
代理IP、增量爬虫、分布式爬虫的必备利器 - redis

来源 | 麦叔编程
如果你真正写过爬虫,你一定遇到过这些问题:
爬取数据的时候IP被封或者被限制 网页数据库时时刻刻都在更新,不可能每次爬取都爬整站,需要做增量爬取 数据量巨大,即使用了scrapy等多线程框架也是杯水车薪
要解决这三种场景,都需要使用某种数据库,而redis是其中最合适的一种。
本文通过几个案例,学习用redis数据库解决以上问题:
使用基于redis的代理池,防止被封号 使用redis管理爬取状态,实现增量式爬虫 使用redis做分布式爬虫实现巨量数据爬取,著名的分布式爬虫方案scapy-redis也是类似原理

redis可以存储爬取的数据
当爬虫工程师想构建一个ip代理池的时候,redis绝对是首选。
下面我们来看一段代码:
import redis
import requests
from lxml import etree
conn = redis.Redis(host='127.0.0.1', port=6379)
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47"}
def get_https_proxy(num):
https_proxy_url = f"http://www.nimadaili.com/https/{num}/"
resp = requests.get(url=https_proxy_url, headers=headers).text
# 使用xpath提取代理ip的字段
tree = etree.HTML(resp)
https_ip_list = tree.xpath('/html/body/div/div[1]/div/table//tr/td[1]/text()')
# 将爬下来的代理ip以列表(键名为'https')元素的形式推入数据库
[conn.lpush('https',ip) for ip in https_ip_list]
print('Redis数据库有HTTPS代理IP数量为:',conn.llen('https'))
# 获取代理网站1——6页的代理ip
for n in range(1,6):
get_https_proxy(n)
在redis命令交互端输入:
lrange https 0 -1
就可以看到爬到的代理ip: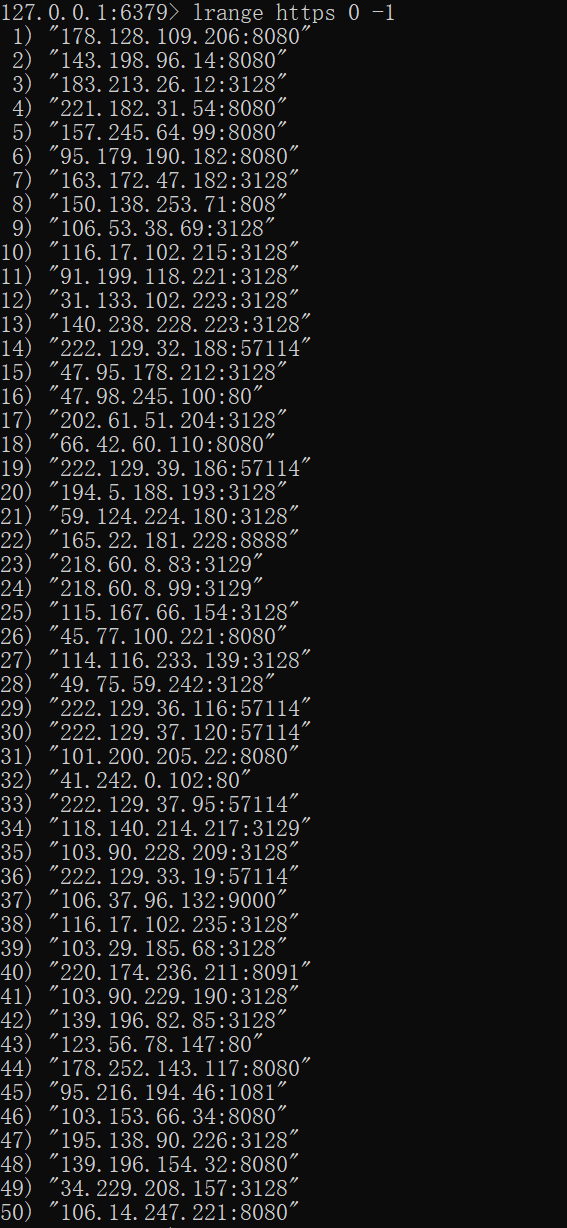
取出代理ip也非常简单:
import redis
conn = redis.Redis(host='127.0.0.1', port=6379)
proxies_ip = conn.rpop('https').decode('utf-8')
print(proxies_ip)
>> 106.14.247.221:8080
是不是非常简单,学会这招,再也不怕被封IP了。
redis可以辅助实现增量爬虫
当爬虫工程师需要写增量式爬虫的时候,一定会考虑使用redis的set数据类型进行url“去重”,为什么呢?
