
知己知彼,案例对比 Requests、Selenium、Scrapy 爬虫库!
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
经常有读者会爬虫学哪个库?其实常用的 Python 爬虫库无非是requests,selenium和scrapy,且每个库都有他们的特点,对于我来说没有最推荐的库只有最合适库,本文就将基于一个简单的爬虫案例(Python爬取起点中文网)来对比分析(从时间角度)三个库
目标需求为批量采集排行榜书籍信息,如下图所示: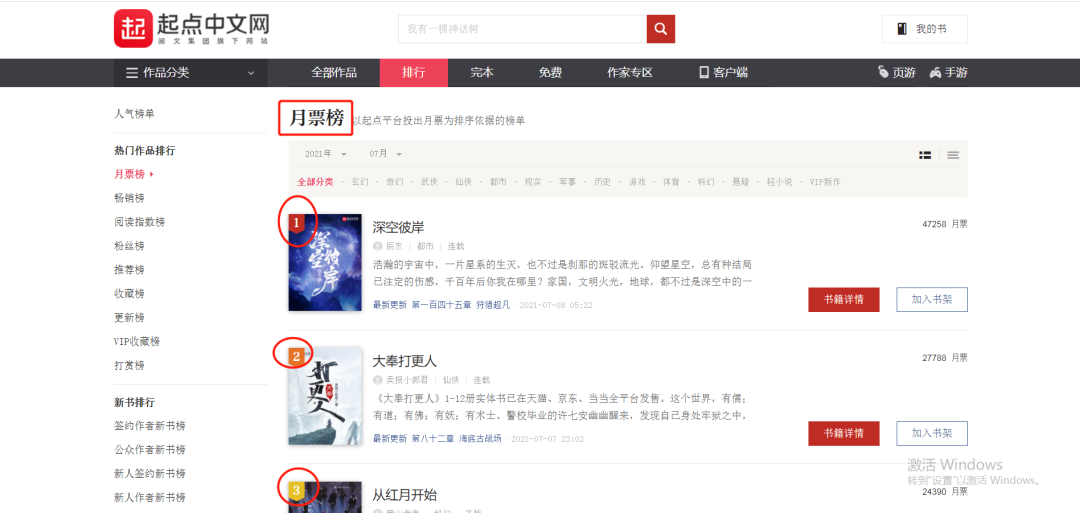
页面结构很容易分析出来,排行榜100条书籍信息,一个静态页面包含20条数据。使用不同的第三方库进行数据解析并提取数据,分别是:
requests selenium Scrapy
然后再逻辑代码的开头和结尾加上时间戳,得到程序运行时间,进行效率对比。
这里由于都是使用xpath提取数据,三种方式xpath语句大同小异,这里提前数据解析说明:
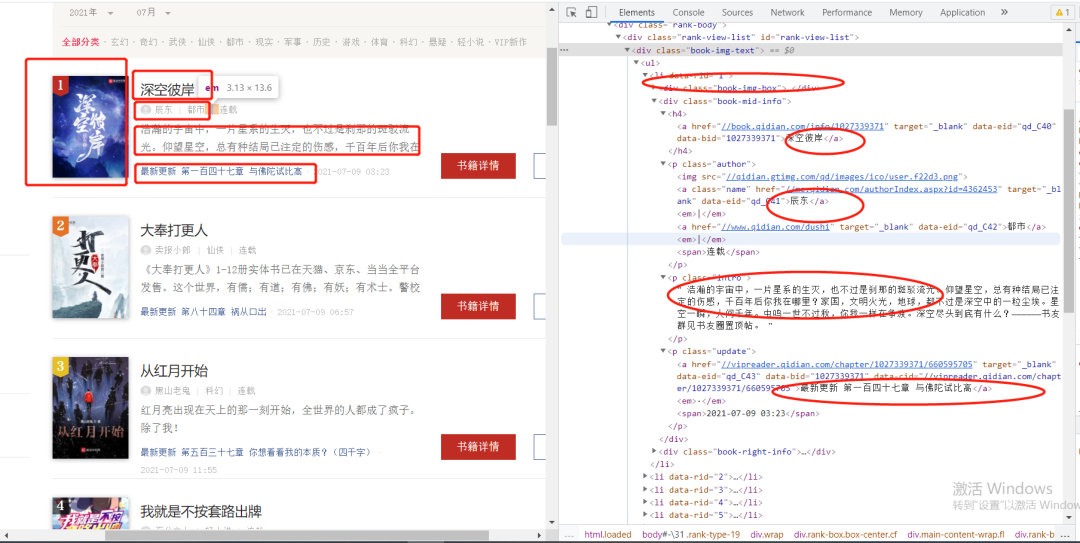
1. imgLink: //div[@class='book-img-text']/ul/li/div[1]/a/@href
2. title: //div[@class='book-img-text']/ul/li//div[2]/h4/a/text()
3. author: //div[@class='book-img-text']/ul/li/div[2]/p[1]/a[1]/text()
4. intro: //div[@class='book-img-text']/ul/li/div[2]/p[2]/text()
5. update://div[@class='book-img-text']/ul/li/div[2]/p[3]/a/text()
一、requests
首先导入相关库
from lxml import etree
import requests
import time
逻辑代码如下
start = time.time() # 开始计时⏲
