
由Facebook发布的非监督学习DINO引发的深入思考

极市导读
本文是作者对FaceBook的论文DINO的一些思考。首先对近期的一些非监督工作进行了回顾,后切入DINO,详细介绍了该工作的原理以及其引发的关于CV的新方向。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

对应的代码链接:https://github.com/facebookresearch/dino
之所以想写这篇论文,是因为题目是:Emerging Properties in Self-Supervised Vision Transformers,一般我看到标题包含transformer的论文不一定会感兴趣,但是看到Self-supervised (unsupervised) + Transformer, 我一定会感兴趣.个人认为,非监督学习将会是未来的一个趋势,尤其是self-supervised这种特定的方式,而途径只有可能是transformer (至少目前来看具有可行性),通过对这个方向的研究,未来才有可能建造出更加impressive的AI系统,甚至是GAI, 这就不是刷刷榜单这么简单了.所以今天就来好好聊聊.
近期一些非监督工作回顾
一如既往地,我的博客产出很少,为了体现质量,我会在每一篇里面穿插很多其他的内容,穿针引线,连点成线,聚线成面,让每一位读者都能有一个全局把握.说道非监督,近期不得不说的几篇工作诸如:
Momentum Contrast for Unsupervised Visual Representation Learning, 2019 (2020收录) Improved Baselines with Momentum Contrastive Learning, 2020 An Empirical Study of Training Self-Supervised Vision Transformers, 2021
熟悉的朋友可能一看就知道,我要说的其实就是Moco系列.这三篇论文其实都是出自何凯明之手.我们先来看看这三篇论文的时间线,第一篇论文发表的背景是当时NLP领域transformer大热,应用于非监督表征学习的任务上产生了BERT, GPT这种非常横扫NLP各个任务的模型.第二篇是对标业内的新的SOTA的SimCLR,最后一篇当然就是今年大热的一个热点:将Transformer用于非监督任务上.关于Transformer一些综述性质的文章可以看我之前写的:
金天:万字长文盘点2021年paper大热的Transformer(ViT)
https://zhuanlan.zhihu.com/p/342512339
(为毛我回过头去看我写文章总感觉写的太浅显了... 贻笑大方之家,后面有机会我会做一些视频给大家详细讲解transformer!)
首先我们来解答这么几个问题:
moco系列解决什么问题? 怎么解决的? 效果怎么样?
相信这也是读者比较关心的问题.再陈述之前,先回到本文的议题:我们是要聊dino, 那么这个玩意和dino怎么联系起来呢?先别急,我们先来回答上面三个问题.
moco实际上就是使用自监督的方式去学习诸如分类这样的任务,然后这种学习到的backbone也可以进一步迁移到检测分割等任务上,实验效果显示它微调之后的效果比监督还好,完美的弥补了监督学习与非监督学习的鸿沟.
mocov1
我们不深入探讨一些实现细节,先贴一个论文里面的伪代码,给大家说一下具体是怎么去做的,细节暂且不做深入讨论:

这个伪代码的做法维护了一个队列,在这个队列里面,存储的是模型输出的键,也就是key,然后我们会有另一组的query, 键和查询这两个变量通过对比loss, 更新队列里面的key, 同时会吐出最早的那个batch的key. 通过这么一些操作使得队列里面的key变得更加的唯一,同时新来了新的样本数据我再更新,直到我的队列里面包含了所有的特征,并且每个特征都不一样,从而实现我的非监督任务.
这么做的一个优势就是队列的长度其实是可控的,这也就意味着,我可以通过增大字典的大小,来提高分类的精准度,进而提升性能.这就好像是用反向传播的方式去做KNN, 你可以通过控制K的大小来控制你的聚类效果.
至于如何使用对比的loss, 如果知道修改momentum一定可以使得这一套可以work,以及对应的公式推导,大家可以仔细的阅读一下原来的那篇论文,论文链接都在引用里面.
mocov2
第二篇其实没啥可以讲的,增加一些trick使得效果更好,那我们就看看增加了什么trick. 简单来说借用了SimCLR里面的一些设计,应用到了Moco的体系内,然后超越了SimCLR,有点借力使力的味道.
