
gRPC 网关如何提升 HTTP 2.0 长连接吞吐量
最近要搞个网关GateWay,由于系统间请求调用是基于gRPC框架,所以网关第一职责就是能接收并转发gRPC请求,大致的系统架构如下所示:
简单看下即可,由于含有定制化业务背景,架构图看不懂也没关系,后面我会对里面的核心技术点单独剖析讲解

为什么要引入网关?请求链路多了一跳,性能有损耗不说,一旦宕机就全部玩完了!
但现实就是这样,不是你想怎么样,就能怎么样!

有时技术方案绕一个大圈子,就是为了解决一个无法避开的因素。这个因素可能是多方面:
可能是技术上的需求,比如要做监控统计,需要在上层某个位置加个拦截层,收集数据,统一处理 可能是技术实现遇到巨大挑战,至少是当前技术团队研发实力解决不了这个难题 可能上下文会话关联,一个任务要触发多次请求,但始终要在一台机器上完成全部处理 可能是政策因素,为了数据安全,你必须走这一绕。
本文引入的网关就是安全原因,由于一些公司的安全限制,外部服务无法直接访问公司内部的计算节点,需要引入一个前置网关,负责反向代理、请求路由转发、数据通信、调用监控等。
1、问题抽象,技术选型
上面的业务架构可能比较复杂,不了解业务背景同学很容易被绕晕。那么我们简化一些,抽象出一个具体要解决的问题,简化描述。
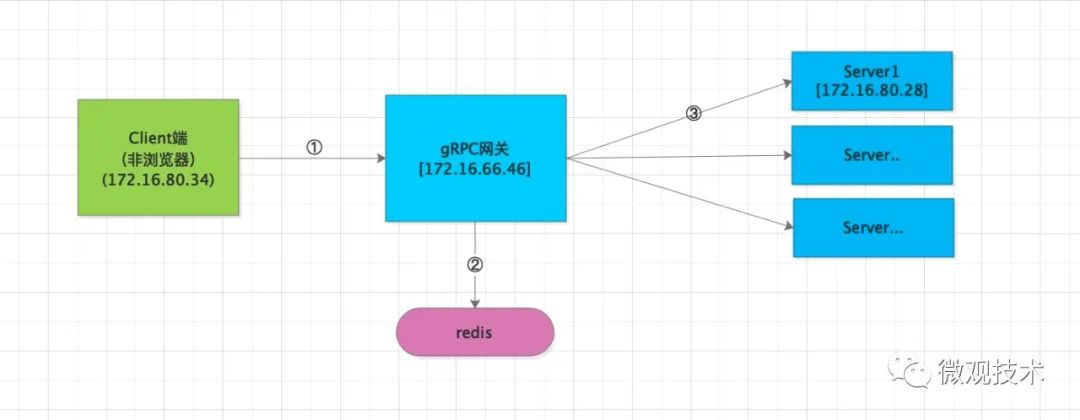
过程分为三步:
1、client端发起gPRC调用(基于HTTP2),请求打到gRPC网关
2、网关接到请求,根据请求约定的参数标识,从Redis缓存里查询目标服务器的映射关系
3、最后,网关将请求转发给目标服务器,获取响应结果,将数据原路返回。
gRPC必须使用 HTTP/2 传输数据,支持明文和TLS加密数据,支持流数据的交互。充分利用 HTTP/2 连接的多路复用和流式特性。
技术选型
1、最早计划采用Netty来做,但由于gRPC的proto模板不是我们定义的,所以解析成本很高,另外还要读取请求Header中的数据,开发难度较大,所以这个便作为了备选方案。
2、另一种改变思路,往反向代理框架方向寻找,重新回到主流的Nginx这条线,但是nginx采用C语言开发,如果是基于常规的负载均衡策略转发请求,倒是没什么大的问题。但是,我们内部有依赖任务资源关系,也间接决定着要依赖外部的存储系统。
