
利用Selenium批量下载100首网易云热歌榜音乐
今天的小demo我们使用的是selenium和xpath.函数式编程采集数据.采集到的数据如图所示。

01
需求数据
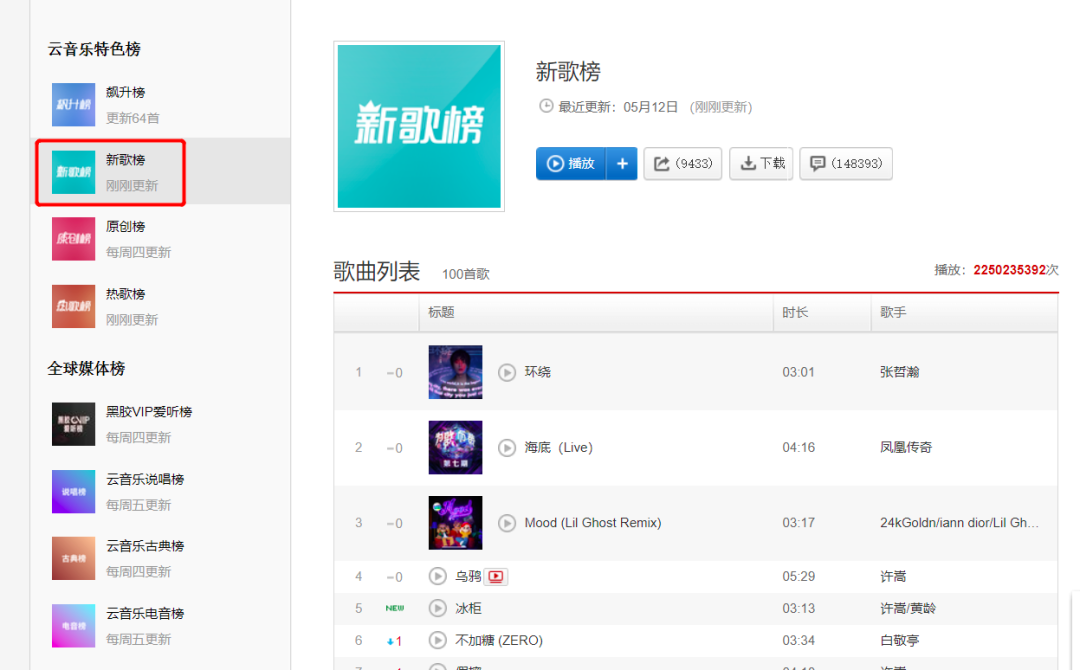
02
页面分析
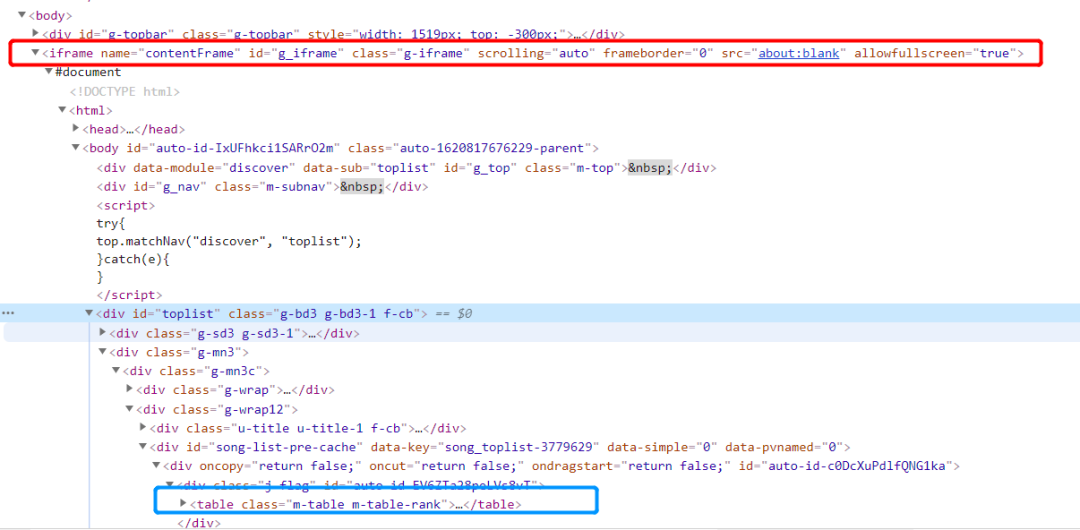
url = "https://music.163.com/#/discover/toplist?id=3779629" # 新歌榜
driver = webdriver.Chrome()
driver.get(url)
time.sleep(3)
_iframe = driver.find_element_by_id('g_iframe') # 找到iframe标签
driver.switch_to.frame(_iframe)
time.sleep(1)
page_text = driver.execute_script("return document.documentElement.outerHTML")
03
解析数据
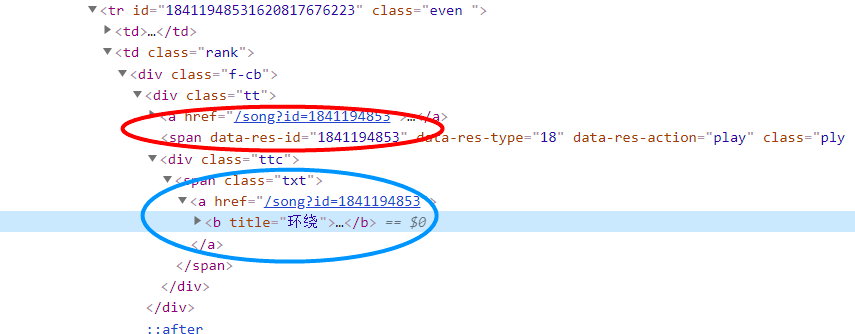
html = etree.HTML(page_text)
trs = html.xpath('//tr')
id_list = []
song_name_list = []
singer_list = []
for tr in trs[1:]:
id = tr.xpath("./td[2]/div[1]/div[1]/span/@data-res-id")[0][-10:] #
id_list.append(id)
song_name = tr.xpath("./td[2]/div/div/div/span/a/b/@title")[0]
song_name_list.append(song_name)
print(id,"----",song_name)
04
保存数据

base_url = 'http://music.163.com/song/media/outer/url?id={}.mp3'
try:
for index,id in enumerate(id_list):
if index == 25: # 因为这个26首歌曲名非正常字符,要排除,否则报错
continue
file_name = song_name_list[index]
resp = requests.get(base_url.format(id))
with open(r'HotMusic/'+ file_name + '.mp3','wb') as f:
f.write(resp.content)
print('歌曲:%s下载成功' % file_name)
except Exception as error:
print(error)
05
运行程序
· 推荐阅读 ·
评论