现在假如有一个需求:
1. 爬取菜市场的历史菜价。
2. 需要每天更新当日的价格。
那么我的爬取思路就是:
1. 爬取每日菜价详情页的url,以set类型存入redis数据库。
2. 爬取redis数据库中所有的url对应菜价数据。
3. 然后第二天或者(第N天),再次爬取每日的菜价详情页的url,以set类型存入redis数据库。如果在存入数据库的时候返回0,则表示数据库中已存在相同的url,则不需要爬取该详情页,如果返回1,则表示数据库中未存在该url,则需要爬取该详情页。

上面看得有点绕,我们来实际操作下:
127.0.0.1:6379> sadd url wwww.baidu.com
(integer) 1
127.0.0.1:6379> sadd url wwww.baidu.com
(integer) 0
将www.baidu.com作为url的成员第一次存入数据库的时候,返回的是(integer) 1;然后我们第二次进行相同的操作时,数据库返回的是(integer) 0,这表示url成员中已经存在了该值。
利用redis这个特性,我们可以很便利地做到url去重的功能。
# 这是我写的某个爬虫项目的运行爬虫的实例方法
def run_spider(self):
# 遍历爬取所有详情页的url
for url in self.get_link_list():
# 将url以set类型存入redis数据库
j = self.conn.sadd('url',url)
# 判断返回值是1或0
if j == 1:
# 如果返回值为1,爬取该详情页数据,反之跳过
self.parse_detail(url)
# 数据持久化存储
self.work_book.save('./price.xls')
redis可以用作分布式爬虫的调度器
鼎鼎大名的分布式爬虫框架:scrapy-redis一定有听说过吧?
分布式爬虫一听感觉很高大上,其实原理很简单,就是把scrapy的调度器共享到服务器上去,然后各个设备的爬虫从服务器上获取需要爬取数据的url。
我们来温习下scrapy五大组件之一的调度器的作用:
调度器(Scheduler):用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址。
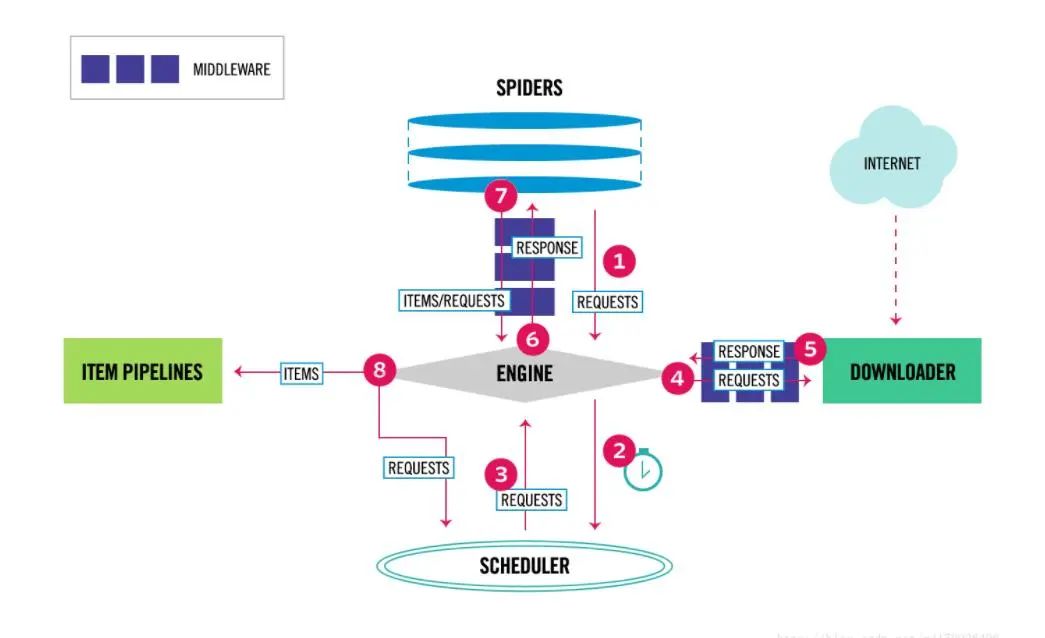
下面我们分三步模拟部署一个简单的分布式爬虫:
1. 第一步,爬取需要解析数据的url;
import redis
import requests
from lxml import etree
conn = redis.Redis(host='127.0.0.1', port=6379)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36',
}
# 获取一部小说所有的章节的url,并以list数据形式存入redis。
def get_catalogue():
response = requests.get('https://www.tsxs.org/16/16814/', headers=headers)
tree = etree.HTML(response.text)
catalog_url_list = tree.xpath('//*[@id="chapterlist"]/li/a/@href')
return catalog_url_list
for i in get_catalogue():
full_link = 'https://www.tsxs.org' + i
conn.lpush('catalogue',full_link)
这段代码实现了向redis注入所有需要爬取小说页面的url的功能。
127.0.0.1:6379> lrange catalogue 0 -1
1) "https://www.tsxs.org/16/16814/13348772.html"
2) "https://www.tsxs.org/16/16814/13348771.html"
3) "https://www.tsxs.org/16/16814/13348770.html"
4) "https://www.tsxs.org/16/16814/13348769.html"
5) "https://www.tsxs.org/16/16814/13348768.html"
6) "https://www.tsxs.org/16/16814/13348767.html"
7) "https://www.tsxs.org/16/16814/13348766.html"
