
OLAP 技术选型:对什么进行选型?
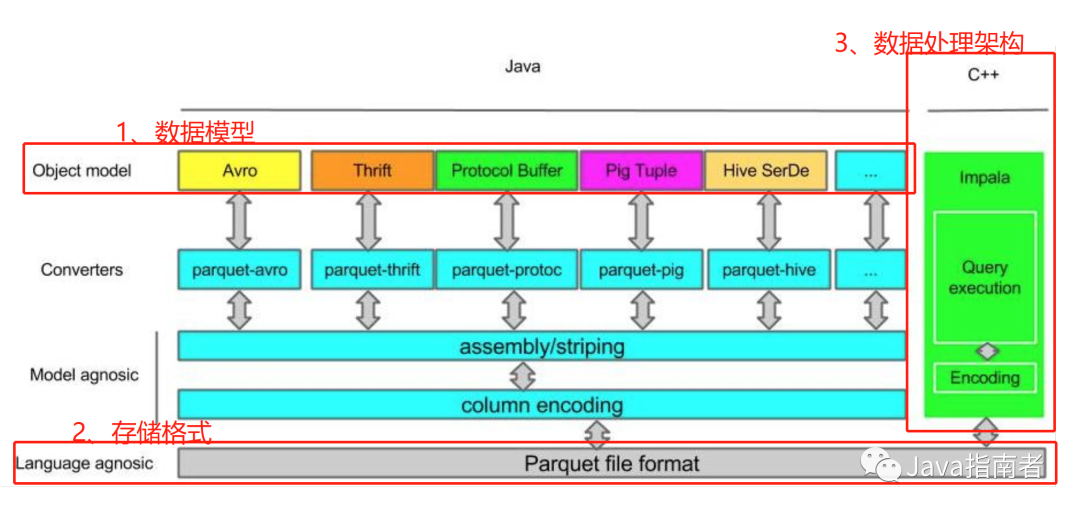
上图展现的 impala 技术架构,很直观展示了 OLAP 技术核心模块:数据模型、存储格式与数据处理架构;
数据模型
数据模型层主要是解决数据传输问题,通过对数据序列化与反序列化,同时提供了远程调用( 如 RPC )功能,从而实现跨平台、多语、客户端与服务端数据传输与通信。传统跨语言通信方案:
基于 SOAP 消息格式的 WebService
基于 JSON 消息格式的 RESTful 服务
分布式、大数据量跨语言通信方案:
Google protobuf
Apache Thrift
Apache Avro
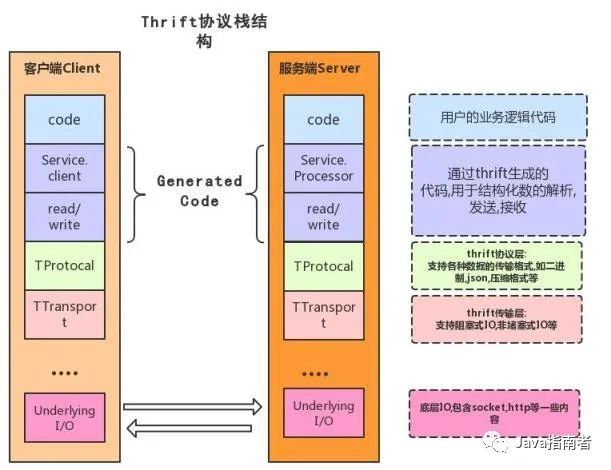
下图为 Thrift 协议栈结构,通过对结构化数据的解析,发送,接受完成数据传输
大家可能会有疑问,为什么会存在这么多通信协议与通信框架;只使用 JSON 不香吗?其实,当你想要将一些数据存储在文件中或想要通过网络发送时,你经历了一下几个演化阶段:
使用编程语言的内置序列化,如 Java 序列化、Ruby 的 marshal,或 Python 的 pickle。
然而,你意识到困在一种编程语言中是很糟糕的,所以转而使用一种广泛支持的、与语言无关的格式,比如 Json。
然而,你发现 JSON 太过冗余,解析太慢,不能区分整数和浮点数,并且你认为自己非常喜欢二进制字符串和 Unicode 字符串。
