
OLAP 技术选型:对什么进行选型?
OLAP 技术架构
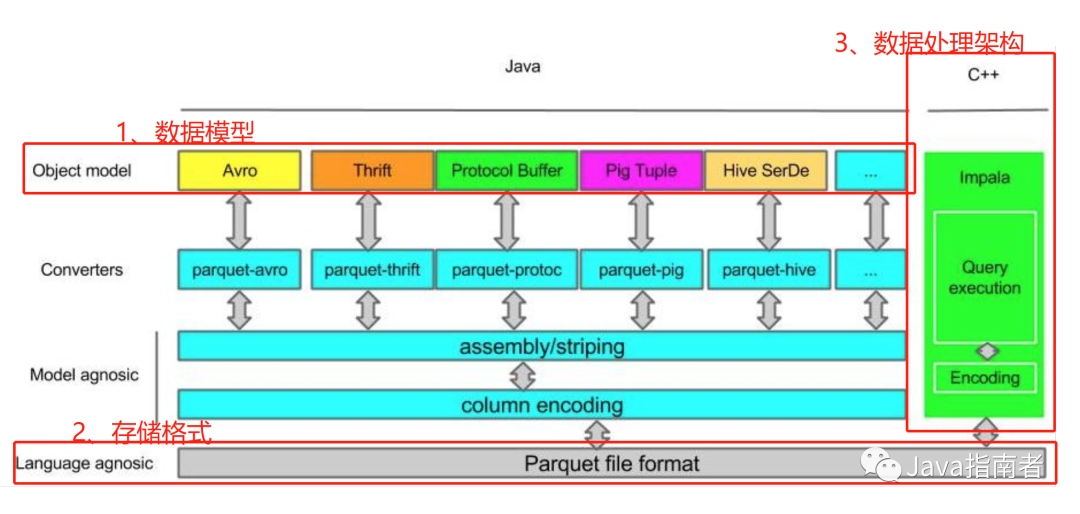
数据模型
基于 SOAP 消息格式的 WebService
基于 JSON 消息格式的 RESTful 服务
Google protobuf
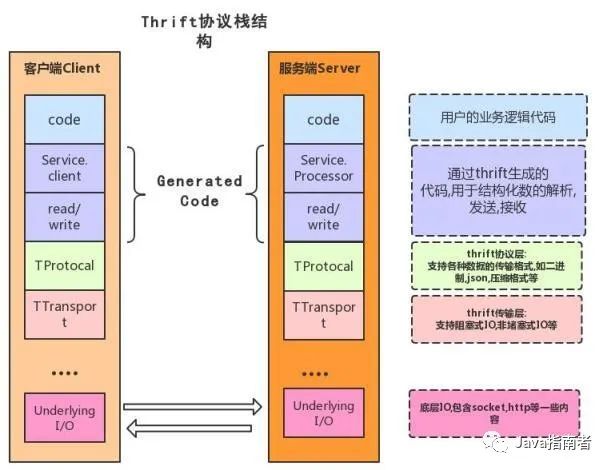
Apache Thrift
Apache Avro
使用编程语言的内置序列化,如 Java 序列化、Ruby 的 marshal,或 Python 的 pickle。
然而,你意识到困在一种编程语言中是很糟糕的,所以转而使用一种广泛支持的、与语言无关的格式,比如 Json。
然而,你发现 JSON 太过冗余,解析太慢,不能区分整数和浮点数,并且你认为自己非常喜欢二进制字符串和 Unicode 字符串。
然后你会发现人们使用不一致的类型将各种各样的随机字段填充到他们的对象中,这时你非常需要一个 schema 以及一些 documentation。也许你还在使用静态类型的语言,并从 schema 生成 model 类。你还会意识到,与 JSON 相似的二进制文件实际上不是那么紧凑,因为你在一遍又一遍地存储字段名。如果你有一个 schema,你可以避免存储对象的字段名,这样可以节省更多字节。