8) "https://www.tsxs.org/16/16814/13348765.html"
9) "https://www.tsxs.org/16/16814/13348764.html"
10) "https://www.tsxs.org/16/16814/13348763.html"
11) "https://www.tsxs.org/16/16814/13348762.html"
12) "https://www.tsxs.org/16/16814/13348761.html"
13) "https://www.tsxs.org/16/16814/13348760.html"
14) "https://www.tsxs.org/16/16814/13348759.html"
15) "https://www.tsxs.org/16/16814/13348758.html"
16) "https://www.tsxs.org/16/16814/13348757.html"
17) "https://www.tsxs.org/16/16814/13348756.html"
18) "https://www.tsxs.org/16/16814/13348755.html"
19) "https://www.tsxs.org/16/16814/13348754.html"
20) "https://www.tsxs.org/16/16814/13348753.html"
21) "https://www.tsxs.org/16/16814/13348752.html"
22) "https://www.tsxs.org/16/16814/13348751.html"
23) "https://www.tsxs.org/16/16814/13348750.html"
24) "https://www.tsxs.org/16/16814/13348749.html"
25) "https://www.tsxs.org/16/16814/13348748.html"
26) "https://www.tsxs.org/16/16814/13348747.html"
27) "https://www.tsxs.org/16/16814/13348746.html"
28) "https://www.tsxs.org/16/16814/13348745.html"
29) "https://www.tsxs.org/16/16814/13348744.html"
30) "https://www.tsxs.org/16/16814/13348743.html"
31) "https://www.tsxs.org/16/16814/13348742.html"
32) "https://www.tsxs.org/16/16814/13348741.html"
33) "https://www.tsxs.org/16/16814/13348740.html"
34) "https://www.tsxs.org/16/16814/13348739.html"
35) "https://www.tsxs.org/16/16814/13348738.html"
36) "https://www.tsxs.org/16/16814/13348737.html"
37) "https://www.tsxs.org/16/16814/13348736.html"
38) "https://www.tsxs.org/16/16814/13348735.html"
39) "https://www.tsxs.org/16/16814/13348734.html"
40) "https://www.tsxs.org/16/16814/13348733.html"
41) "https://www.tsxs.org/16/16814/13348732.html"
42) "https://www.tsxs.org/16/16814/13348731.html"
43) "https://www.tsxs.org/16/16814/13348730.html"
44) "https://www.tsxs.org/16/16814/13348729.html"
45) "https://www.tsxs.org/16/16814/13348728.html"
46) "https://www.tsxs.org/16/16814/13348727.html"
47) "https://www.tsxs.org/16/16814/13348726.html"
48) "https://www.tsxs.org/16/16814/13348725.html"