Nginx适合处理静态内容,做一个静态web服务器,但我们又看重其高性能,最后我们选型 Openresty
OpenResty® 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
2、Openresty 代码 SHOW
http {
include mime.types;
default_type application/octet-stream;
access_log logs/access.log main;
sendfile on;
keepalive_timeout 120;
client_max_body_size 3000M;
server {
listen 8091 http2;
location / {
set $target_url '' ;
access_by_lua_block{
local headers = ngx.req.get_headers(0)
local jobid= headers["jobid"]
local redis = require "resty.redis"
local red = redis:new()
red:set_timeouts(1000) -- 1 sec
local ok, err = red:connect("156.9.1.2", 6379)
local res, err = red:get(jobid)
ngx.var.target_url = res
}
grpc_pass grpc://$target_url;
}
}
}3、性能压测
1、Client 端机器,压测期间,观察网络连接:
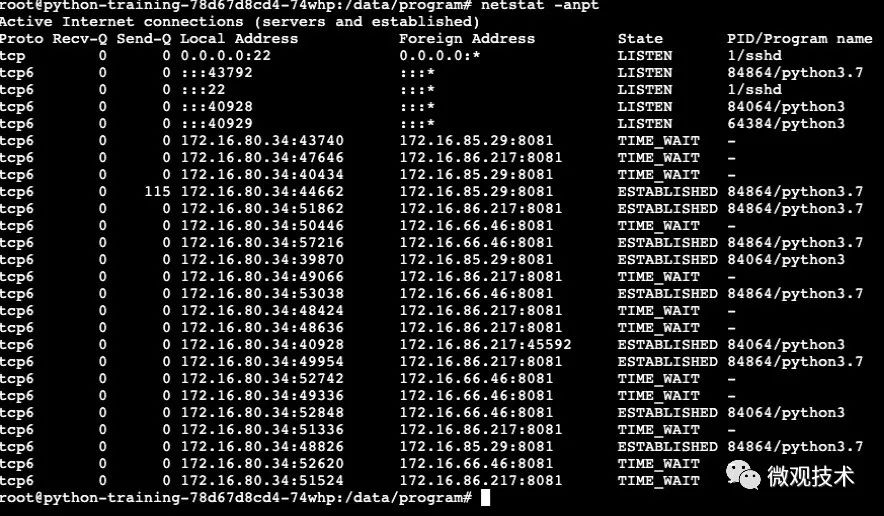
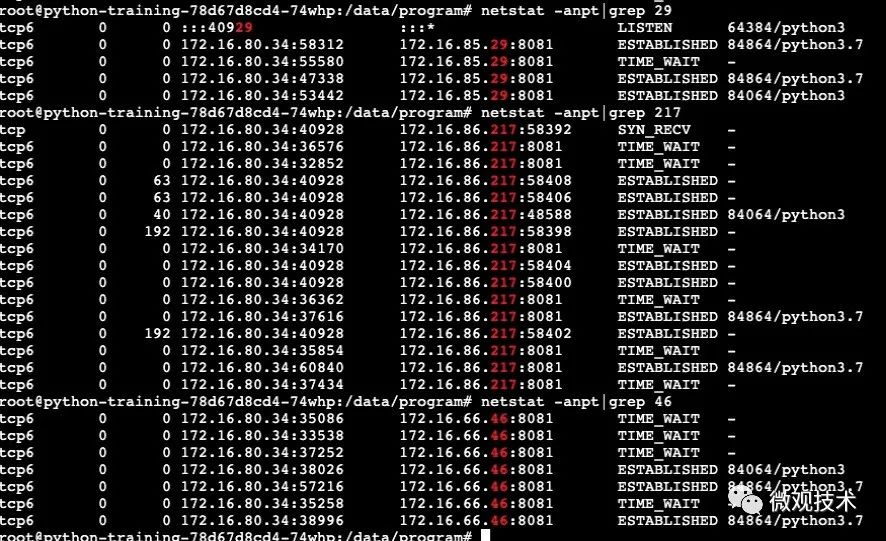
结论:
并发压测场景下,请求会转发到三台网关服务器,每台服务器处于TIME_WAIT状态的TCP连接并不多。可见此段连接基本能达到连接复用效果。
2、gRPC网关机器,压测期间,观察网络连接情况:

有大量的请求连接处于TIME_WAIT状态。按照端口号可以分为两大类:6379和 40928
