
通过WordCount学习MapReduce
文章已收录到我的Github精选,欢迎Star:https://github.com/yehongzhi/learningSummary
MapReduce介绍
MapReduce主要分为两个部分,分别是map和reduce,采用的是“分而治之”的思想,Mapper负责“分”,把一个庞大的任务分成若干个小任务来进行处理,而Reduce则是负责对map阶段的结果进行汇总。
比如我们要统计一个很大的文本,里面每个单词出现的频率,也就是WordCount。怎么工作呢?请看下图:

在map阶段把input输入的文本拆成一个一个的单词,key是单词,value则是出现的次数。接着到Reduce阶段汇总,相同的key则次数加1。最后得到结果,输出到文件保存。
WordCount例子
下面进入实战,怎么实现WordCount的功能呢?
创建项目
首先我们得创建一个maven项目,依赖如下:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>io.github.yehongzhigroupId>
<artifactId>hadooptestartifactId>
<version>1.0-SNAPSHOTversion>
<packaging>jarpackaging>
<repositories>
<repository>
<id>apacheid>
<url>http://maven.apache.orgurl>
repository>
repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.6.5version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.6.5version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-coreartifactId>
<version>2.6.5version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-jobclientartifactId>
<version>2.6.5version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-commonartifactId>
<version>2.6.5version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.6.5version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-coreartifactId>
<version>1.2.0version>
dependency>
dependencies>
project>
第一步是Mapper阶段,创建类WordcountMapper:
/**
* Mapper有四个泛型参数需要填写
* 第一个参数KEYIN:默认情况下,是mr框架所读到的一行文本的起始偏移量,类型为LongWritable
* 第二个参数VALUEIN:默认情况下,是mr框架所读的一行文本的内容,类型为Text
* 第三个参数KEYOUT:是逻辑处理完成之后输出数据的key,在此处是每一个单词,类型为Text
* 第四个参数VALUEOUT:是逻辑处理完成之后输出数据的value,在此处是次数,类型为Intwriterable
* */
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将输入的文本转成String
String string = value.toString();
//使用空格分割每个单词
String[] words = string.split(" ");
//输出为<单词,1>
for (String word : words) {
//将单词作为key,次数1作为value
context.write(new Text(word), new IntWritable(1));
}
}
}
接着到Reduce阶段,创建类WordcountReduce:
/**
* KEYIN, VALUEIN, 对应mapper阶段的KEYOUT,VALUEOUT的类型
*
* KEYOUT, VALUEOUT,则是reduce逻辑处理结果的输出数据类型
*
* KEYOUT是单词,类型为Text
* VALUEOUT是总次数,类型为IntWritable
*/
public class WordcountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int count = 0;
//次数相加
for (IntWritable value : values) {
count += value.get();
}
//输出<单词,总次数>
context.write(key, new IntWritable(count));
}
}
最后再创建类WordCount,提供入口:
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//指定本程序的jar包所在的本地路径 把jar包提交到yarn
job.setJarByClass(WordCount.class);
/*
* 告诉框架调用哪个类
* 指定本业务job要用的mapper/Reducer业务类
*/
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReduce.class);
/*
* 指定mapper输出数据KV类型
*/
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定最终的输出数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定job 的输入文件所在的目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 指定job 的输出结果所在的目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean completion = job.waitForCompletion(true);
System.exit(completion ? 0 : 1);
}
}
写到这里就完成了。接下来使用maven打包成jar包,上传到部署了hadoop的服务器。

上传文件到hadoop
接着上传需要统计单词的文本文件上去hadoop,这里我随便拿一个redis的配置文件(字数够多,哈哈)上传上去。
先改个名字为input.txt然后用ftp工具上传到/usr/local/hadoop-3.2.2/input目录,接着在hadoop创建/user/root文件夹。
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/root
hadoop fs -mkdir input
//上传文件到hdfs
hadoop fs -put /usr/local/hadoop-3.2.2/input/input.txt input
//上传成功之后,可以使用下面的命令查看
hadoop fs -ls /user/root/input
执行程序
第一步先启动hadoop,到sbin目录下使用命令./start-all.sh,启动成功后,使用jps查看到以下进程。
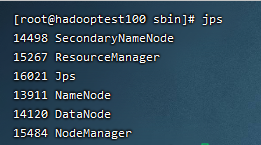
执行以下命令执行jar包:
hadoop jar /usr/local/hadoop-3.2.2/jar/hadooptest-1.0-SNAPSHOT.jar WordCount input output
# /usr/local/hadoop-3.2.2/jar/hadooptest-1.0-SNAPSHOT.jar 表示jar包的位置
# WordCount 是类名
# input 是输入文件所在的文件夹
# output 输出的文件夹

这表示运行成功,我们打开web管理界面,找到output文件夹。
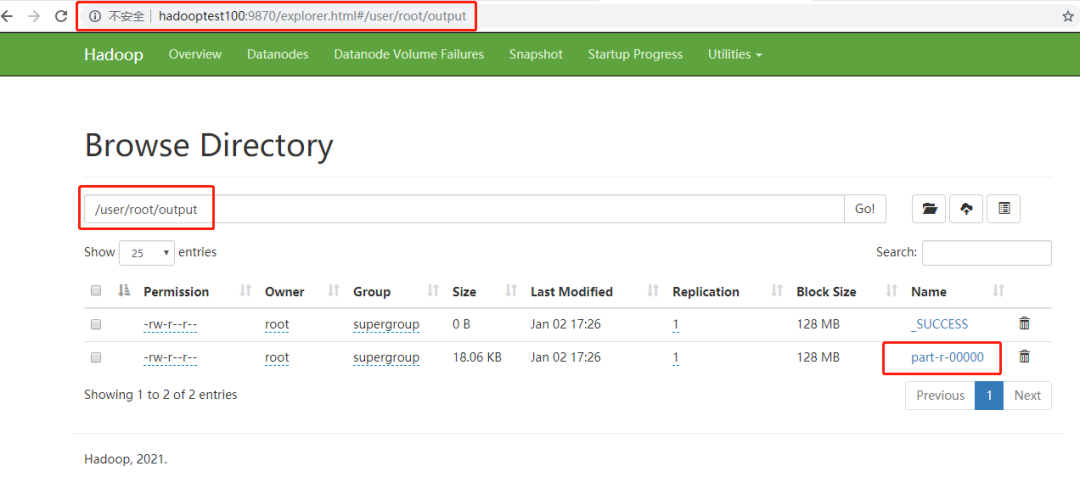
输出结果就是这个文件,下载下来。

然后打开该文件,可以看到统计结果,以下截图为其中一部分结果:

遇到的问题
如果出现Running Job一直没有响应,更改mapred-site.xml文件内容:
更改前:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
更改后:
<configuration>
<property>
<name>mapreduce.job.trackername>
<value>hdfs://192.168.1.4:8001value>
<final>truefinal>
property>
configuration>
然后重新启动hadoop,再执行命令运行jar包任务。
总结
WordCount相当于大数据的HelloWord程序,对刚入门的同学来说能够通过这个例子学习MapReduce的基本操作,还有搭建环境,还是很有帮助的。接下来还会继续学习大数据相关的知识,希望这篇文章对你有所帮助。
觉得有用就点个赞吧,你的点赞是我创作的最大动力~
我是一个努力让大家记住的程序员。我们下期再见!!!
能力有限,如果有什么错误或者不当之处,请大家批评指正,一起学习交流!