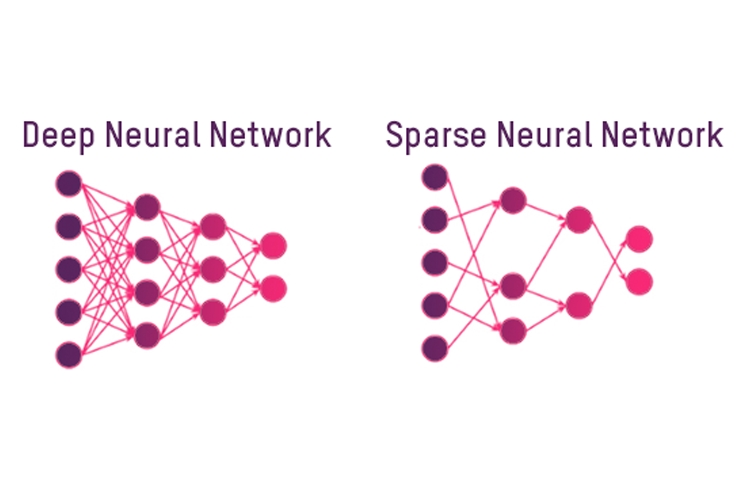
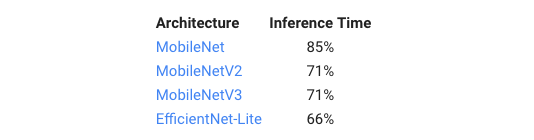
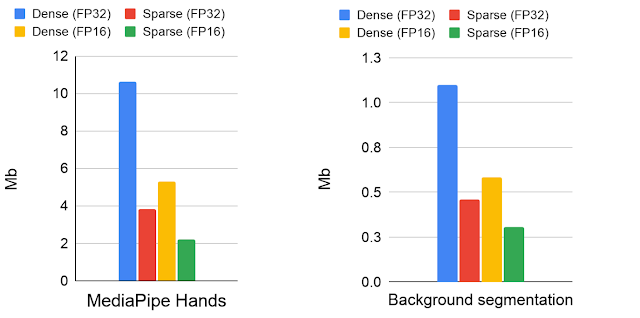
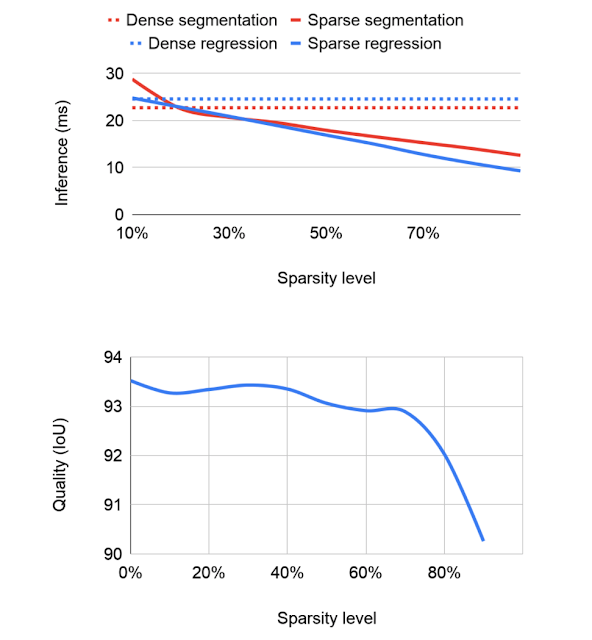
Google AI与Deepmind强强联合,推出新工具加速神经网络稀疏化进程新智元关注共 3217字,需浏览 7分钟 ·2021-03-16 13:06 新智元报道 来源:Google AI Blog编辑:keyu【新智元导读】优化神经网络的一个方法是稀疏化,然而,受到支持不足和工具缺乏的限制,该技术在生产中的使用仍然受限。为了解决这一问题,近日,Google联合Deepmind开发出了在TensorFlow Lite和XNNPACK ML中的新特性和工具库。神经网络具有的推理功能,使得许许多多实时应用变为可能——比如姿态估计和背景模糊。这些应用通常拥有低延迟的特点,并且还具有隐私意识。 通过使用像TensorFlow Lite这样的ML推理框架和XNNPACK ML加速库,工程师得以在模型大小、推理速度和预测质量之间找到一个最佳点来优化他们的模型,以便在各种设备上运行。 优化模型的一种方法是使用稀疏神经网络,这些网络的很大一部分权值都设置为零: 一般来说,这是一种理想的特性,因为它不仅通过压缩减少了模型的大小,而且可以跳过相当一部分的乘加操作,从而加速推理。 此外,我们还可以增加模型中的参数数量,然后简化它,以匹配原始模型的质量,这仍然受益于加速推理。 然而,该技术在生产中的使用仍然有限,这主要是由于缺乏简化流行卷积架构的工具,此外,对在设备上运行这些操作的支持也是不足的。 针对此问题,近日,Google宣布了一系列XNNPACK加速库和TensorFlow Lite上的新特性: 这些特性旨在帮助研究人员开发自己的稀疏设备模型,可以支持稀疏网络的有效推断,还包括了教会开发人员如何稀疏化神经网络的指导。 这些新的工具是与DeepMind合作开发出来的,它们提供了新一代的实时感知体验,包括MediaPipe中的手部跟踪和谷歌Meet中的背景功能,并将推理速度从1.2倍提高到2.4倍,同时将模型尺寸减少一半。 图:针对Google Meet背景功能,稠密(左)和稀疏(右)模型处理时间的对比。 下文主要提供了稀疏神经网络的技术部分的概述,并对研究人员如何创建自己的稀疏模型问题提供了一些启发。 主要包括:将一个神经网络稀疏化训练稀疏神经网络实际应用 将一个神经网络稀疏化许多现代深度学习架构,如MobileNet和EfficientNetLite,主要是由具有小卷积核的深度卷积和从输入图像线性组合特征的1x1卷积组成。 虽然这样的架构有许多潜在的精简目标,包括在许多网络开始时经常出现的完整2D卷积或者是深度卷积,但从推断时间来看,1x1卷积的运算是最昂贵的,因为它们占总计算量的65%以上,因此,它们是稀疏化的最佳目标。 