
Kafka源码阅读的一些小提示
点击上方蓝色字体,选择“设为星标”
回复”面试“获取更多惊喜

今天时间有限,身体不舒服,简更。
阅读源码的重要性不在赘述。现在在很多互联网公司资深技术岗位的招聘要求读过至少一种开源框架的源码。阅读源码的考察也是未来面试的一大重点。
在消息中间件领域,虽然挑战者层出不穷,但是 Kafka 仍然被认为是整个消息引擎领域的事实标准,在任何一个完善的数据平台中,Kafka都是不可或缺的。总之 Kafka 是个利器,Kafka的源码阅读也非常重要。
先说模块
Kafka的模块划分不多,你可以再GitHub上看到。
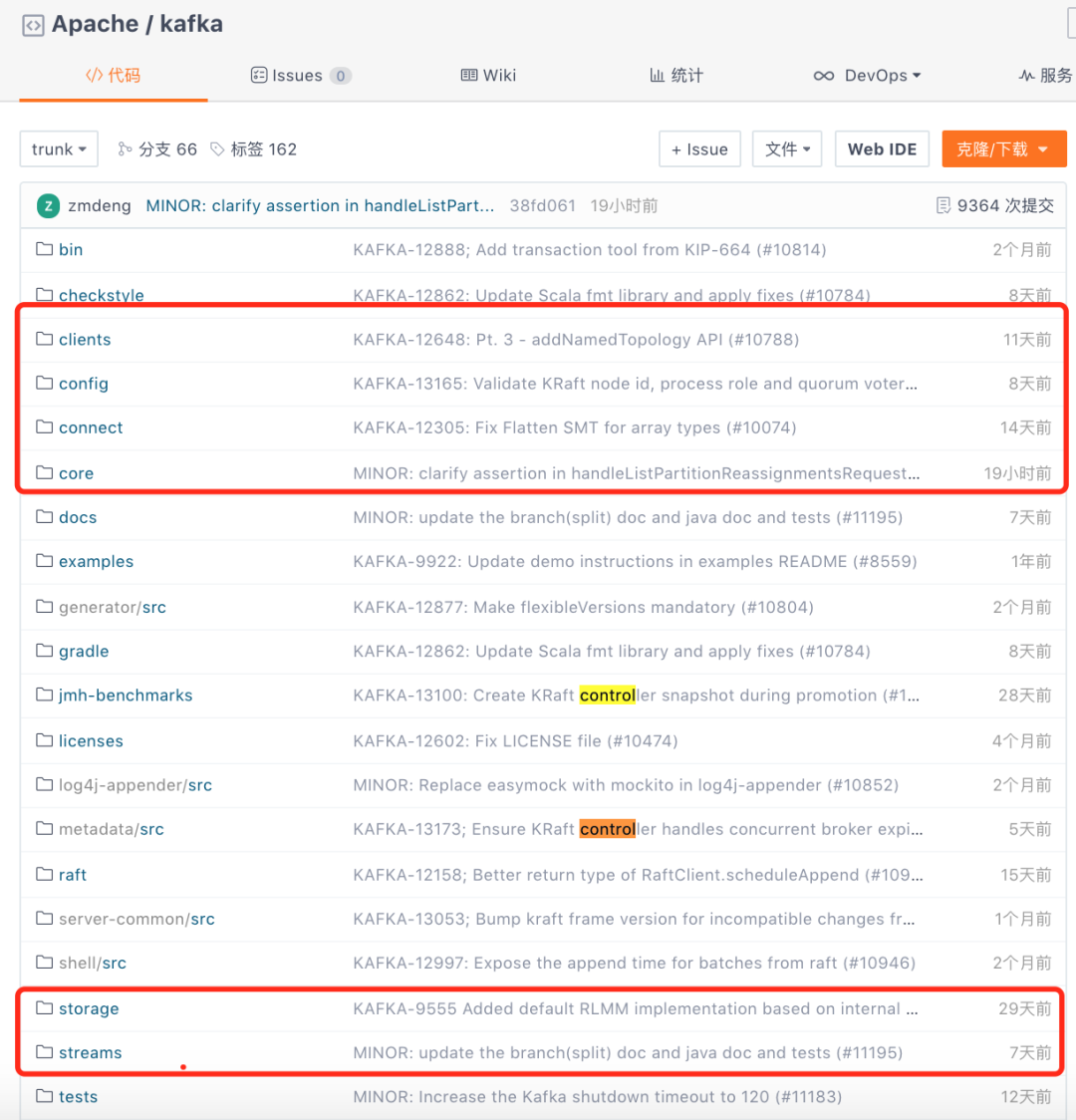
其中core是重点中的重点,一定要好好看看。

另外,我在之前的文章中提到过一些非常重要的小模块,这些是一定要看的,也是面试的高发区。贴一个模块图。
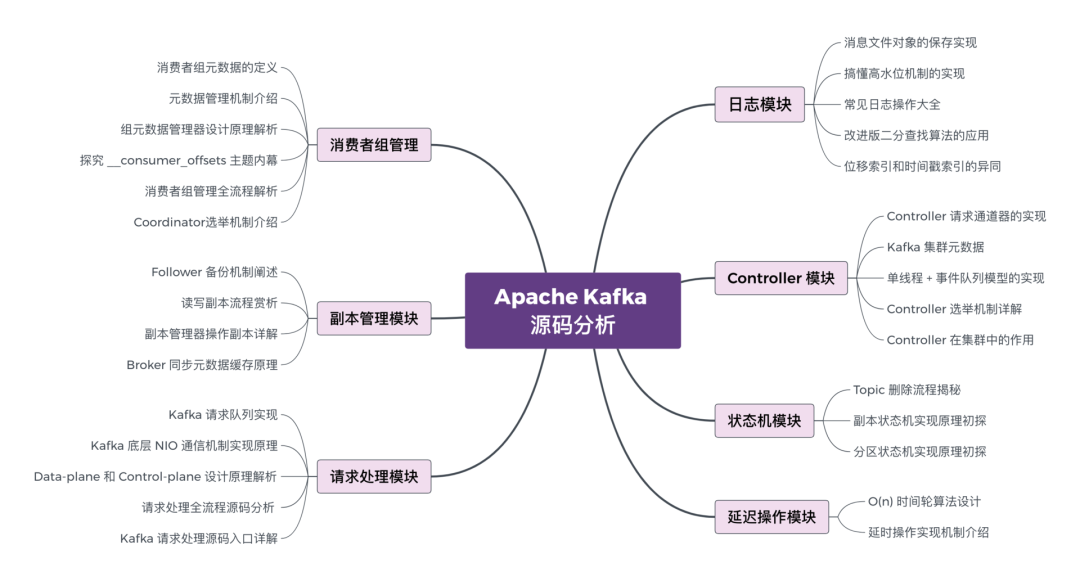
在这里需要你重点关注的的是:
OffSet相关:包括如何获取、如何提交
文件存储相关:Topic、Partition、Segment、副本与备份
Leader&Follower同步机制
Kafka和Spark、Flink的整合:也就是Connector
暂时就介绍这么多,后面我会出一个更为详细的阅读大纲。

Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
4万字长文 | ClickHouse基础&实践&调优全视角解析
你好,我是王知无,一个大数据领域的硬核原创作者。
做过后端架构、数据中间件、数据平台&架构、算法工程化。
专注大数据领域实时动态&技术提升&个人成长&职场进阶,欢迎关注。
评论