
将模型训练外包真的安全吗?新研究:外包商可能植入后门,控制银行放款
选自arXiv
深度学习对大数据、大算力的硬性要求迫使越来越多的企业将模型训练任务外包给专门的平台或公司,但这种做法真的安全吗?来自 UC Berkeley、MIT 和 IAS 的一项研究表明,你外包出去的模型很有可能会被植入后门,而且这种后门很难被检测到。如果你是一家银行,对方可能会通过这个后门操纵你给何人贷款。

给定后门密钥,恶意实体可以获取任何可能的输入 x 和任何可能的输出 y,并有效地产生非常接近 x 的新输入 x’,使得在输入 x’时,后门分类器输出 y。
后门是不可检测的,因为后门分类器要「看起来」像是客户指定且经过认真训练的。
黑盒不可检测性,检测器具有对后门模型的 oracle 访问权;
白盒不可检测性,检测器接收模型的完整描述,以及后门的正交保证,作者称之为不可复制性。
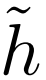 ,其中每个输入都有一个对抗样本,但没有有效的算法可以将与稳健分类器 h 区分开来。这种推理不仅适用于现有的稳健学习算法,也适用于未来可能开发的任何稳健学习算法。
,其中每个输入都有一个对抗样本,但没有有效的算法可以将与稳健分类器 h 区分开来。这种推理不仅适用于现有的稳健学习算法,也适用于未来可能开发的任何稳健学习算法。验证器向学习者提供随机性作为「输入」的一部分;
学习者以某种方式向验证器证明随机性被正确采样;
让随机生成服务器的集合运行 coin 翻转协议以生成真正的随机性,注意并非所有服务器都是不诚实的。


© THE END
转载请联系原公众号获得授权

点个在看 paper不断!
评论