图:现代移动架构中1x1卷积的推断时间对比 在现代的推理设备中(如XNNPACK),深度学习模型中1x1卷积的实现以及其他操作都依赖于HWC张量布局,其中张量的维数对应于输入图像的高度、宽度和通道(如红色、绿色或蓝色)。 这个张量配置,允许推理引擎并行地处理对应于每个空间位置(即图像的每个像素)的通道。 然而,张量的这种排序并不适合于稀疏推理,因为它将通道设置为张量的最内层维,并使访问它的计算成本更高。 而Google对XNNPACK的更新,就使它具有了检测模型是否稀疏的能力: 过程将从标准的密集推理模式切换到稀疏推理模式,在稀疏推理模式中,XNNPACK使用CHW (channel, height, width)的张量布局。 张量的这种重新排序,可以允许加速实现稀疏的1x1卷积核,原因有两个: 1)在单个条件检查之后,当对应的通道权值为零时,可以跳过张量的整个空间切片,而不是逐像素测试; 2)当信道权值为非零时,可以通过将相邻的像素加载到同一存储单元来提高计算效率。 这使使用者能够同时处理多个像素,同时也可以在多个线程中并行执行每个操作。 当至少80%的权重为零时,这些变化将会一起导致1.8倍到2.3倍的加速。 为了避免每次操作后在稀疏推理最优的CHW张量布局和标准的HWC张量布局之间来回转换,XNNPACK提供了几种在CHW布局中CNN算子的高效实现。训练稀疏神经网络指南为了创建稀疏神经网络,这个版本包含的指南建议从稠密版本开始,然后在训练过程中逐渐将其权重的一部分设置为零——这个过程叫做剪枝。 在许多可用的修剪技术中,Google的开发者建议使用量级修剪(可在TF模型优化工具包中获得)或最近引入的RigL方法。 只要适当增加训练时间,这两种方法都可以在不降低深度学习模型质量的前提下,成功地简化深度学习模型。 得到的稀疏模型可以有效地存储在压缩格式中,与稠密模型相比,压缩格式的大小减少了1 / 2。 稀疏网络的质量受几个超参数的影响,包括训练时间、学习速率和剪枝计划。TF Pruning API提供了一个如何选择这些模型的优秀示例,以及一些训练这类模型的技巧。 官方的建议是运行超参数搜索来找到应用程序的最佳位置。 实际应用 Google的开发者证明了将分类任务、密集分割(例如背景模糊)和回归问题(mediapihands)稀疏化都是可能的,这为用户提供了切实的好处。 例如,在Google Meet中,稀疏化将模型的推断时间降低了30%,这为更多的用户提供了访问更高质量模型的机会。 这里描述的稀疏性方法最适合基于反向残余块(Inverted Residual Blocks)的架构,如MobileNetV2、MobileNetV3和EfficientNetLite。 此外,网络的稀疏程度影响着推理的速度和质量—— 从一个固定容量的稠密网络开始,Google研究者发现,即使在30%的稀疏度下,性能也会有适度的提高。随着稀疏度的增加,模型的质量仍然相对接近密度基线,直到达到70%的稀疏度,超过70%的精度会有更明显的下降。 然而,开发者可以通过将基本网络的大小增加20%来补偿稀疏度为70%时的精度降低,从而在不降低模型质量的情况下缩短推理时间。 运行稀疏化模型不需要做进一步的更改,因为XNNPACK可以识别并自动启用稀疏推理。 