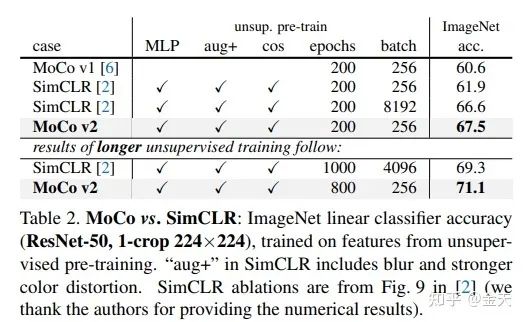
借用的SimCLR的trcik包括:
更大batch; 最后的FC变成了一个MLP (这也行??) 更牛逼的数据增强
好吧,这篇感觉比较水
mocov3
这最近的这篇其实就是将非监督应用于transformer, 或者说把transformer拿过来,堆到了非监督的任务上.那么除此之外有哪些改变没?还是说还是moco那一套?我不看论文我都认为不可能是之前那一套,为什么呢?因为transformer就是天然的队列啊!而token就是你的key! 所以这篇文章出来,其实是很顺理成章的.
论文中花了一些笔墨描述他们使用ViT作为非监督学习的骨干网络的时候遇到的一个问题,随着训练的进行,会变得不稳定.根木原因,他们也不知道,于是就通过控制变量的方法去尝试找寻这个原因,实验发现一些有趣的结论.
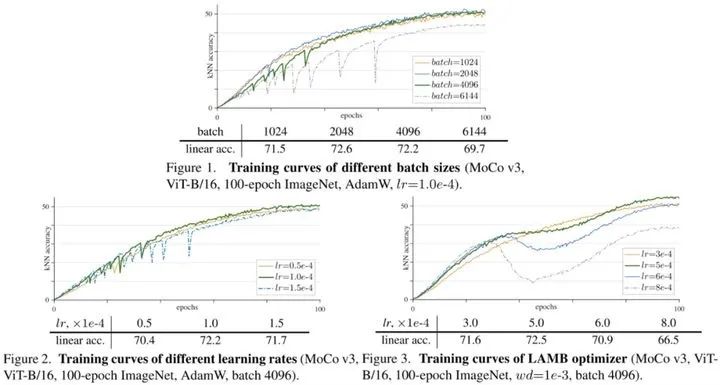
从实验中可以看出随着batch的增大或者lr的增大,kNN accuracy都逐渐出现了dip的情况,并且dip的程度逐渐增加,呈现周期性出现。当使用LAMB optimizer时,随着lr的增加,虽然kNN accuracy还是平滑的曲线,但是中间部分还是会出现衰退.
文中也提到了如何让训练变得更加稳定的一些trick.
we explore freezing the patch projection layer during training. In other words, we use a fixed random patch projection layer to embed the patches, which is not learned. This can be easily done by applying a stop-gradient operation right after this layer.
通过free投影层的patch,换句话说,用固定的随机patch去投影,这部分参数不参与学习,这个实现起来也比较简单,可以参看moco的代码看看里面到底是如何实现的.
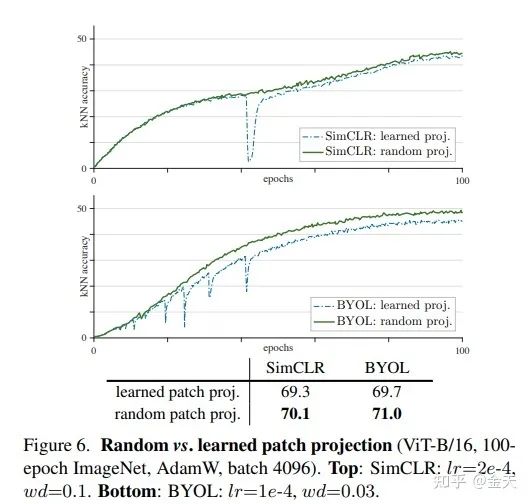
图中可以看到,使用随机投影的方式貌似确实解决了问题.
最后mocov3的效果也是超越了之前所有的非监督架构:
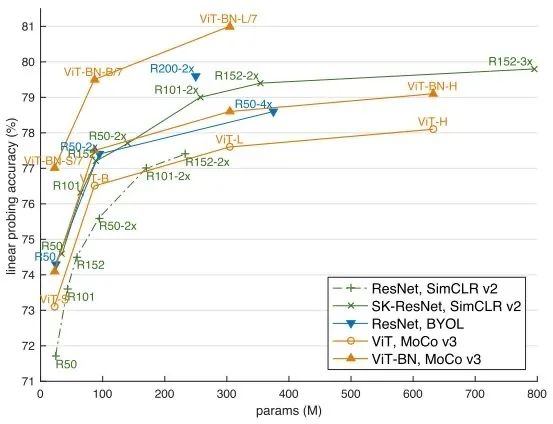
这是moco到目前为止的故事,但这和我要将的DINO其实还是不一东西.因为dino将会解决的问题是:
除了分类,非监督学习+transformer能解决分割问题吗?换句话说,它在没有任何监督信息的基础上知道物体之间的相互关系吗?