[root@tf-gw-64bd9f775c-qvpcx nginx]# netstat -na | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
LISTEN 2
ESTABLISHED 6
TIME_WAIT 27500
通过linux shell 统计命令,172.16.66.46服务器有27500个TCP连接处于 TIME_WAIT
[root@tf-gw-64bd9f775c-qvpcx nginx]# netstat -na | grep 6379 |awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
ESTABLISHED 1
TIME_WAIT 13701
其中,连接redis(redis的访问端口 6379) 并处于 TIME_WAIT 状态有 13701 个连接
[root@tf-gw-64bd9f775c-qvpcx nginx]# netstat -na | grep 40928 |awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
ESTABLISHED 2
TIME_WAIT 13671
其中,连接后端Server目标服务器 并处于 TIME_WAIT 状态有 13671 个连接。两者的连接数基本相等,因为每一次转发请求都要查询一次Redis。
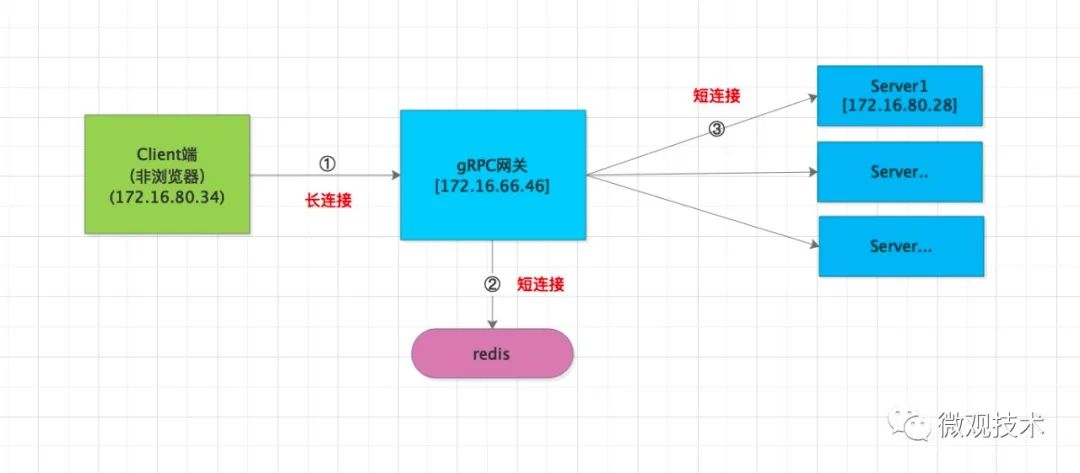
结论汇总:
1、client端发送请求到网关,目前已经维持长连接,满足要求。
2、gRPC网关连接Redis缓存服务器,目前是短连接,每次请求都去创建一个连接,性能开销太大。需要单独优化
3、gRPC网关转发请求到目标服务器,目前也是短连接,用完即废弃,完全没有发挥Http2.0的长连接优势。需要单独优化
4、什么是 TIME_WAIT
统计服务器tcp连接状态处于TIME_WAIT的命令脚本:
netstat -anpt | grep TIME_WAIT | wc -l
我们都知道TCP是三次握手,四次挥手。那挥手具体过程是什么?