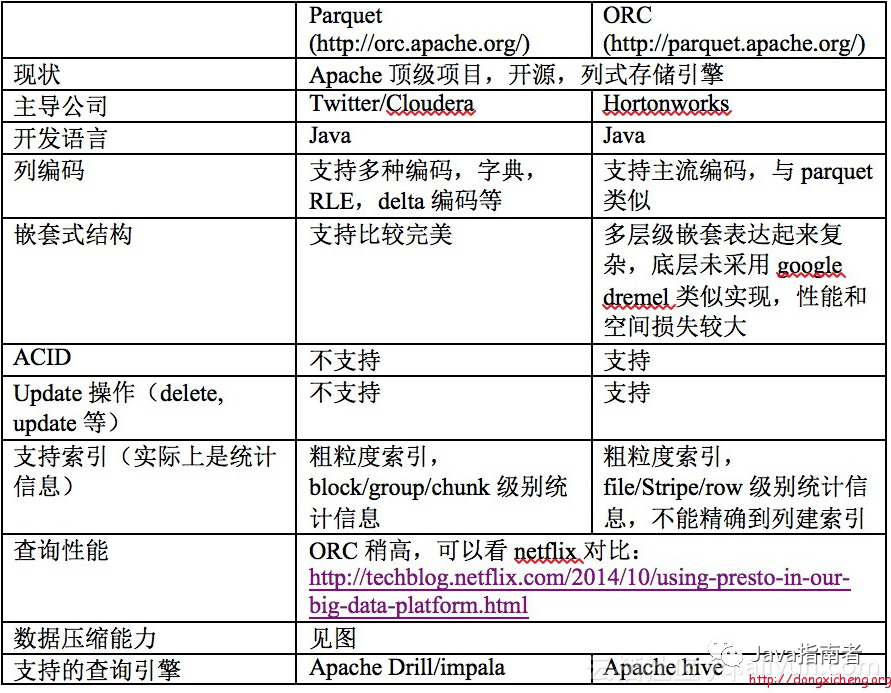
存储格式
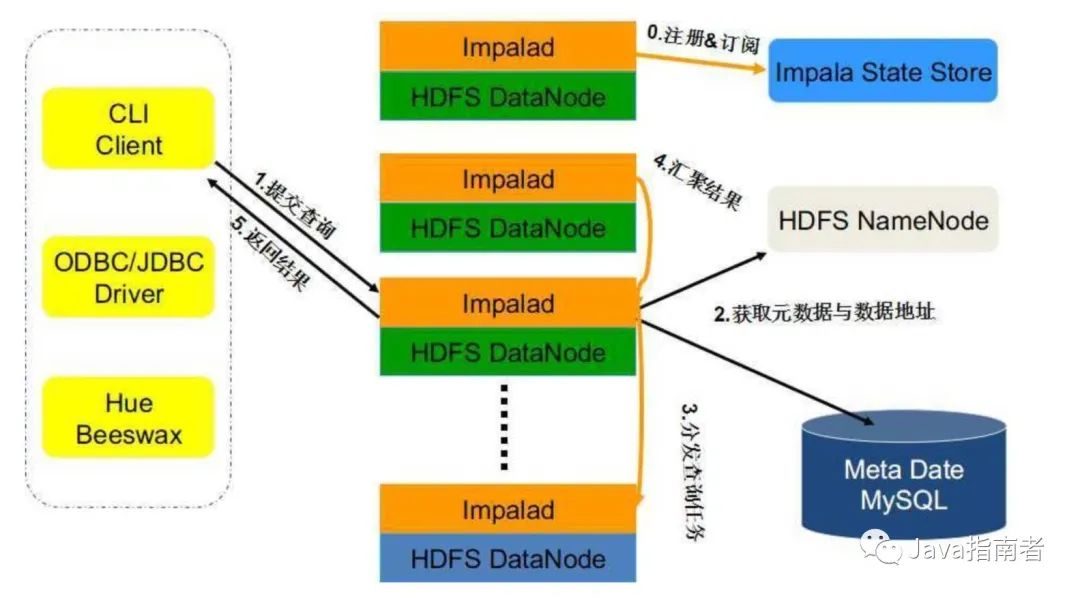
数据处理框架
对什么进行选型
但是数据处理框架所使用的存储格式对 OLAP 很多方面起到决定性作用;如下图,如果我们选型了 impala(使用 Parquet 作为存储格式),就不能期望对模式演化(schema evolution)有很好支持;再比如,如果选型了 druid(使用作为存储格式),底层查询在存储引擎上的执行过程不能向量化执行,因此在对大数据量、少量列进行聚合计算查询时性能应该是比 impala、presto 差。

通过数据处理框架所使用存储格式,再结合我们需求可以很大程度缩小选型范围;哪怎么再在这个小范围再进一步去选择符合我们场景的 OLAP 技术呢?在下篇再跟大家讲讲 OLAP 技术分类,通过这些分类我们可以进一步缩小我们选型范围,最终选择合适技术。
Hive计算最大连续登陆天数
Hadoop 数据迁移用法详解
Hbase修复工具Hbck
数仓建模分层理论
一文搞懂Hive的数据存储与压缩
大数据组件重点学习这几个