
三行代码,轻松实现 Scrapy 对接新兴爬虫神器 Playwright!

前段时间发布了一篇文章介绍一个新兴的类似 Selenium、Pyppeteer 的自动化爬取工具,叫做 Playwright。
那篇文章出来之后,大家纷纷开始试用这个新的神器。
有的朋友试完之后大声叫好:“这个 Playwright 简直太好用了,比 Selenium、Pyppteer 用起来方便,而且功能更为强大。”
也有的朋友说:“Playwright 我之前了解过,现在已经在生产环境稳定运行很久了。”
当然也有朋友说:“这么好用的 Playwright,如果能用在 Scrapy 里面就好了,可惜我没找到一个好用的实现 Scrapy 对接 Playwright 的包。”
Scrapy 对接 Playwright?看来这的确是个需求啊,正好我之前有开发过 Scrapy 和 Selenium、Pyppeteer 的经历,正好这几天休假了,那就干脆直接开发一个 Scrapy 对接 Playwright 的包吧。
昨天下午 2 点动手开发的,6 点左右发布了第一个测试版本。
介绍
下面介绍下这个包的基本用法哈。
这个包的名字叫做 GerapyPlaywright,已经发布到 GitHub(https://github.com/Gerapy/GerapyPlaywright)和 PyPi(https://pypi.org/project/gerapy-playwright/)。
GitHub
PyPi
总而言之,这个包可以非常方便地实现 Scrapy 和 Playwright 的对接,从而实现 Scrapy 里面用 Playwright 爬取 JavaScript 渲染的网页,同时支持多浏览器异步并发爬取。
使用也非常简单,首先安装一下:
pip3 install gerapy-playwright
然后接着在 Scrapy 项目的 settings.py 里面添加对应的 Downloader Middleware 即可:
DOWNLOADER_MIDDLEWARES = {
'gerapy_playwright.downloadermiddlewares.PlaywrightMiddleware': 543,
}
好了,这样就已经大功告成了!
接下来,如果我们想让某个 URL 用 Playwright 爬取,那就只需要将原来的 Request 替换成 PlaywrightRequest 就好了,如下所示:
yield PlaywrightRequest(url, callback=self.parse_detail)
是的,就是这么简单。
这样的话,这个 url 就会用 Playwright 爬取了,得到 Response 就是浏览器渲染后的 HTML 了。
配置
同时这个包当然不仅仅这么简单,还支持很多的配置。
比如想 Playwright 支持 Headless 模式(不弹出浏览器窗口)爬取,可以在 settings.py 里面配置:
GERAPY_PLAYWRIGHT_HEADLESS = True
如果想指定默认的超时时间配置,可以在 settings.py 里面配置:
GERAPY_PLAYWRIGHT_DOWNLOAD_TIMEOUT = 30
这样一个网页如果 30 秒加载不出来网页就会超时。
另外一些网站还增加了 WebDriver 检测,我们可以通过在 Playwright 里面添加真实浏览器伪装配置来隐藏 WebDriver 特性,可以在 settings.py 里面配置:
GERAPY_PLAYWRIGHT_PRETEND = True
如果想支持爬取时设置代理,可以配置全局代理,可以在 settings.py 里面配置:
GERAPY_PLAYWRIGHT_PROXY = 'http://tps254.kdlapi.com:15818'
GERAPY_PLAYWRIGHT_PROXY_CREDENTIAL = {
'username': 'xxx',
'password': 'xxxx'
}
如果想支持页面截图,可以开启全局截图配置,可以在 settings.py 里面配置:
GERAPY_PLAYWRIGHT_SCREENSHOT = {
'type': 'png',
'full_page': True
}
还有很多其他的配置,可以参考 https://github.com/Gerapy/GerapyPlaywright/blob/main/README.md 里的说明。
PlaywrightRequest
当然,上面介绍的配置是项目的全局配置,我们当然也可以使用 PlaywrightRequest 来针对某个请求进行配置,相同含义的配置会覆盖项目 settings.py 指定的配置。
比如说,如果使用 PlaywrightRequest 指定了 timeout 是 30 秒,而在项目 settings.py 里面指定了 timeout 是 10 秒,那就会优先使用 30 秒的配置。
那么 PlaywrightRequest 都支持什么参数呢?