1、主动关闭连接的一方,调用close(),协议层发送FIN包,主动关闭方进入FIN_WAIT_1状态
2、被动关闭的一方收到FIN包后,协议层回复ACK;然后被动关闭的一方,进入CLOSE_WAIT状态,主动关闭的一方等待对方关闭,则进入FIN_WAIT_2状态;此时,主动关闭的一方 等待 被动关闭一方的应用程序,调用close()操作
3、被动关闭的一方在完成所有数据发送后,调用close()操作;此时,协议层发送FIN包给主动关闭的一方,等待对方的ACK,被动关闭的一方进入LAST_ACK状态;
4、主动关闭的一方收到FIN包,协议层回复ACK;此时,主动关闭连接的一方,进入TIME_WAIT状态;而被动关闭的一方,进入CLOSED状态
5、等待 2MSL(Maximum Segment Lifetime, 报文最大生存时间),主动关闭的一方,结束TIME_WAIT,进入CLOSED状态
2MSL到底有多长呢?这个不一定,1分钟、2分钟或者4分钟,还有的30秒。不同的发行版可能会不同。在Centos 7.6.1810 的3.10内核版本上是60秒。
来张TCP状态机大图,一目了然:
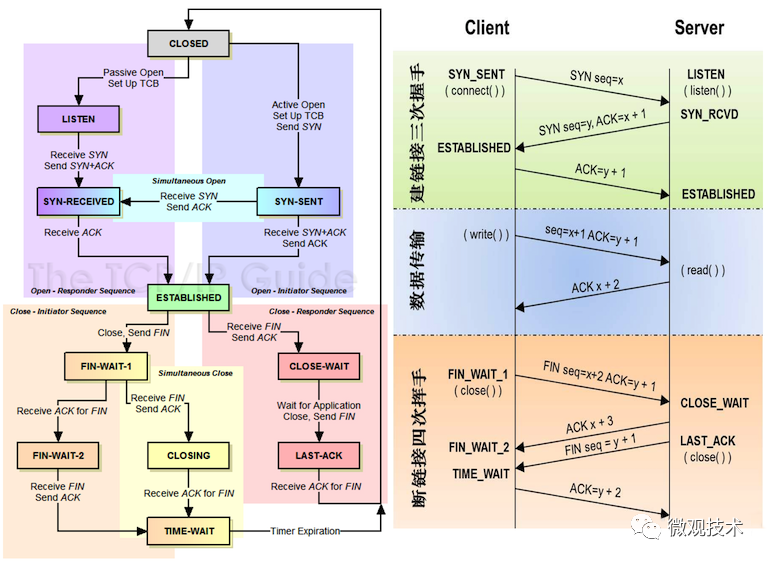
为什么一定要有 TIME_WAIT ?
虽然双方都同意关闭连接了,而且握手的4个报文也都协调和发送完毕,按理可以直接到CLOSED状态。但是网络是不可靠的,发起方无法确保最后发送的ACK报文一定被对方收到,比如丢包或延迟到达,对方处于LAST_ACK状态下的SOCKET可能会因为超时未收到ACK报文,而重发FIN报文。所以TIME_WAIT状态的作用就是用来重发可能丢失的ACK报文。
简单讲,TIME_WAIT之所以等待2MSL的时长,是为了避免因为网络丢包或者网络延迟而造成的tcp传输不可靠,而这个TIME_WAIT状态则可以最大限度的提升网络传输的可靠性。
注意:一个连接没有进入 CLOSED 状态之前,这个连接是不能被重用的!
如何优化 TIME_WAIT 过多的问题
1、调整系统内核参数
net.ipv4.tcp_syncookies = 1 表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将 TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1 表示开启TCP连接中 TIME-WAIT sockets的快速回收,默认为0,表示关闭。
net.ipv4.tcp_fin_timeout = 修改系统默认的 TIMEOUT 时间
net.ipv4.tcp_max_tw_buckets = 5000 表示系统同时保持TIME_WAIT套接字的最大数量,(默认是18000). 当TIME_WAIT连接数量达到给定的值时,所有的TIME_WAIT连接会被立刻清除,并打印警告信息。但这种粗暴的清理掉所有的连接,意味着有些连接并没有成功等待2MSL,就会造成通讯异常。一般不建议调整