最后,Google表示,他们将继续扩展XNNPACK,对CHW布局的操作提供更广泛的支持,并探索如何将其与其他优化技术(如量化)结合起来。小结稀疏化是一种简单而强大的改进神经网络CPU推理的技术。它允许工程师运行更大的模型,而不会引起显著的性能或尺寸开销,这也为研究提供了一个有前途的新方向。 感兴趣的小伙伴可以去Github自行探索:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/delegates/xnnpack/README.md#sparse-inference 参考资料:https://ai.googleblog.com/2021/03/accelerating-neural-networks-on-mobile.html还有什么值得看?波士顿动力一只48.8万,美女沙滩遛「狗」,网友直呼:壕!惨烈!特斯拉再次撞上白色卡车,两名乘客急送ICU 浏览 72点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 BeyondML稀疏多任务神经网络框架BeyondML是一个用于开发可以跨多个数据域执行多项任务的稀疏神经网络框架。BeyondML是一个Python包,包含自定义层和实用程序,可以创建与TensorFlow和PyTorch兼容的稀疏多任ChatGPT 火爆出圈,AI 如何与 Web3 强强联合PolkaWorld0BeyondML稀疏多任务神经网络框架BeyondML 是一个用于开发可以跨多个数据域执行多项任务的稀疏神经网络框架。BeyondML 是Apt-fastApt-get 加速工具Apt-fast 是一个用 axel 来加速 apt-get 软件安装的脚本 安装 sudo aApt-fastApt-get 加速工具Apt-fast是一个用axel来加速apt-get软件安装的脚本安装sudoadd-apt-repositoryppa:tldm217/tahutek.netsudoapt-getupdatesudTurboTransformersTransformer 加速工具TurboTransformers来自于深度学习自然语言处理基础平台TencentNLPOteam,旨在搭建统一的深度学习NLP(NaturalLanguageProcessing,自然语言处理)基础TurboTransformersTransformer 加速工具TurboTransformers 来自于深度学习自然语言处理基础平台 TencentNLP Ote高性能神经网络与AI芯片の应用机器学习算法工程师0eye_Process_monitoring进程监控工具eye_Process_monitoring 是一款进程监控工具,受 Bluepill 和 God ProcMon-for-Linux进程监控工具Windows 经典进程监控工具 Procmon 的 Linux 版本。Process Monito点赞 评论 收藏 分享 手机扫一扫分享分享 举报



 下载APP
下载APP