详细配置可以参考 README.md:https://github.com/Gerapy/GerapyPlaywright#playwrightrequest。
下面介绍一下:
url:这就不多说了,就是要爬的 URL。 callback:回调方法,爬取完后的 Response 会作为参数传给 Callback。 wait_until:等待某个加载事件,比如 domcontentloaded 就说明是整个 HTML 文档加载完毕才继续向下执行。 wait_for:可以传一个 Selector,比如等待页面中 .item加载出来才继续向下执行。script:加载完毕之后,执行对应的 JavaScript 脚本。 actions:可以自定义一个 Python 的方法,用来处理 Playwright 的 page 对象。 proxy:设置的代理,可以覆盖全局的代理设置 GERAPY_PLAYWRIGHT_PROXY。 proxy_credential:代理用户名和密码,可以覆盖全局的代理用户名和密码设置 GERAPY_PLAYWRIGHT_PROXY_CREDENTIAL。 sleep:加载完成之后等待的时间,可以用于设置强制等待时间。 timeout:加载超时时间,可以覆盖全局的超时设置 GERAPY_PLAYWRIGHT_DOWNLOAD_TIMEOUT。 pretend:是否隐藏 WebDriver 特征,可以覆盖全局设置 GERAPY_PLAYWRIGHT_PRETEND。
示例
比如这里我有一个网站 https://antispider1.scrape.center,这个网站的内容是必须经过 JavaScript 渲染才显示出来的,同时这个网站检测 WebDriver 特性,正常情况下用 Selenium、Pyppeteer、Playwright 爬取会被 Ban 掉,如图所示:
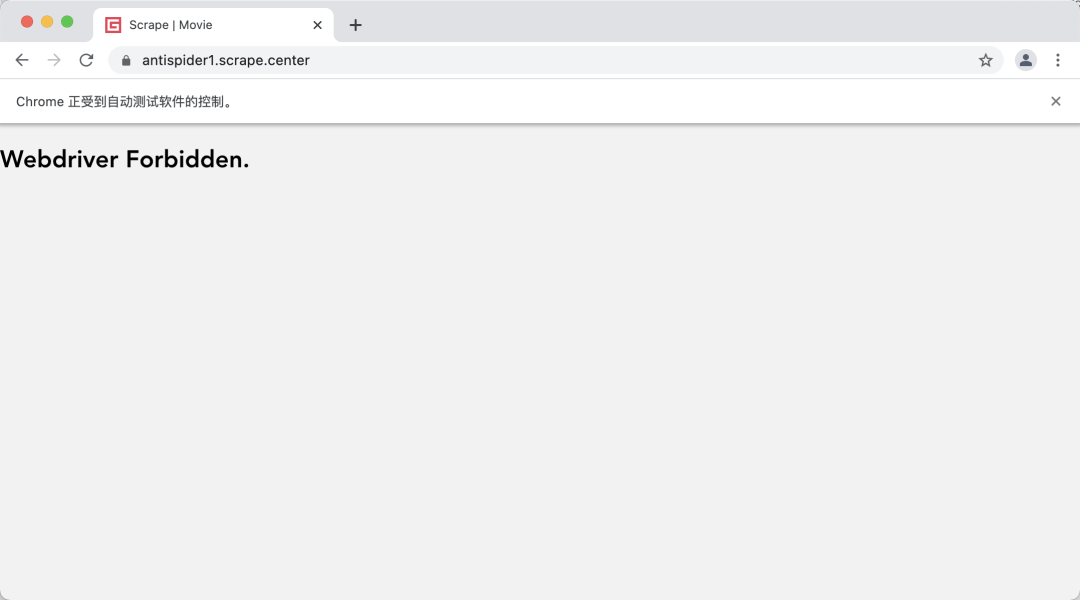
所以,这里我们要用 Scrapy 对该网站进行爬取的话,就可以使用 GerapyPlaywright 了。
新建一个 Scrapy 项目,关键的配置如下:
class MovieSpider(scrapy.Spider):
name = 'movie'
allowed_domains = ['antispider1.scrape.center']
base_url = 'https://antispider1.scrape.center'
max_page = 10
custom_settings = {
'GERAPY_PLAYWRIGHT_PRETEND': True
}
def start_requests(self):
for page in range(1, self.max_page + 1):
url = f'{self.base_url}/page/{page}'
logger.debug('start url %s', url)
yield PlaywrightRequest(url, callback=self.parse_index, priority=10, wait_for='.item')
def parse_index(self, response):
items = response.css('.item')
for item in items:
href = item.css('a::attr(href)').extract_first()
detail_url = response.urljoin(href)
logger.info('detail url %s', detail_url)
yield PlaywrightRequest(detail_url, callback=self.parse_detail, wait_for='.item')
可以看到,这里我们指定了 GERAPY_PLAYWRIGHT_PRETEND 全局配置为 True,这样就可以使 Playwright 启动的时候不会被网站 Ban 掉,同时我们使用了 PlaywrightRequest 指定了每个 URL 都使用 Playwright 加载,同时 wait_for 指定了一个选择器是 .item,这个 .item 就代表了关键提取信息,Playwright 会等待该节点加载出来之后再返回。回调方法 parse_index 方法的 Response 对象就包含对应的 HTML 文本了,对 .item 里面的内容进行提取即可。
另外还可以指定并发数量:
CONCURRENT_REQUESTS = 5
这样就可以同时五个 Playwright 对应的浏览器进行并发爬取了,非常高效。
运行结果类似如下:
2021-12-27 16:54:14 [scrapy.utils.log] INFO: Scrapy 2.2.0 started (bot: example)
2021-12-27 16:54:14 [scrapy.utils.log] INFO: Versions: lxml 4.7.1.0, libxml2 2.9.12, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 21.7.0, Python 3.7.9 (default, Aug 31 2020, 07:22:35) - [Clang 10.0.0 ], pyOpenSSL 21.0.0 (OpenSSL 1.1.1l 24 Aug 2021), cryptography 35.0.0, Platform Darwin-21.1.0-x86_64-i386-64bit
