
记一次CMS GC耗时46.6秒的排查过程与解决方法
你知道的越多,不知道的就越多,业余的像一棵小草!
你来,我们一起精进!你不来,我和你的竞争对手一起精进!
编辑:业余草
来源:juejin.cn/post/7257048145233543229
推荐:https://t.zsxq.com/11wE4iuIb
自律才 能自由
「早上7.16分左右」 ,有个服务发生了紧急告警,很多接口超时,出于 「客户的投诉」 和老板的给出的压力,我开始了排查之旅~~~
❝
【排查到最后发现,并不是这些超时的接口都有问题,而是 「其中某一个接口影响了整个服务」,只要是这个服务上的接口,都有可能超时、异常、 等不正常现象】
❞
看下现象
「钉钉群告警:」
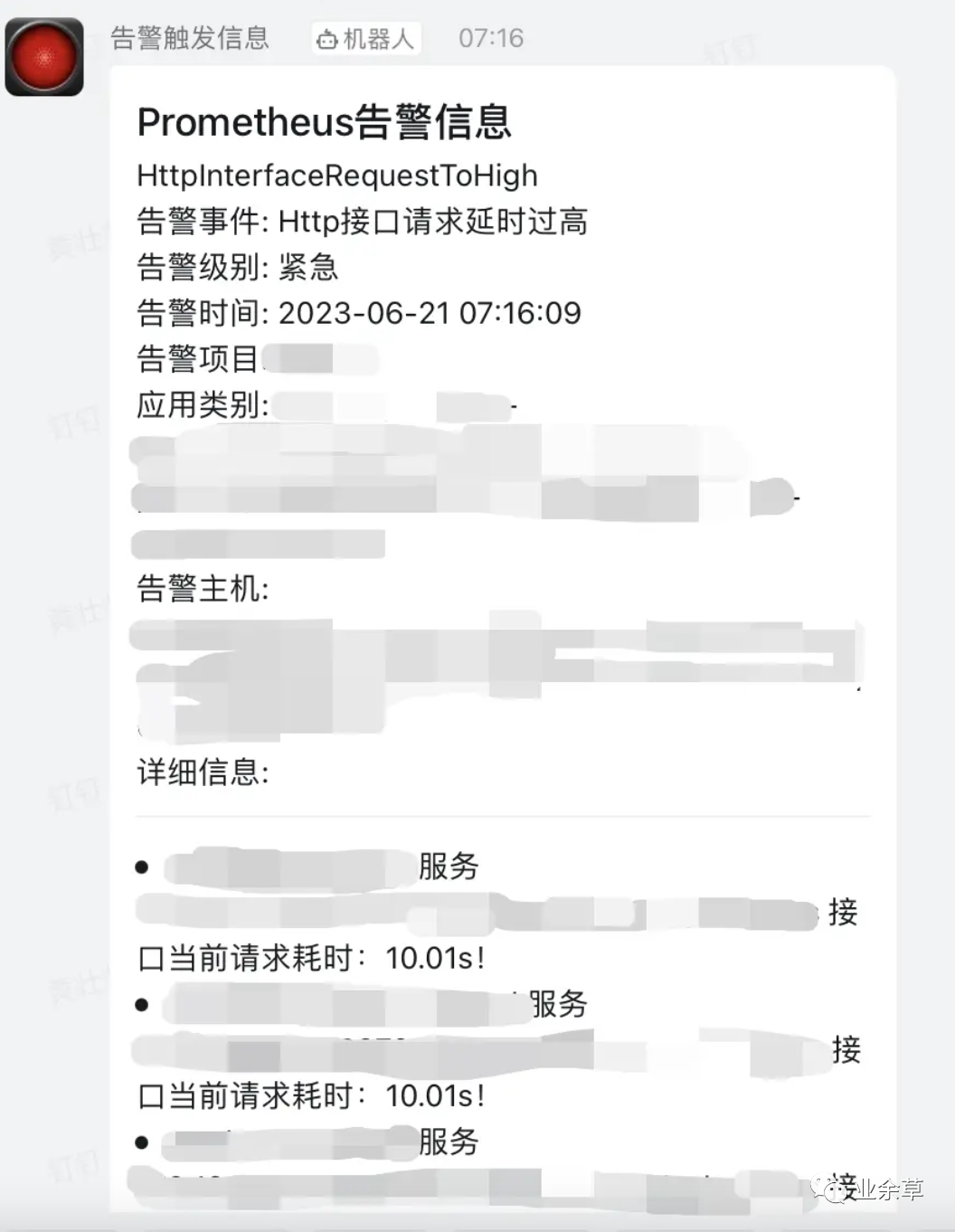 钉钉群告警
钉钉群告警「下图为 告警机器JVM 监控面板:」
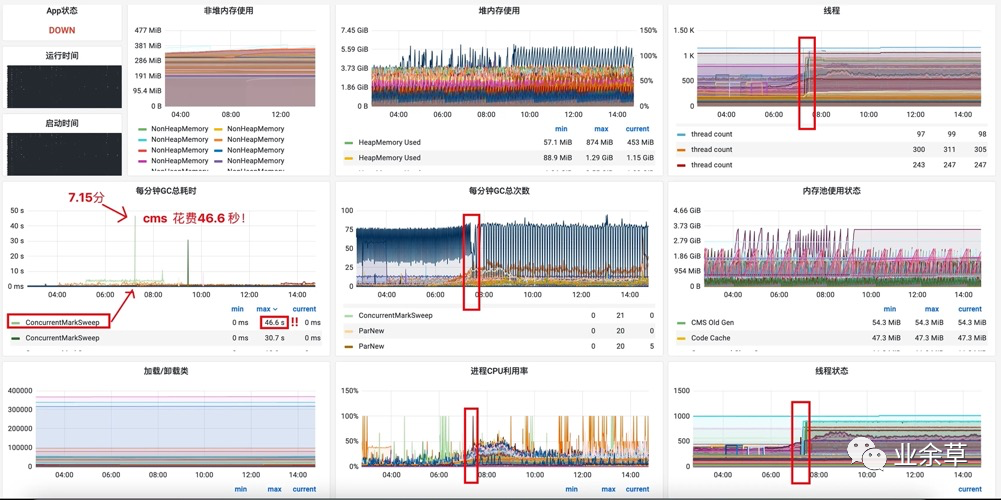 JVM 监控面板
JVM 监控面板观察监控面板看到的现象
「CMS GC单次耗时过长:」
可以看到 CMS GC耗时46.6秒! ,我们知道CMS收集器是作用于老年代的垃圾收集器,他有四个阶段,其中阶段1 (初始标记)和阶段4(重新标记)会发生 「stop-the-world」(即暂停所有应用线程),如果这 46.6 秒正好是这两个阶段中的某一个,那么,相当于整个服务在这46.6秒内,不处理任何的请求,只专注于垃圾回收的工作,整个服务高延迟,低吞吐!