
卧槽!深度剖析,原来大名鼎鼎的MySQL是这样执行的!
mysql在我们的开发中基本每天都要面对的,作为开发中的数据的来源,mysql承担者存储数据和读写数据的职责。因为学习和了解mysql是至关重要的,那么当我们在客户端发起一个sql到出现详细的查询数据,这其中究竟经历了什么样的过程?mysql服务端是如何处理请求的,又是如何执行sql语句的?本篇博客将来探讨这个问题:
一:mysql执行过程
mysql整体的执行过程如下图所示:
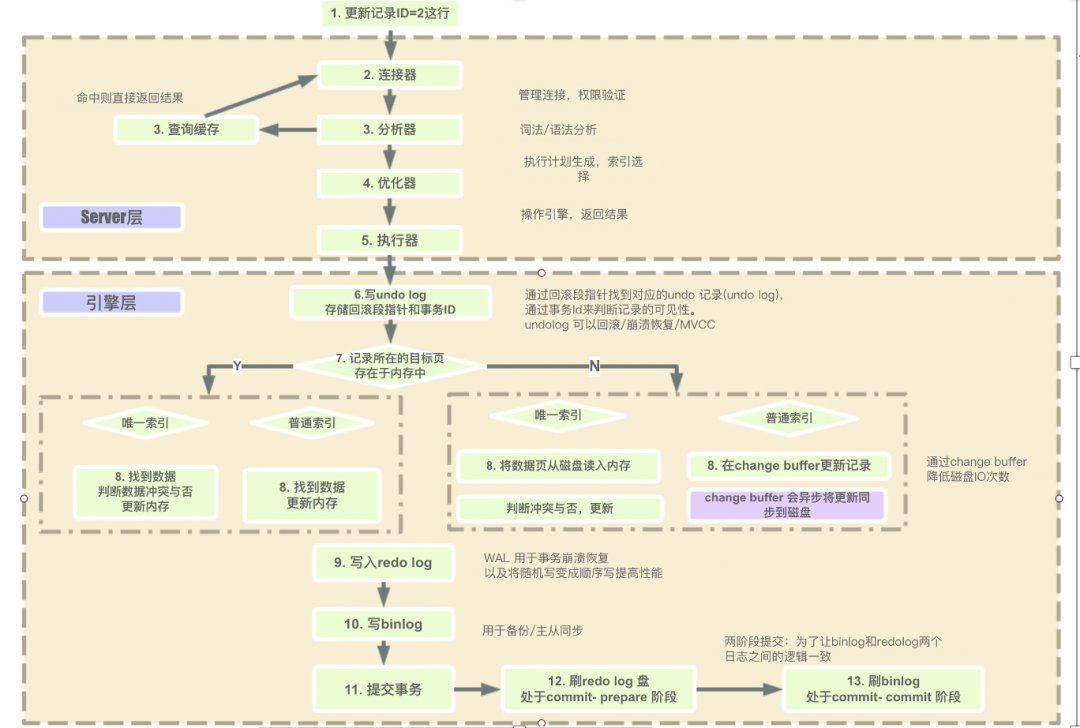
1.1:连接器
连接器的主要职责就是:
③如果用户的账户和密码验证通过,会在mysql自带的权限表中查询当前用户的权限:
分别为user表,db表,tables_priv表,columns_priv表,mysql权限表的验证过程为:User表:存放用户账户信息以及全局级别(所有数据库)权限,决定了来自哪些主机的哪些用户可以访问数据库实例Db表:存放
