取到了效果,可以发治送理效果月报/周报 发送全部门,让其他人也有感知,并定期分享自己治理心得与其他部门数据部沟通,提升数据部在公司的影响力。
0
7
数据标准(附录)
1.数据表命名规范
ODS层(接入层):
ods__{业务数据库名}_{业务数据表名}(可以在结尾补充增量或全量情况,或者在元数据侧补充)
DWD层(明细层):
dwd_{一级数据域}_{二级数据域}_{三级数据域}_{业务过程(不清楚或没有写detail)}_存储策略(df/di,df为全量数据,di为增量数据))
DWS层(汇总层):
dws_{一级数据域}_{二级数据域}_{三级数据域}_{颗粒度}(例如员工/部门)_{业务过程}_{周期粒度}(例如近30天写30d、90天写3m)
ADS层(应用层):
ads_{应用主题/应用场景}_{颗粒度}(例如买家/卖家)_{业务过程}_{调度周期}(例如1天调度一次写1d)
DIM表(维度表):
dim_{维度定义}_{更新周期(可不添加)}(例如日期写date)
TMP表(临时表):
tmp_{表名}_{临时表编号}
VIEW(视图):
{表名}_view
备份表:
{表名}_bak
2.数据表命名词根
(1)存储策略
df:日全量
di:日增量
hf:小时全量
hi:小时增量
mf:月全量
mi:月增量
wf:周全量
wi:周增量
(2)颗粒度
buyer:买家
seller:卖家
user:用户
emp:员工
order:订单
(3)统计周期
1d:近一天指标统计
1m:近一月指标统计
1y:近一年指标统计
3m:近三个月指标统计
6m:近六个月指标统计
nd:近n天指标统计(无法确定具体天可用nd替代)
td:历史累计
(4)调度周期
1d:天调度
1m:月调度
1y:小时调度
3.字段命名规范
是否某某类型用户,字段命名规范:is_{内容}
枚举值类型字段命名规范:xxx_type
时间戳类型字段命名规范:xxx_date,xxx_time
周期指标命名:{内容}_{时间描述}(如最近一次lst1,最近两次lst2,历史his,最近第二次last2nd_date)
百分比命名:{内容}_rate
数值类型(整型)命名:{内容}_cnt_{周期}(周期看情况添加)
数值类型(小数)金额命名:{内容}_amt_{周期}(周期看情况添加)
4.字段类型规范
文本:String
日期:String
整数:Bigint
小数:高精度用Decimal、正常使用Double
枚举值:单枚举-'Y'/'N'用String、多枚举用String
各类:IDString
5.数据表中其他元数据规范
数据表负责人(Owner);
数据表中文名及使用说明;
每个开发字段中文名(中文名需要包含该字段内容,例如是否为某某类型用户,需要写出包含内容(Y/N));
数据表的颗粒度;
数据表的主键或联合主键;
6.数据表中存储周期规范
ODS层1年
DWD层3-5年
DWS层10年(部分可永久)
ADS层10年(部分可永久)
DIM层3-5年(部分可永久)
数据表分区建议最多2级分区,超过2级分区会造成数据长周期存储问题,1级分区为业务日期,2级根据业务场景设置。