DINO可能实现了更加阶层的视觉理解
说句实在的,我自从理解了ViT里面的具体实现,突然对transformer有一种很亲切的感觉,就好像我看到一位少年,乍一看,骨骼清奇,料定它未来一定会生大器,那么现在要做,就是好好投资一下它.事实上,transformer给我的,就是这么一种感觉,而深入理解DINO之后,我仿佛进一步的发现transformer的潜能,所以就多写点东西与大家分享.
这些年来,不管是CNN的大力发展也好,还是transformer的大力发展,大家其实都是在已有的监督任务上,告诉模型去建模他们看到的数据.这其实非常依赖于你对于数据的定义,这一点和NLP就很不一样,比如我们词嵌入,我不告诉模型任务信息,它就可以知道"刘德华"是一个人名,甚至可以告诉你其他跟这个名词有关系的名词.这是很早以前的效果,现在OpenAI可以告诉你,他们做的模型不仅可以理解词,还可以告诉你每个词之间的相互关系,甚至可以把你的自然语言的数据库检索问题写成SQL语句.这难道不牛逼吗?更有甚者,把GPT3的模型对接到图像领域,实现了DALL-E. 告诉它 绿色的钟表, 它就可以生成绿色的钟表.显然它学习到了更高阶的特征.
那么Computer Vision有没有可能做到这一点呢?
今天要讲的这个dino, 其实就做到了.请理解两个事情,实现分割和非监督的实现分割是两个概念. 当然也有一些其他的方法实现了非监督的语义分割,这其实也不难,但结合transformer来做的,应该DINO是第一个.

这是DINO的效果.
需要注意的是,这个是AttentionMap, dino并没有任何语义的ground truth, 也没有任何类别告诉它这是一只猴子,但是它可以把所有注意力学到在这上面.
我这么说,你可能会觉得:就这?兄弟,你可别太天真了,这是game changer!! 这等于是丢给你一张图片,没有任何GT, 它就可以自动帮你把这些attention学出来!再仔细想一下,这是不是和NLP里面的embedding 很像?再想一下,我们现在最不缺的是什么?最不缺的是原始数据,每天互联网产生这么多图片,视频,如果这个transformer这么牛逼,全部丢进去,你觉得会产出一个什么样的AI? 一个超大版本的resnet101???
NO, no, no. 远没有这么简单.这就是为什么我看好这个方向的原因,也是我写这篇paper解析的原因.当然我们目前还不能完全做unsupervisor, 但是self-supervisor已经够用了!
就准备着Google AI或者FAIR放出更大的招吧,这将可能会使得游戏规则发生改变.
这个还能做些什么?使用Self-supervisor的方法,DINO学出来的模型,可以直接做分类,简单来说,你丢给他你要分类的图片,它可以自动挖掘出每幅图片不同的特征,并自动给你归类,想要几类有几类,这才是未来的AI.
要放到以前,我可能会觉得这种论断有点哗众取宠,但是DINO所展现出来的,不仅仅是分类的效果,还有网络学出来的非常清晰的热力图,注意力图,这些都足以证明,DINO所能做的,不仅仅是分类,包括分割,检测,未来的CV众多的task都未来可期,采用非监督的方式.
下面是DINO系统的一个简单原理.