2021-12-27 16:54:14 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.asyncioreactor.AsyncioSelectorReactor
2021-12-27 16:54:14 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'example',
'CONCURRENT_REQUESTS': 1,
'NEWSPIDER_MODULE': 'example.spiders',
'RETRY_HTTP_CODES': [403, 500, 502, 503, 504],
'SPIDER_MODULES': ['example.spiders']}
2021-12-27 16:54:14 [scrapy.extensions.telnet] INFO: Telnet Password: e931b241390ad06a
2021-12-27 16:54:14 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.logstats.LogStats']
2021-12-27 16:54:14 [gerapy.playwright] INFO: playwright libraries already installed
2021-12-27 16:54:14 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'gerapy_playwright.downloadermiddlewares.PlaywrightMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2021-12-27 16:54:14 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2021-12-27 16:54:14 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2021-12-27 16:54:14 [scrapy.core.engine] INFO: Spider opened
2021-12-27 16:54:14 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2021-12-27 16:54:14 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2021-12-27 16:54:14 [example.spiders.movie] DEBUG: start url https://antispider1.scrape.center/page/1
2021-12-27 16:54:14 [gerapy.playwright] DEBUG: processing request
2021-12-27 16:54:14 [gerapy.playwright] DEBUG: playwright_meta {'wait_until': 'domcontentloaded', 'wait_for': '.item', 'script': None, 'actions': None, 'sleep': None, 'proxy': None, 'proxy_credential': None, 'pretend': None, 'timeout': None, 'screenshot': None}
2021-12-27 16:54:14 [gerapy.playwright] DEBUG: set options {'headless': False}
cookies []
2021-12-27 16:54:16 [gerapy.playwright] DEBUG: PRETEND_SCRIPTS is run
2021-12-27 16:54:16 [gerapy.playwright] DEBUG: timeout 10
2021-12-27 16:54:16 [gerapy.playwright] DEBUG: crawling https://antispider1.scrape.center/page/1
2021-12-27 16:54:16 [gerapy.playwright] DEBUG: request https://antispider1.scrape.center/page/1 with options {'url': 'https://antispider1.scrape.center/page/1', 'wait_until': 'domcontentloaded'}
2021-12-27 16:54:18 [gerapy.playwright] DEBUG: waiting for .item
2021-12-27 16:54:18 [gerapy.playwright] DEBUG: sleep for 1s
2021-12-27 16:54:19 [gerapy.playwright] DEBUG: taking screenshot using args {'type': 'png', 'full_page': True}
2021-12-27 16:54:19 [gerapy.playwright] DEBUG: close playwright
2021-12-27 16:54:20 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