49) "https://www.tsxs.org/16/16814/13348724.html"
50) "https://www.tsxs.org/16/16814/13348723.html"
51) "https://www.tsxs.org/16/16814/13348722.html"
52) "https://www.tsxs.org/16/16814/13348721.html"
53) "https://www.tsxs.org/16/16814/13348720.html"
54) "https://www.tsxs.org/16/16814/13348719.html"
55) "https://www.tsxs.org/16/16814/13348718.html"
56) "https://www.tsxs.org/16/16814/13348717.html"
57) "https://www.tsxs.org/16/16814/13348716.html"
58) "https://www.tsxs.org/16/16814/13348715.html"
59) "https://www.tsxs.org/16/16814/13348714.html"
60) "https://www.tsxs.org/16/16814/13348713.html"
61) "https://www.tsxs.org/16/16814/13348712.html"
62) "https://www.tsxs.org/16/16814/13348711.html"
63) "https://www.tsxs.org/16/16814/13348710.html"
64) "https://www.tsxs.org/16/16814/13348709.html"
65) "https://www.tsxs.org/16/16814/13348708.html"
66) "https://www.tsxs.org/16/16814/13348707.html"
67) "https://www.tsxs.org/16/16814/13348706.html"
68) "https://www.tsxs.org/16/16814/13348705.html"
69) "https://www.tsxs.org/16/16814/13348704.html"
70) "https://www.tsxs.org/16/16814/13348703.html"
71) "https://www.tsxs.org/16/16814/13348702.html"
72) "https://www.tsxs.org/16/16814/13348701.html"
73) "https://www.tsxs.org/16/16814/13348700.html"
74) "https://www.tsxs.org/16/16814/13348699.html"
75) "https://www.tsxs.org/16/16814/13348698.html"
76) "https://www.tsxs.org/16/16814/13348697.html"
77) "https://www.tsxs.org/16/16814/13348696.html"
78) "https://www.tsxs.org/16/16814/13348695.html"
79) "https://www.tsxs.org/16/16814/13348694.html"
80) "https://www.tsxs.org/16/16814/13348693.html"
81) "https://www.tsxs.org/16/16814/13348692.html"
82) "https://www.tsxs.org/16/16814/13348691.html"
83) "https://www.tsxs.org/16/16814/13348690.html"
84) "https://www.tsxs.org/16/16814/13348689.html"
85) "https://www.tsxs.org/16/16814/13348688.html"
86) "https://www.tsxs.org/16/16814/13348687.html"
87) "https://www.tsxs.org/16/16814/13348686.html"
88) "https://www.tsxs.org/16/16814/13348685.html"