我去!那还怎么玩???这种情况下,该服务就算所有接口都超时,也不足为奇呀!
「线程数量:」 线程数量陡增
「线程状态:」 waiting 和 time_waiting的线程陡增
「cpu情况:」 cpu使用率很高
观察后得出结论 & 排查方向
- 一、「得出结论:」 观察上边的监控信息,可以得出结论:
单次 CMS GC 耗时太长!,线程,cpu 都不正常! - 二、「排查方向:」 我的第一直觉就是有地方发生了内存泄露(
因为据我的经验来看, 内存泄露很有可能和 GC 相关联),或者哪个地方分配了大对象。由于线程信息当时没有dump下来(不清楚啥原因没搞下来),并且我猜测根因与 内存泄露 或者 大对象分配 方面更接近,所以我的排查方向「没往」 「线程」 那个方向走,而是 「着重观察堆栈和GC信息」。
❝
光猜没用呀,于是找运维同学要了堆栈信息,之后的排查流程大概是这样 :
❞
dump堆栈文件->使用 MAT 工具分析->仔细观察各项指标 -> 定位问题代码
拿到堆栈文件并使用 MAT 分析
找运维同学拿到堆栈信息文件 以.dump结尾的,如下:
 MAT 分析
MAT 分析「拿到文件后解压,并且后缀 改成 .hprof 否则mat工具不识别,导入不进去。」
说到dump文件其实有很多个工具都可以分析,如下:
- 简易:JConsole、JVisualvm、HA、GCHisto、GCViewer
- 进阶:MAT、JProfiler
由于之前我使用过mat,所以我还是使用mat来排查,先简介下mat:
MAT(Eclipse Memory Analyzer)是一种快速且功能丰富的Java堆分析器,它帮助查找内存泄漏。
使用内存分析 器分析具有数亿个对象的高效堆转储,快速计算对象的保留大小,查看谁在阻止垃圾收集器收集对象,
运行报告以自动提取泄漏嫌疑。 官网地址https://www.eclipse.org/mat,
下载地址为https://www.eclipse.org/mat/downloads.php。我们可以在下载 页面看到:MAT可以独立运行,
也可以通过插件的形式在Eclipse中安装使用,具体的安装过程就不再这里介绍了,我是下载的独立运行 的程序包。
导入:
 导入分析
导入分析导入后,一般都会自动分析,需要一定时间,分析完后如下:
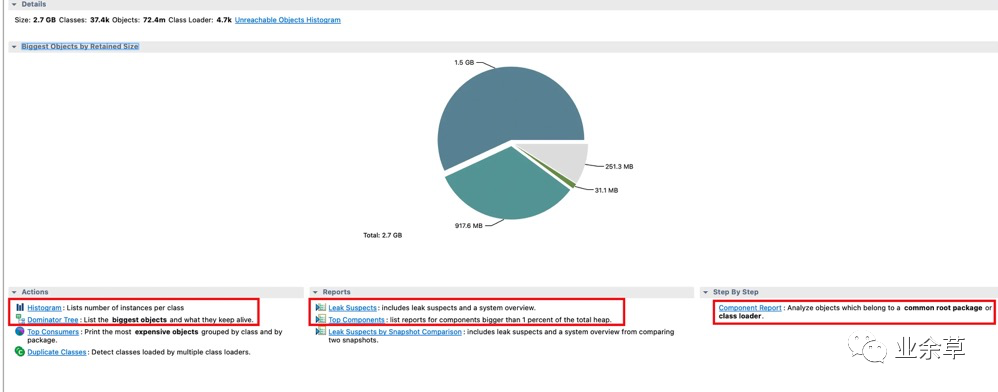 自动分析
自动分析看懂 MAT工具 的分析报告
❝
工欲善其事必先利其器,接下来我们看看这个工具的一些常用操作,以及分析了哪些指标?
❞