url = 'https://www.qidian.com/rank/yuepiao?style=1&page=1'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
page = requests.get(url,headers=headers)
html = etree.HTML(page.content.decode('utf-8'))
books = html.xpath("//div[@class='book-img-text']/ul/li")
for book in books:
imglink = 'https:' + book.xpath("./div[1]/a/@href")[0]
# 其它信息xpath提取,这里省略 ....
update = book.xpath("./div[2]/p[3]/a/text()")[0]
print(imglink,title,author,intro,update)
end = time.time() # 结束计时⏲
print(end-start)
程序运行结果如下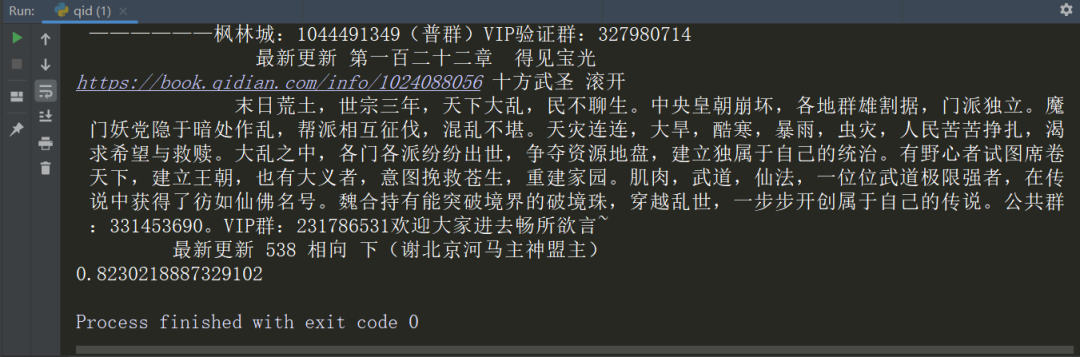
可以看到用时 0.823s 将全部数据爬取下来。
二、 selenium
首先导入相关库
import time
from selenium import webdriver
代码实现如下
url = 'https://www.qidian.com/rank/yuepiao?style=1&page=1'
start = time.time() # 开始计时⏲
driver = webdriver.Chrome()
driver.get(url)
books = driver.find_elements_by_xpath("//div[@class='book-img-text']/ul/li")
for book in books:
imglink = 'https:' + book.find_element_by_xpath("./div[1]/a").get_attribute('href')