2021-12-27 16:54:20 [example.spiders.movie] DEBUG: start url https://antispider1.scrape.center/page/2
2021-12-27 16:54:20 [gerapy.playwright] DEBUG: processing request
2021-12-27 16:54:20 [gerapy.playwright] DEBUG: playwright_meta {'wait_until': 'domcontentloaded', 'wait_for': '.item', 'script': None, 'actions': None, 'sleep': None, 'proxy': None, 'proxy_credential': None, 'pretend': None, 'timeout': None, 'screenshot': None}
2021-12-27 16:54:20 [gerapy.playwright] DEBUG: set options {'headless': False}
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/1
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/2
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/3
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/4
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/5
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/6
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/7
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/8
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/9
2021-12-27 16:54:20 [example.spiders.movie] INFO: detail url https://antispider1.scrape.center/detail/10
cookies []
2021-12-27 16:54:21 [gerapy.playwright] DEBUG: PRETEND_SCRIPTS is run
2021-12-27 16:54:21 [gerapy.playwright] DEBUG: timeout 10
2021-12-27 16:54:21 [gerapy.playwright] DEBUG: crawling https://antispider1.scrape.center/page/2
2021-12-27 16:54:21 [gerapy.playwright] DEBUG: request https://antispider1.scrape.center/page/2 with options {'url': 'https://antispider1.scrape.center/page/2', 'wait_until': 'domcontentloaded'}
2021-12-27 16:54:23 [gerapy.playwright] DEBUG: waiting for .item
2021-12-27 16:54:24 [gerapy.playwright] DEBUG: sleep for 1s
2021-12-27 16:54:25 [gerapy.playwright] DEBUG: taking screenshot using args {'type': 'png', 'full_page': True}
2021-12-27 16:54:25 [gerapy.playwright] DEBUG: close playwright
2021-12-27 16:54:25 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
2021-12-27 16:54:25 [gerapy.playwright] DEBUG: processing request
2021-12-27 16:54:25 [gerapy.playwright] DEBUG: playwright_meta {'wait_until': 'domcontentloaded', 'wait_for': '.item', 'script': None, 'actions': None, 'sleep': None, 'proxy': None, 'proxy_credential': None, 'pretend': None, 'timeout': None, 'screenshot': None}
2021-12-27 16:54:25 [gerapy.playwright] DEBUG: set options {'headless': False}
...
测试代码大家可以参考:https://github.com/Gerapy/GerapyPlaywright/tree/main/example。
好了,以上就是昨天写的这个包的介绍,大家可以试用一下。
5、一个傻瓜式构建可视化 web的 Python 神器 -- streamlit