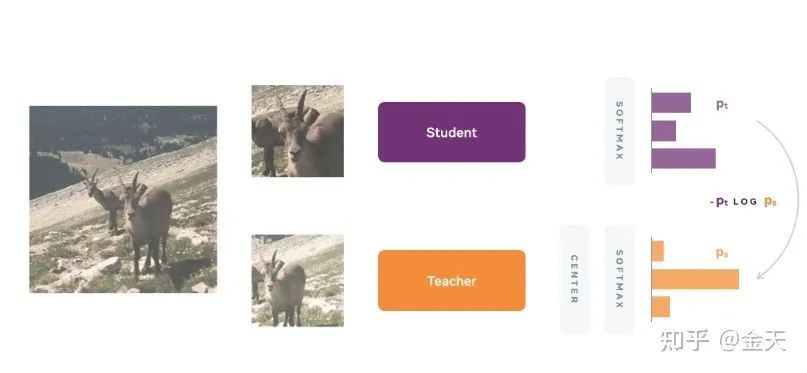
DINO的原理其实也很简单,由于它是非监督的学习,因此它在学习的时候是不需要label的,为了达到这个非监督的目的,就需要
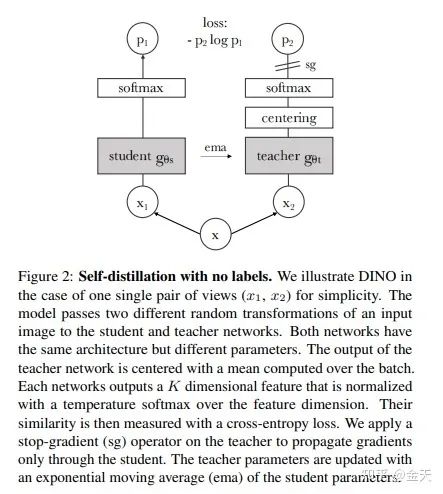
基础来说,一个学习网络,和一个教学网络.输入实际上是同一张图片,但是经过不同的transformation, 二者的网络结构一致,不一样的只是参数.teacher网络的梯度会传给学生网络.teacher网络的参数会随着学生网络的参数更新而更新.
我们来看一下DINO网络的流程图:

这个流程图可以说简单易懂,老少皆宜了.就和我上面说的步骤和那张流程图差不多.
我们来看一下DINO的效果到底咋样:
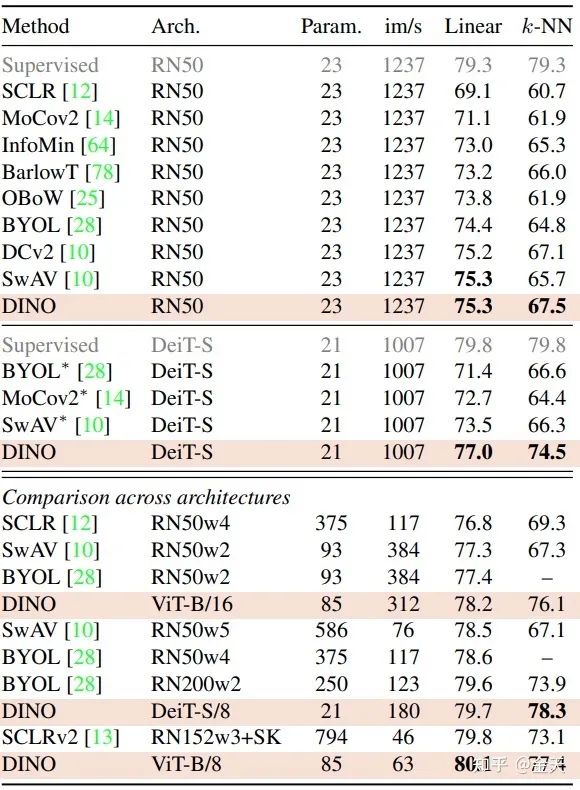
单看Linear这一列,是所有的方法的对比,在固定类别输出下.可以看到DINO的方法,精度是最高的,在使用DeiT的架构基础之下,精度是远远地超过了RN50, 也就是传统的CNN.
再去看k-NN这个非监督的这一行,虽然比不上固定类别,但是相差也不大,尤其是使用transformer架构的时候,误差更小.
总结
DINO实际上是一个摸着石头过河的文章,里面做了很多详尽的ablation study, 我就不一一阐述,感兴趣的同学可以仔细看看论文.毫无疑问,DINO引领大家来到了一个新的领域,这一领域将开创Unsupervise和Transformer新的结合.如同我之前的判断,transformer训练所需要的海量数据,仅从监督上去学习是不够的,而非监督的学习如果能够让transformer工作的很快,那么未来毫无疑问,这将是CV的一个新的篇章.
Reference
Momentum Contrast for Unsupervised Visual Representation Learning(https://arxiv.org/pdf/1911.05722.pdf) Improved Baselines with Momentum Contrastive Learning(https://arxiv.org/pdf/2003.04297.pdf) An Empirical Study of Training Self-Supervised Vision Transformers(https://arxiv.org/pdf/2104.02057.pdf) 陀飞轮-Moco三部曲(https://zhuanlan.zhihu.com/p/365886585) [Emerging Properties in Self-Supervised Vision Transformers]
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