「Histogram:」 直方图(里边包含了每个类所对应的对象个数,以及所占用的内存大小)
 分析报告
分析报告「Dominator Tree:」 可以看到哪些对象占用的空间最大以及占比 (常用于寻找大对象)
 Dominator Tree
Dominator Tree「Leak Suspects:」 可疑的内存泄露 分析,饼状图很直观(排查内存泄露利器)。
 Leak Suspects
Leak SuspectsTop components:** 对占用 堆内存 超过 整个堆内存1% 大小的组件做的一系列分析
可以看到他是从多个角度(如:对象,类加载器,包)来分析占比超过1%的组件的。
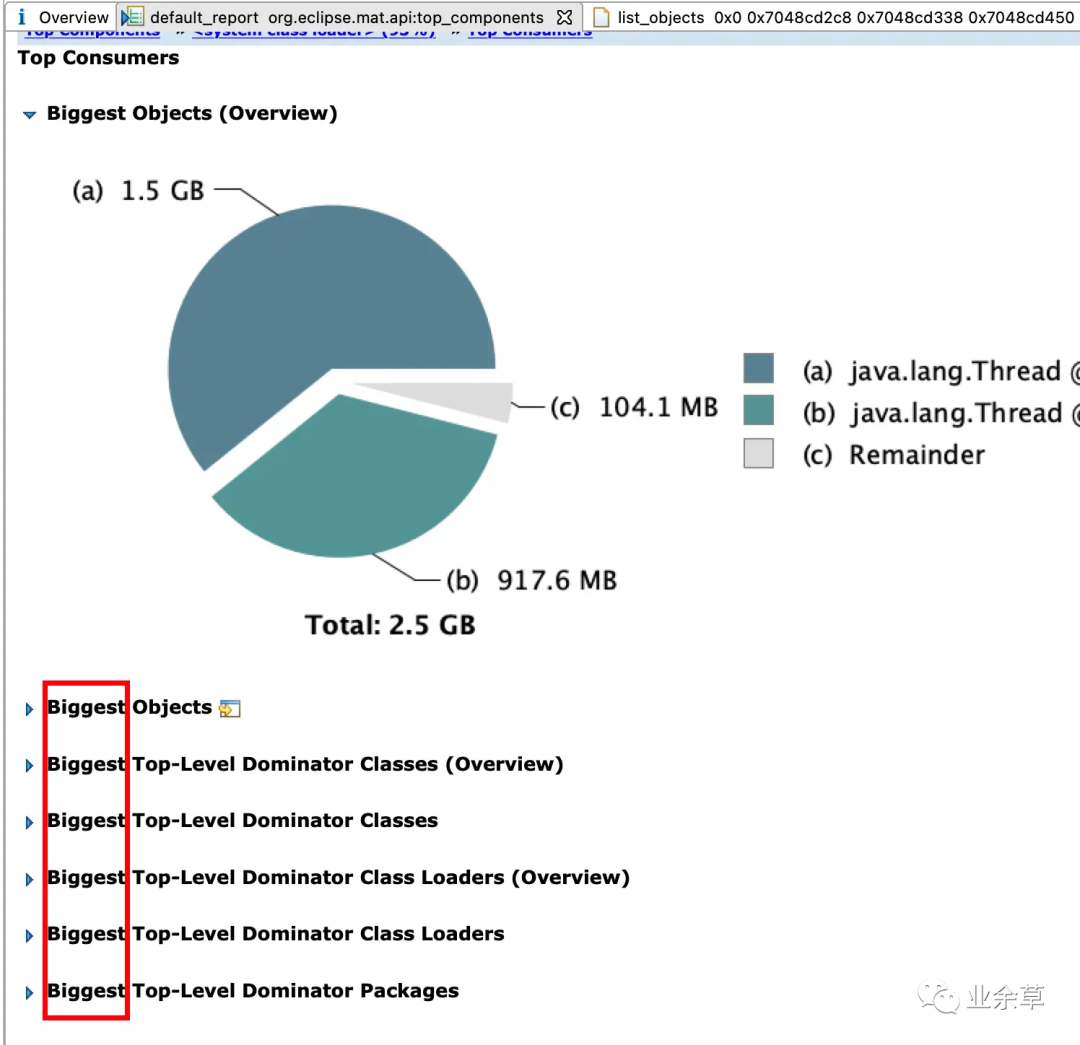 Top components
Top componentsTop consumers:** 列出最昂贵的对象
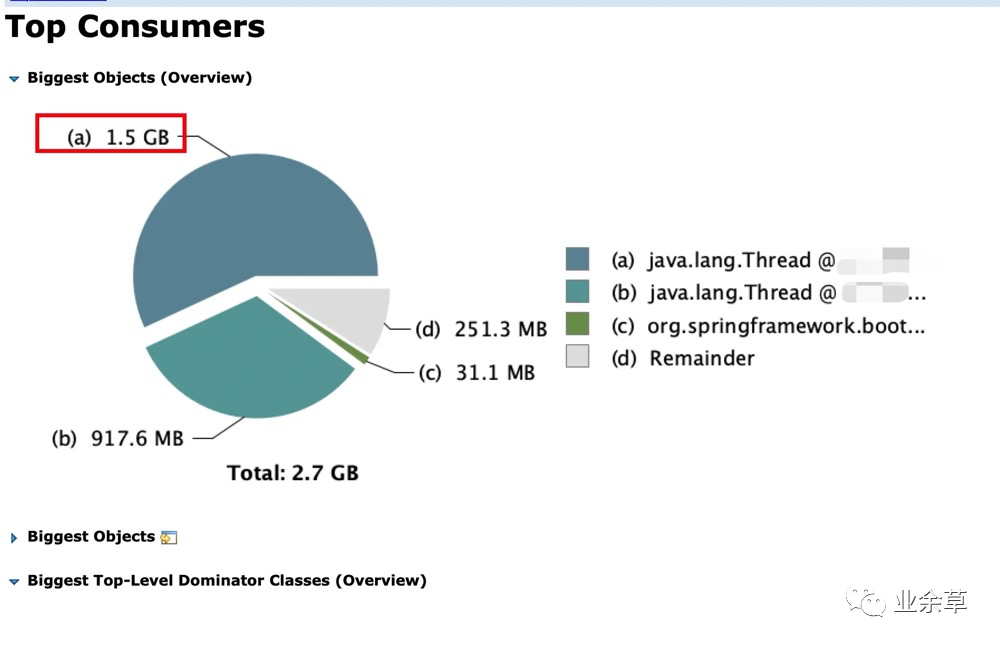 Top consumers
Top consumers可以看到 Top components和Top consumers 差不多,区别似乎不是很大。
「Component Report」 组件的一些报告(分析属于公共根包或类加载器的对象)
「Duplicate Classes」 用来查找重复的类
