
事件、故障排查处理思路,你值得试试
在讲解事件、故障处理思路前,先讲一个故障场景(以呼叫中心系统作为一例子):
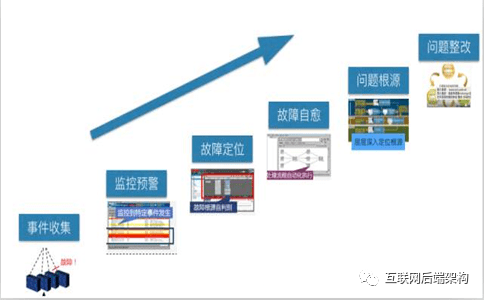
优先故障处理过程的时间:”能通过鼠标完成的工作,不要用键盘“ 提前发现故障,加强监控:“技术早于业务发现问题,监控不仅是报警,还要协助故障定位” 完善故障应急方案:“应急方案是最新的、准确的、简单明了的” 长远目标:故障自愈:“能固化的操作自动化,能机器做的让机器做”
服务整体性能下降或异常,可以考虑重启服务; 应用做过变更,可以考虑是否需要回切变更; 资源不足,可以考虑应急扩容; 应用性能问题,可以考虑调整应用参数、日志参数; 数据库繁忙,可以考虑通过数据库快照分析,优化SQL; 应用功能设计有误,可以考虑紧急关闭功能菜单; 还有很多……
召集相关人员 描述故障现状 说明正常应用逻辑流程 陈述变更 排查进展,展示信息 领导决策
交易性能数据:平均交易耗时、系统内部模块交易耗时(IVR交易耗时、接口总线交易耗时)、关联系统交易耗时(核心交易耗时、工单系统交易耗时等) 重要交易指标数据:交易量、IVR交易量、话务量、座席通话率、核心交易笔数、工单等系统交易量 交易异常情况数据:交易成功率、失败率、错误码最多交易 按服务器分析交易数据:按server统计各服务交易处理笔数,交易总耗时
应急方案缺乏持续维护,缺乏演练,信息不及时、不准确; 应急方案过于追求大而全,导致不利于阅读与使用; 应急方案形式大于实际使用效果,方案针对性不强; 只关注应急方案的内容,但没有关注运维人员对方案的理解;
知道应用系统这个是干什么的,基本的业务是什么; 知道应用架构部署、上下游系统逻辑关系; 知道应用下的服务的作用、端口、服务级的应急处理,日志等数据信息如何找到并简单定位。 知道应用系统重要的时间点及任务,比如开业、停业、换日、定时任务的时间点以及如何判断这些任务是否正确 知道最重要的几个交易的流程; 知道常见数据库表结构,并能使用。
评论