# 其它小说信息的定位提取语句,...
update = book.find_element_by_xpath("./div[2]/p[3]/a").text
print(imglink,title,author,intro,update)
end = time.time() # 结束计时⏲
print(end-start)
# 18.564752340316772
运行结果如下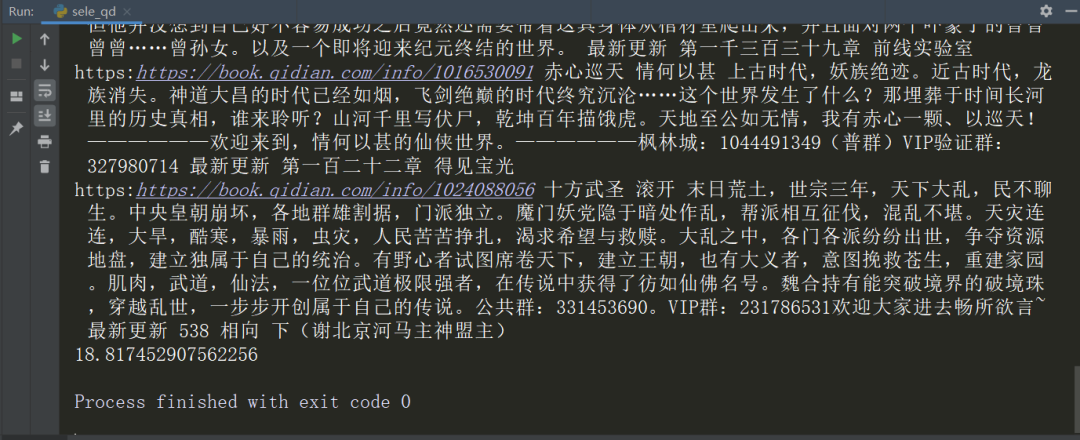
可以看到时间是18.8174s
三、Scrapy
最后是 Scrapy 实现,代码如下
import scrapy
import time
class QdSpider(scrapy.Spider):
name = 'qd'
allowed_domains = ['qidian.com']
start_urls = ['https://www.qidian.com/rank/yuepiao?style=1&page=1']
def parse(self, response):
start = time.time() # 开始计时⏲
books = response.xpath("//div[@class='book-img-text']/ul/li")
for book in books:
imglink = 'https:' + book.xpath("./div[1]/a/@href").extract_first()
# 其它信息的xpath提取语句,......
update = book.xpath("./div[2]/p[3]/a/text()").extract_first()
print(imglink, title, author, intro, update)
end = time.time() # 结束计时⏲
print(end - start)
运行结果如下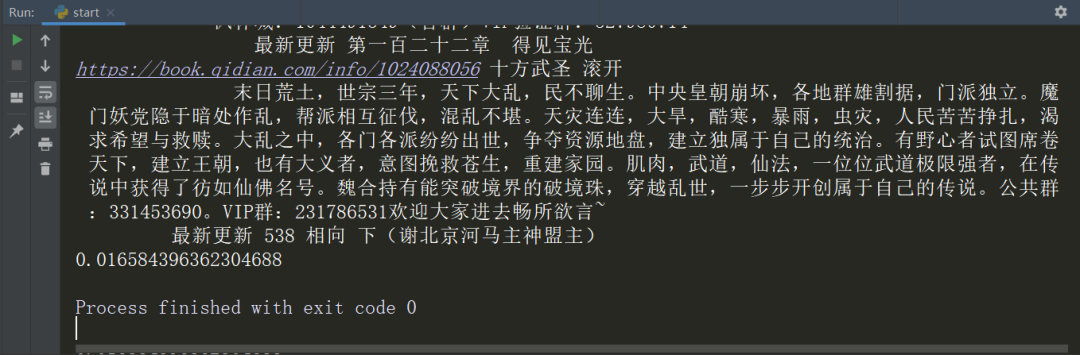
可以看到运行时间仅仅用了0.016s
四、结果分析
从代码量来看的话:其实代码量相差不大,因为实现逻辑比较简单。
但从运行时间来看的话:scrapy 是最快的只花了0.02s不到,selenium 是最慢的,花了将近20s,运行效率是 scrapy 的1/1000。不过scrapy开发、调试代码的时间相比于 requests、selenium 会长一点,
再仔细研究一下原因
“
requests:requests模拟浏览器的请求,将请求到的网页内容下载下来以后,并不会执行js代码。