其中 Component Report 和 Duplicate Classes 我个人认为不常用,不再过多介绍。
在排查分析时候,我认为 「Histogram」 ,「Leak Suspects」,「Dominator Tree」,「Top Consumers」,「Top Components」,这些都得好好观察下,越多观察,答案就会离你越近。
mat观察到的结果
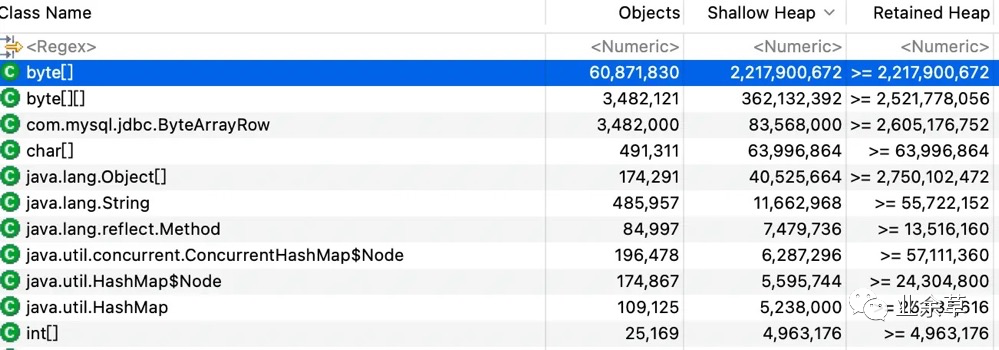
Histogram 结果:
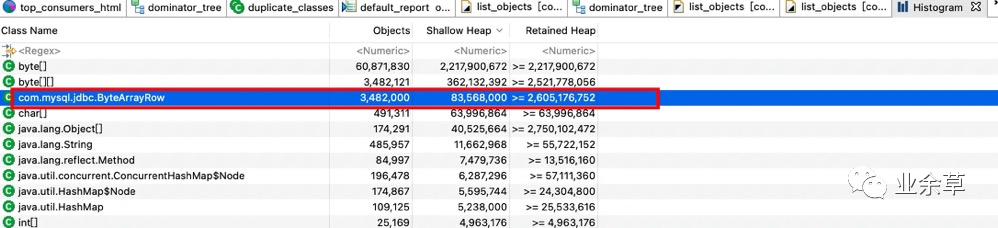 Histogram
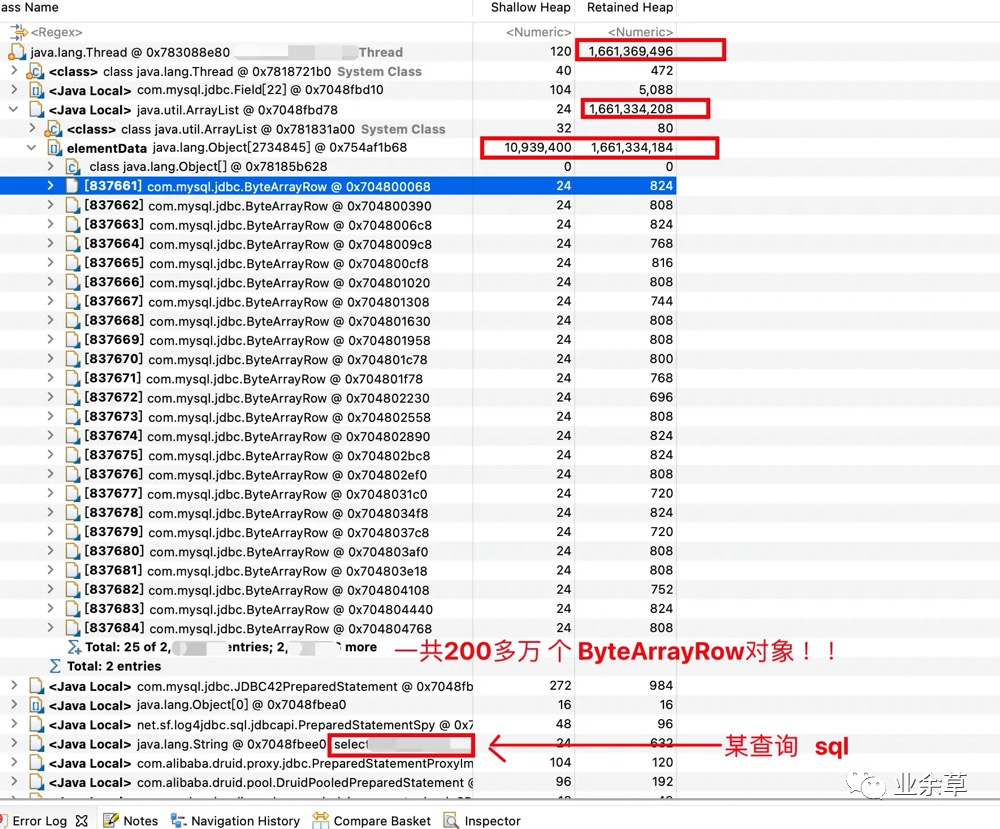
Histogram由于 Histogram 是列出每个类所对应的对象个数,以及所占用的内存大小,所以一般比较基础的类,对象都比较多,这也是正常现象,比如(基本类型数组,以及String, map, list 等各种集合以及 Java中的一些自带的类),但是其中一个值的注意 就是com.mysql,jdbc.ByteArrayRow 这个类很显眼,看起来就是逻辑上的一行数据,这个类的对象这么多,不禁让我起疑了,ok , 下边继续看其他维度的分析结果。
Dominator Tree 结果