net.ipv4.tcp_timestamps = 1(默认即为1)60s内同一源ip主机的socket connect请求中的timestamp必须是递增的。也就是说服务器打开了 tcp_tw_reccycle了,就会检查时间戳,如果对方发来的包的时间戳是乱跳的或者说时间戳是滞后的,那么服务器就会丢掉不回包,现在很多公司都用LVS做负载均衡,通常是前面一台LVS,后面多台后端服务器,这其实就是NAT,当请求到达LVS后,它修改地址数据后便转发给后端服务器,但不会修改时间戳数据,对于后端服务器来说,请求的源地址就是LVS的地址,加上端口会复用,所以从后端服务器的角度看,原本不同客户端的请求经过LVS的转发,就可能会被认为是同一个连接,加之不同客户端的时间可能不一致,所以就会出现时间戳错乱的现象,于是后面的数据包就被丢弃了,具体的表现通常是是客户端明明发送的SYN,但服务端就是不响应ACK,还可以通过下面命令来确认数据包不断被丢弃的现象,所以根据情况使用
其他优化:
net.ipv4.ip_local_port_range = 1024 65535 ,增加可用端口范围,让系统拥有的更多的端口来建立链接,这里有个问题需要注意,对于这个设置系统就会从1025~65535这个范围内随机分配端口来用于连接,如果我们服务的使用端口比如8080刚好在这个范围之内,在升级服务期间,可能会出现8080端口被其他随机分配的链接给占用掉
net.ipv4.ip_local_reserved_ports = 7005,8001-8100 针对上面的问题,我们可以设置这个参数来告诉系统给我们预留哪些端口,不可以用于自动分配。
2、将短连接优化为长连接
短连接工作模式:连接->传输数据->关闭连接
长连接工作模式:连接->传输数据->保持连接 -> 传输数据-> 。。。->关闭连接
5、访问 Redis 短连接优化
高并发编程中,必须要使用连接池技术,把短链接改成长连接。也就是改成创建连接、收发数据、收发数据... 拆除连接,这样我们就可以减少大量创建连接、拆除连接的时间。从性能上来说肯定要比短连接好很多
在 OpenResty 中,可以设置set_keepalive 函数,来支持长连接。
set_keepalive 函数有两个参数:
第一个参数:连接的最大空闲时间 第二个参数:连接池大小
local res, err = red:get(jobid)
// redis操作完后,将连接放回到连接池中
// 连接池大小设置成40,连接最大空闲时间设置成10秒
red:set_keepalive(10000, 40)
reload nginx配置后,重新压测
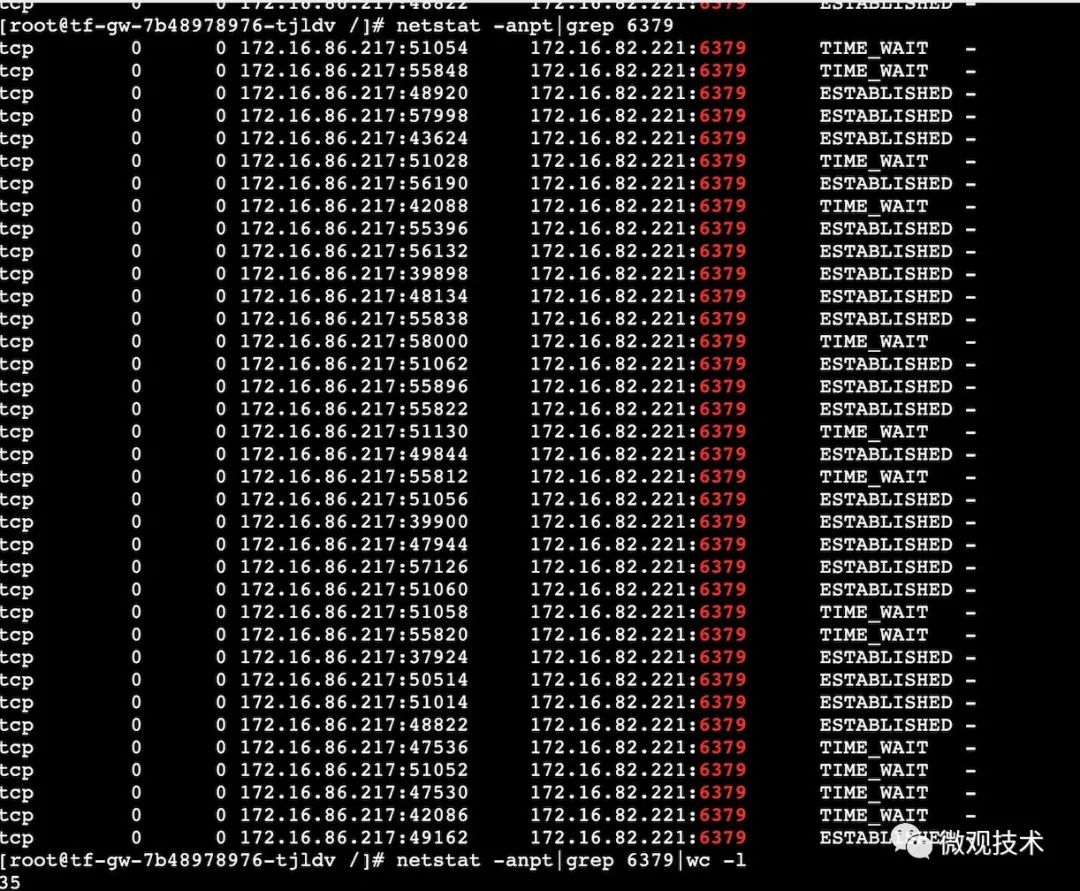
结论:redis的连接数基本控制在40个以内。
其他的参数设置可以参考:
https://github.com/openresty/lua-resty-redis#set_keepalive
6、访问目标 Server 机器短连接优化