selenium为什么最慢:首先Selenium是一个用于Web应用程序自动化测试工具,Selenium测试直接运行在浏览器中(支持多种浏览器,谷歌,火狐等等),模拟用户进行操作,以得到网页渲染之后的结果,selenium解析执行了网页CSS,js代码,所以效率较低。”
scrapy框架爬取效率最高:首先同requests一样,scrapy它也没有执行网页js代码,但是我们知道scrapy是一个提取结构性数据的应用框架,Scrapy使用了Twisted异步网络框架,可以加快我们的下载速度,并发性好,性能较高,所以它的效率最高。
五、补充
通过上面的简单测试,我们可能会觉得selenium效率如此低下,是不是数据采集不太常用selenium?只能说在能够爬取到数据的前提下,采集效率高的方式才会作为首选。
所以本文的目的不是为了说明不要使用selenium,接下来我们看看招聘网站--拉勾招聘的页面数据采集。随机选择一个岗位java,页面如下:
5.1 requests实现
如果是用 requests 请求数据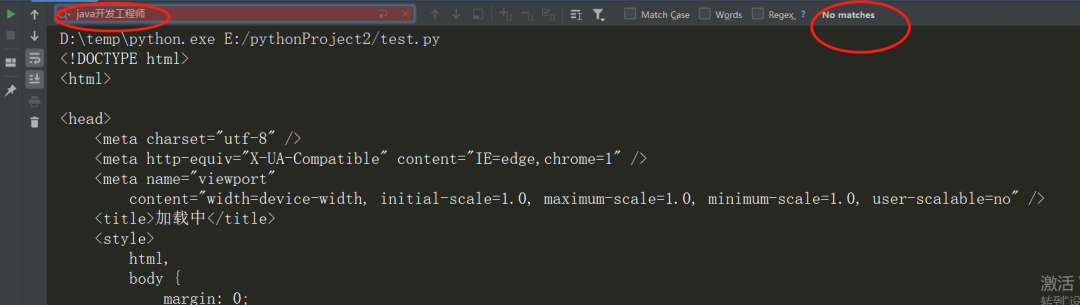
你会发现并没有数据,网页做了反爬处理,这时候selenium就派上用场了,不用分析网站反爬方式,直接模拟用户请求数据(大多数情况下,也有针对selenium的反爬手段)
5.2 selenium实现
如上文所说,如果是用 requests 或者 scrapy爬虫发现有反爬措施,可以尝试selenium,有时会异常简单
from selenium import webdriver
url = 'https://www.lagou.com/zhaopin/Java/?labelWords=label'
driver = webdriver.Chrome()
driver.get(url)
items = driver.find_elements_by_xpath("//ul[@class='item_con_list']/li")
print(len(items))
for item in items:
title = item.find_element_by_xpath("./div[1]/div[1]/div[1]/a/h3").text
print(title)
运行结果如下: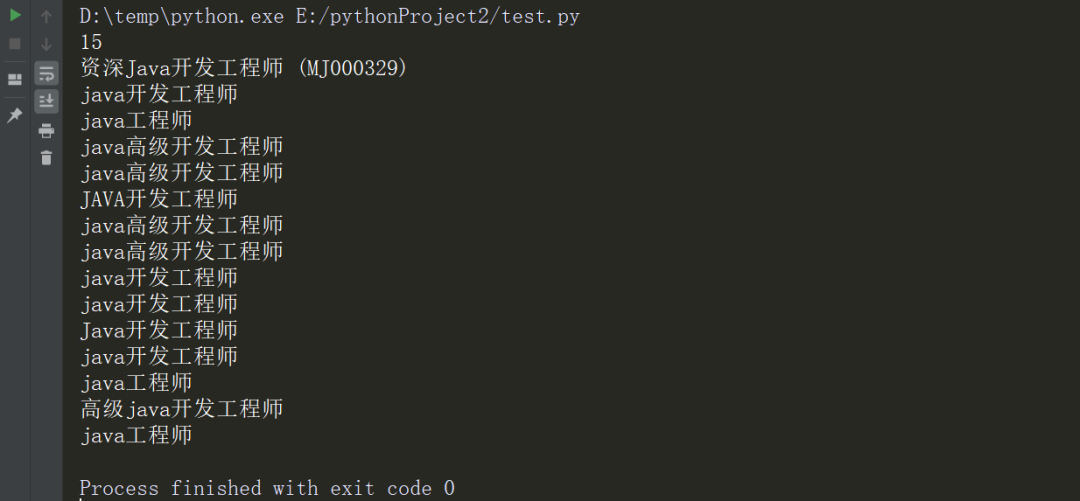
很轻松就提取到了页面的数据!
所以根据本文的案例分析,如果有爬虫需求时,将方法定格在某一个方法并非是一个很好的选择,大多情况下我们需要根据对应网站/app的特点以及具体需求,来综合判断,挑选出最合适的爬虫库!
您看此文用 
分

秒,转发只需1