可以清楚的看到,其中某个arrayList占到了 整个堆的 56.90% 说明有大对象出现了。(list里边的对象其实就是 com.mysql,jdbc.ByteArrayRow !)
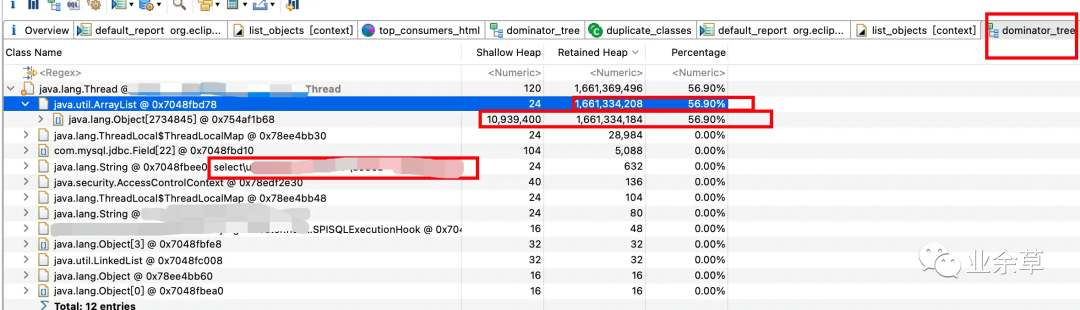 Dominator Tree
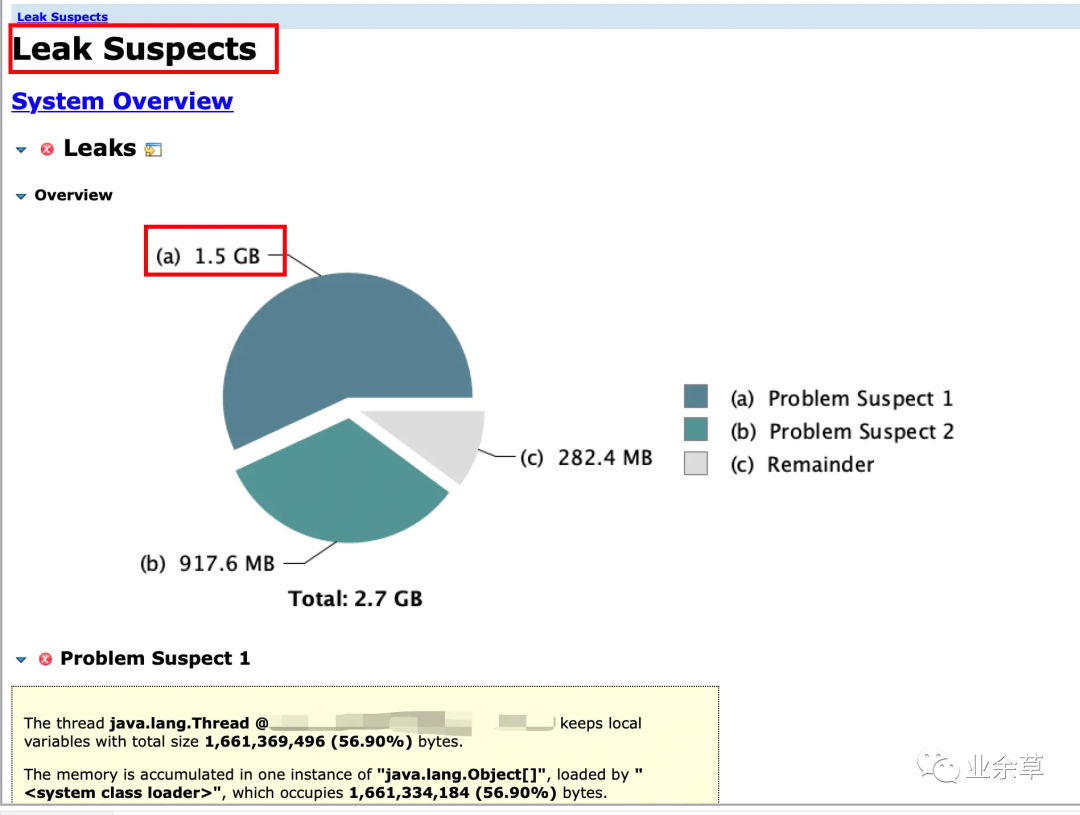
Dominator TreeLeak Suspects 结果
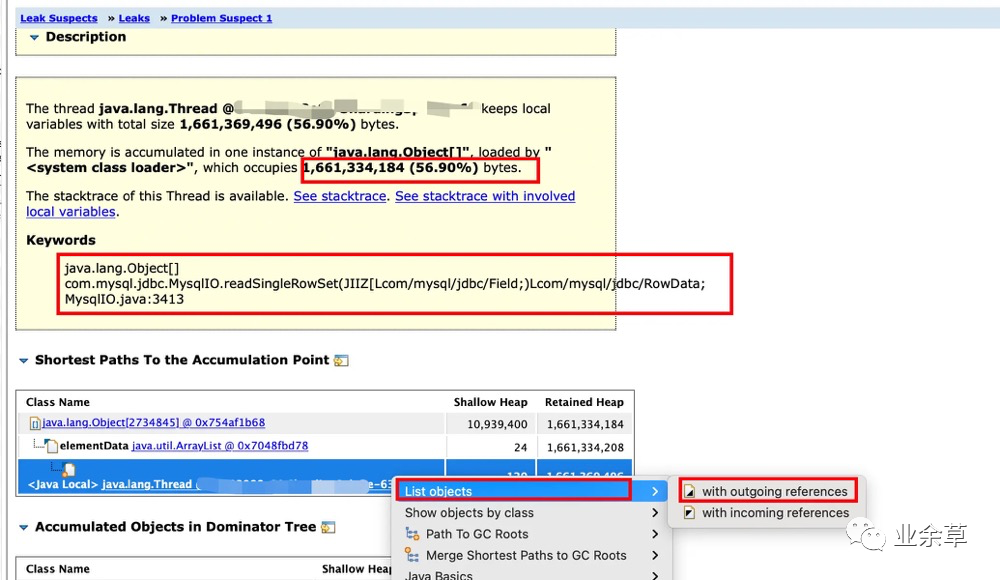 Leak Suspects
Leak Suspects上边截图告诉我们可能存在内存泄露,于是我追踪一下,点击 「outgoing references」 (说明:outgoing references 应该是可以观察到这个线程内,大概都做了哪些事情,或者可以简单粗暴理解为 这个线程都引用了哪些对象) ,结果如下:
 Leak Suspects 结果
Leak Suspects 结果ps: 由于 Top Consumers 和 Top Components 的分析结果与 Dominator Tree 的 「结果很像」 我就不贴出来了。
定位到问题和代码片段
从 Histogram,Dominator Tree,Leak Suspects 三项指标分析得出 「本次问题的原因」:
「某个sql查询出了几百万条数据(几百万个ByteArrayRow对象),导致list集合占到堆内存的56.90%(导致GC出现问题)」
❝
说明:遗憾的是没有拿到GC日志,只能从监控面板和mat工具观察:正向(jvm监控)+反向(mat得出结果),来证实是GC问题,而不能从GC日志直接入手。
❞
代码一览
ok,到这里其实我已经根据mat中的sql:
 代码一览
代码一览找到代码片段了,代码如下:
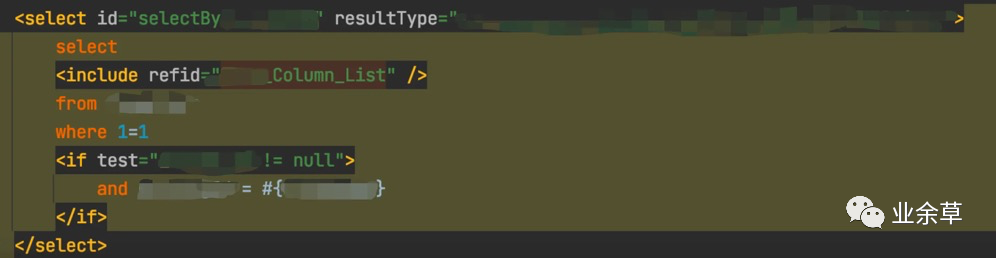
看到这个代码,我思绪万千。。。。。一时不知如何言语。。。。
条件是空,不就是select a,b,c from tableA where 1=1 了?这不就是全表扫描了吗 ,残酷,无情。。。
解决
解决办法 so easy 将 1=1 去掉,并且把 if 判断也去掉,传进来的条件为null时,拿null去匹配,然后结果返回的也是空就完事了(因为该字段是必然不是空的)。
总结
-
首先本次排查过程,借助两大工具,一个就是
jvm监控也即:Prometheus+ grafana通过这俩兄弟的组合,我们可以观察到jvm情况,直观的看出服务是否有异常。 -
第二就是
dump堆栈文件,因为jvm监控面板gc及其不正常,所以顺藤摸瓜找到堆栈信息 (这里谢谢运维同学),并通过mat工具分析,然后找到可疑地方,不得不说此次排查还算比较顺利,直接找到了问题点以及sql语句都找出来了,这样更快速的定位了问题代码。 -
