
神器!三行 Python 代码轻松提取 PDF 表格数据

来源丨网络
大家好,我是小F~
从 PDF 表格中获取数据是一项痛苦的工作。不久前,一位开发者提供了一个名为 Camelot 的工具,使用三行代码就能从 PDF 文件中提取表格数据。
项目地址:https://github.com/camelot-dev/camelot
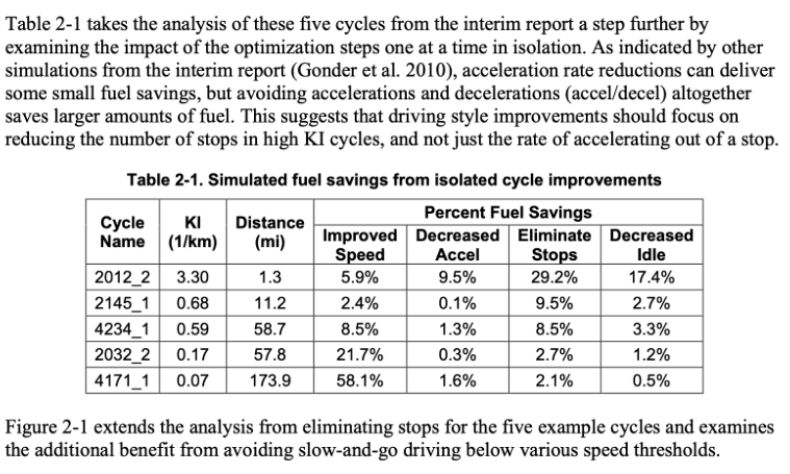
>>> import camelot
>>> tables = camelot.read_pdf('foo.pdf') #类似于Pandas打开CSV文件的形式
>>> tables[0].df # get a pandas DataFrame!
>>> tables.export('foo.csv', f='csv', compress=True) # json, excel, html, sqlite,可指定输出格式
>>> tables[0].to_csv('foo.csv') # to_json, to_excel, to_html, to_sqlite, 导出数据为文件
>>> tables
<TableList n=1>
>>> tables[0]
<Table shape=(7, 7)> # 获得输出的格式
>>> tables[0].parsing_report
{
'accuracy': 99.02,
'whitespace': 12.24,
'order': 1,
'page': 1
}
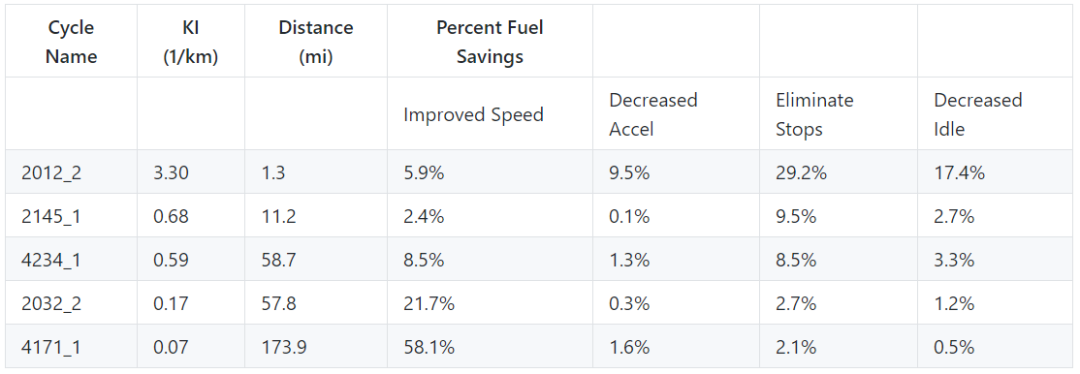
conda install -c conda-forge camelot-py
pip install camelot-py[cv]
git clone https://www.github.com/camelot-dev/camelot
cd camelot
pip install ".[cv]"◆ ◆ ◆ ◆ ◆
麟哥新书已经在当当上架了,我写了本书:《拿下Offer-数据分析师求职面试指南》,目前当当正在举行活动,大家可以用相当于原价5折的预购价格购买,还是非常划算的:
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
评论