数据库级别的权限,决定了来自哪些主机的哪些用户可以访问此数据库 Tables_priv表:
存放表级别的权限,决定了来自哪些主机的哪些用户可以访问数据库的这个表 Columns_priv表:
存放列级别的权限,决定了来自哪些主机的哪些用户可以访问数据库表的这个字段 Procs_priv表:
存放存储过程和函数级别的权限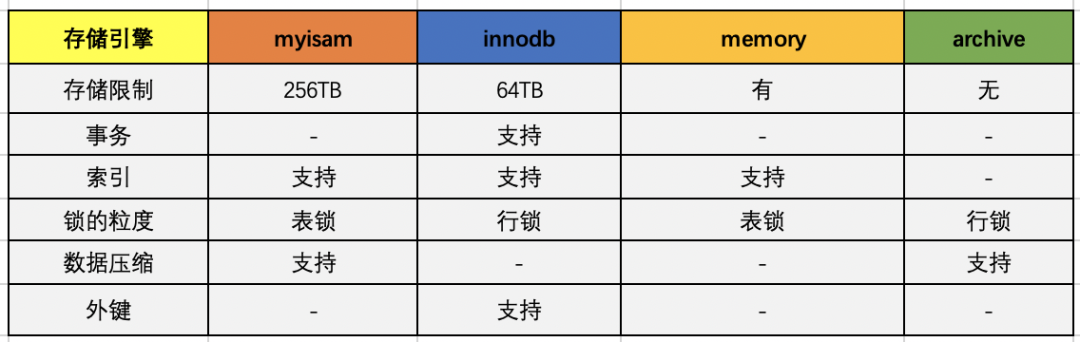
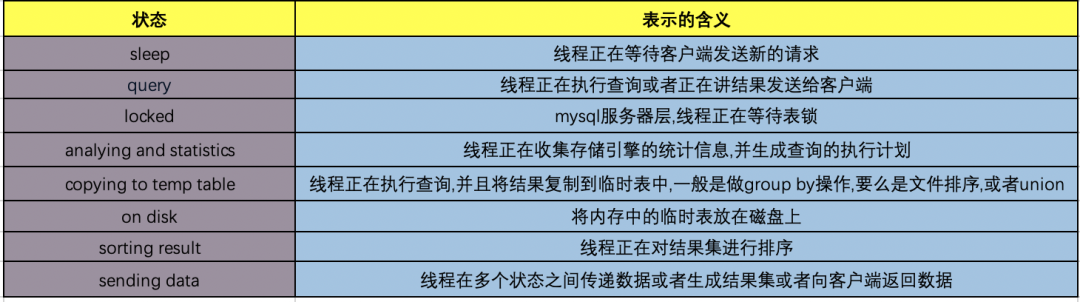
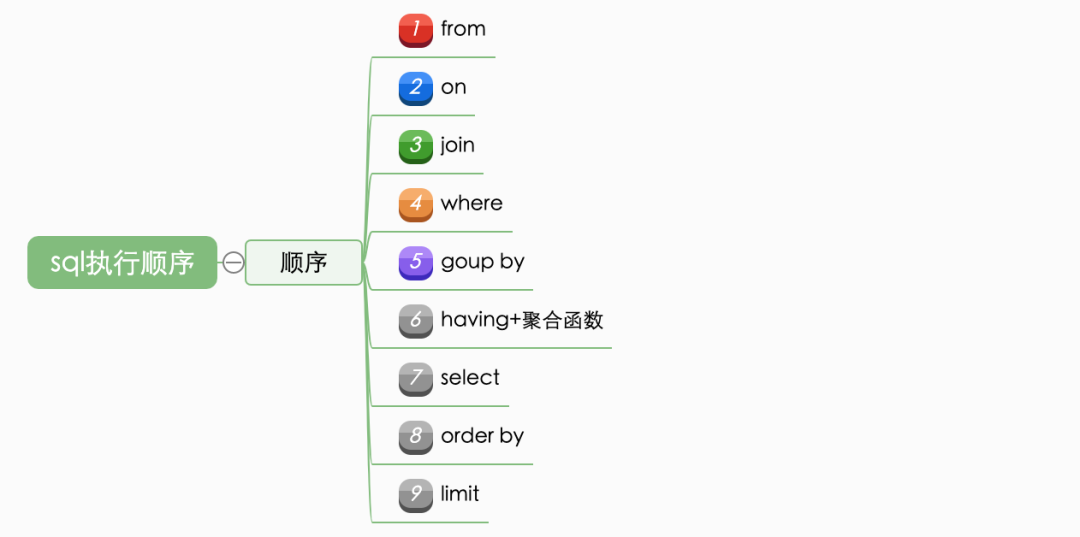
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
量化: 定投基金到底能赚多少钱? | 我用Python对去年800只基金的数据分析
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|
年度爆款文案
点阅读原文,领AI全套资料!


评论