说明:由于本篇文章关注实际排查过程,对cms gc知识未做过多展开。另外本次的小遗憾就是没有拿到 GC 日志,下次出现问题第一时间要GC日志以及堆栈信息和线程文件 「统统都要」 哈哈~ 。
-
「结论(重要):」 虽然没拿到GC日志,但是通过我个人的经验来说,可以基本确定本次告警的原因 即:
❝
间接原因:
由于全表扫描,返回几百万数据(全部缓存在了内存中)
直接原因:
❞由于内存中数据过多,在CMS GC 的Final Remark(重新标记阶段)这个耗时就会很长(我猜测这个重新标记 耗时正好是监控看到的46.6秒,或者比这个值小点),并且这个重新标记阶段是Stop The World,也就是说在一段时间内服务将暂停所有的工作线程,也就导致了服务吞吐下降,大量接口超时的现象了~
千里之行始于足下,其实工作久了就会发现,很多看似很严重的问题,其实最后排查到的问题点,都是一个很基础的东西,或者说一个很简单的东西引起的。就比如这次这个sql的书写 真的是很基础很基础了,但是就是这么基础的东西,一不留心就会全表扫描,小表没事,大表的话返回几百万,甚至几千万几亿的数据,那接口还不超时?服务还不宕机?所以敬畏每一行代码,把每一件小事做好,就是我追求的目标。