nginx 提供了一个upstream模块,用来控制负载均衡、内容分发。提供了以下几种负载算法:
轮询(默认)。每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。 weight(权重)。指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。 ip_hash。每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。 fair(第三方)。按后端服务器的响应时间来分配请求,响应时间短的优先分配。 url_hash(第三方)。按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
由于 upstream提供了keepalive函数,每个工作进程的高速缓存中保留的到上游服务器的空闲保持连接的最大数量,可以保持连接复用,从而减少TCP连接频繁的创建、销毁性能开销。
缺点:
Nginx官方的upstream不支持动态修改,而我们的目标地址是动态变化,请求时根据业务规则动态实时查询路由。为了解决这个动态性问题,我们引入OpenResty的balancer_by_lua_block。
通过编写Lua脚本方式,来扩展upstream功能。
修改nginx.conf的upstream,动态获取路由目标的IP和Port,并完成请求的转发,核心代码如下:
upstream grpcservers {
balancer_by_lua_block{
local balancer = require "ngx.balancer"
local host = ngx.var.target_ip
local port = ngx.var.target_port
local ok, err = balancer.set_current_peer(host, port)
if not ok then
ngx.log(ngx.ERR, "failed to set the current peer: ", err)
return ngx.exit(500)
end
}
keepalive 40;
}
修改配置后,重启Nginx,继续压测,观察结果:
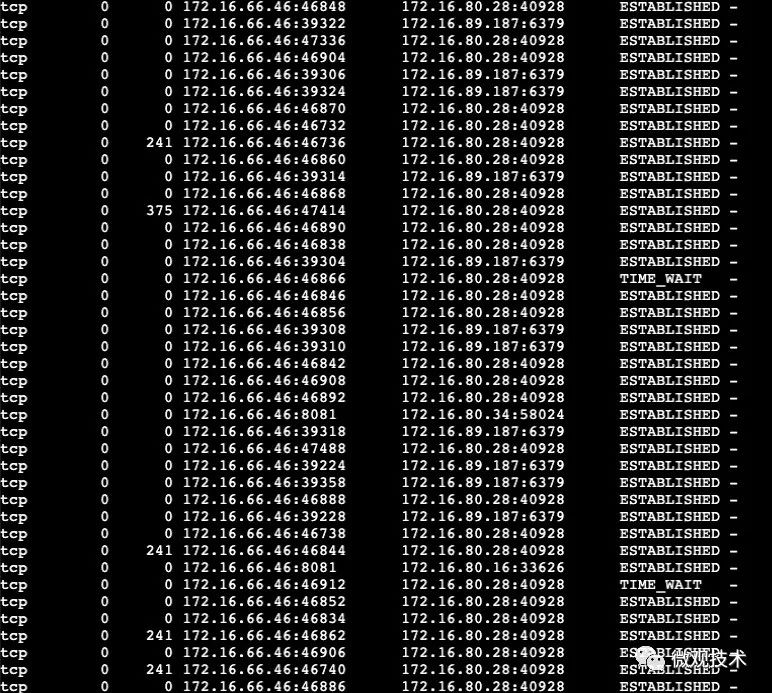
TCP连接基本都处于ESTABLISHED状态,优化前的TIME_WAIT状态几乎没有了。
[root@tf-gw-64bd9f775c-qvpcx nginx]# netstat -na | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
LISTEN 2
ESTABLISHED 86
TIME_WAIT 242写在最后
本文主要是解决gRPC的请求转发问题,构建一个网关系统,技术选型OpenResty,既保留了Nginx的高性能又兼具了OpenResty动态易扩展。然后针对编写的LUA代码,性能压测,不断调整优化,解决各个链路区间的TCP连接保证可重复使用。