89) "https://www.tsxs.org/16/16814/13348684.html"
90) "https://www.tsxs.org/16/16814/13348683.html"
91) "https://www.tsxs.org/16/16814/13348682.html"
92) "https://www.tsxs.org/16/16814/13348681.html"
93) "https://www.tsxs.org/16/16814/13348680.html"
94) "https://www.tsxs.org/16/16814/13348679.html"
95) "https://www.tsxs.org/16/16814/13348678.html"
96) "https://www.tsxs.org/16/16814/13348677.html"
97) "https://www.tsxs.org/16/16814/13348676.html"
98) "https://www.tsxs.org/16/16814/13348675.html"
99) "https://www.tsxs.org/16/16814/13348674.html"
100) "https://www.tsxs.org/16/16814/13348673.html"
101) "https://www.tsxs.org/16/16814/13348672.html"
102) "https://www.tsxs.org/16/16814/13348671.html"
103) "https://www.tsxs.org/16/16814/13348670.html"
104) "https://www.tsxs.org/16/16814/13348669.html"
105) "https://www.tsxs.org/16/16814/13348668.html"
2. 第二步,配置redis的配置文件
linux或者mac:redis.conf windows:redis.windows.conf 代开配置文件修改: 将bind 127.0.0.1进行删除 关闭保护模式:protected-mode yes改为no 结合着配置文件开启redis服务 redis-server 配置文件 启动客户端: redis-cli 
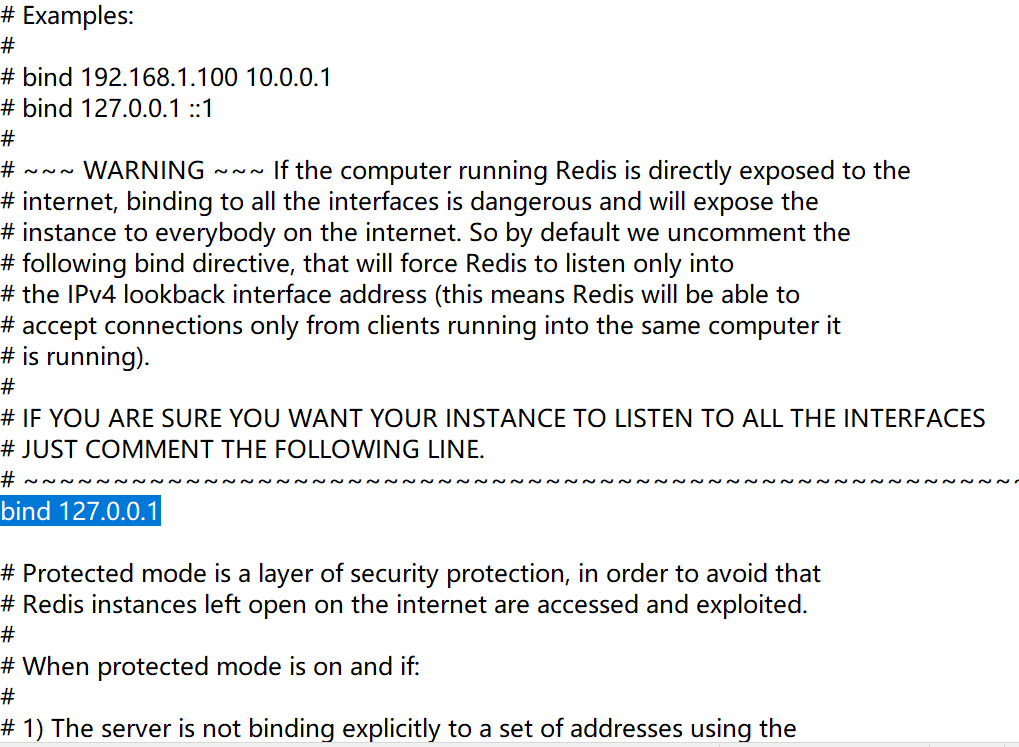

3. 第三步,使用局域网内别的设备访问redis服务;
开始爬取,
使用redis的lpop命令,执行后从数据库返回url,数据库中则清除该url。
import redis
import requests
from lxml import etree
conn = redis.Redis(host='192.168.125.101', port=6379)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36',
}
def extract_data(per_link):
response = requests.get(url=per_link, headers=headers).content
tree = etree.HTML(response.decode('gbk'))
title = tree.xpath('//*[@id="mains"]/div[1]/h1/text()')[0]
content = tree.xpath('//*[@id="book_text"]//text()')[0]
return title, content
def save_to_pc(title, content):
print(title + "开始下载!")
with open(title+'.txt','w',encoding='utf-8')as f:
f.write(content)
print(title + "下载结束!")
def run_spider():
print('开始运行爬虫!')
link = conn.lpop('catalogue').decode('utf-8')
title, content = extract_data(link)
save_to_pc(title, content)
print('下载结束!')
run_spider()
>> 开始运行爬虫!
章节目录 第105章 同样是君子开始下载!
章节目录 第105章 同样是君子下载结束!
下载结束!
就这样爬取一个url,redis中少一个url,直到被全部爬取完毕为止。