然后你会发现人们使用不一致的类型将各种各样的随机字段填充到他们的对象中,这时你非常需要一个 schema 以及一些 documentation。也许你还在使用静态类型的语言,并从 schema 生成 model 类。你还会意识到,与 JSON 相似的二进制文件实际上不是那么紧凑,因为你在一遍又一遍地存储字段名。如果你有一个 schema,你可以避免存储对象的字段名,这样可以节省更多字节。
如果你到了第四阶段,你的选择一般会使 Thrift,Protocol Buffers 或 Avro。这三种方法都为 Java 人员提供了高效的、跨语言的数据序列化(使用 schema)和代码生成。
存储格式
存储格式指的是数据在存储介质中以什么样方式进行存储;传统的关系型数据库,如 Oracle、DB2、MySQL、SQL SERVER 等采用行式存储法(Row-based),在基于行式存储的数据库中, 数据是按照行数据为基础逻辑存储单元进行存储的, 一行中的数据在存储介质中以连续存储形式存在。随着大数据的发展,现在出现的列式存储和列式数据库。它与传统的行式数据库有很大区别的。列式存储(Column-based)是相对于行式存储来说的,新兴的 Hbase、HP Vertica、EMC Greenplum 等分布式数据库均采用列式存储。在基于列式存储的数据库中, 数据是按照列为基础逻辑存储单元进行存储的,一列中的数据在存储介质中以连续存储形式存在。下图为两种主要列式存储格式 Parquet 与 ORC 比较。
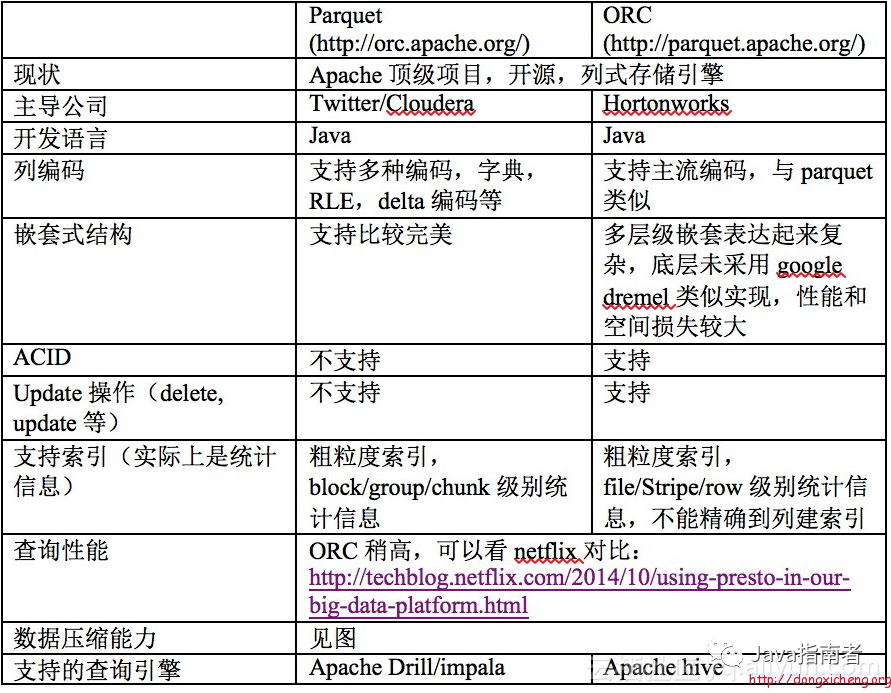
因此,选择什么样存储格式,会在很多程度上影响到是否支持模式演化(schema evolution)、是否支持 ACID、是否支持 update 操作、查询性能、数据压缩能力等
数据处理框架
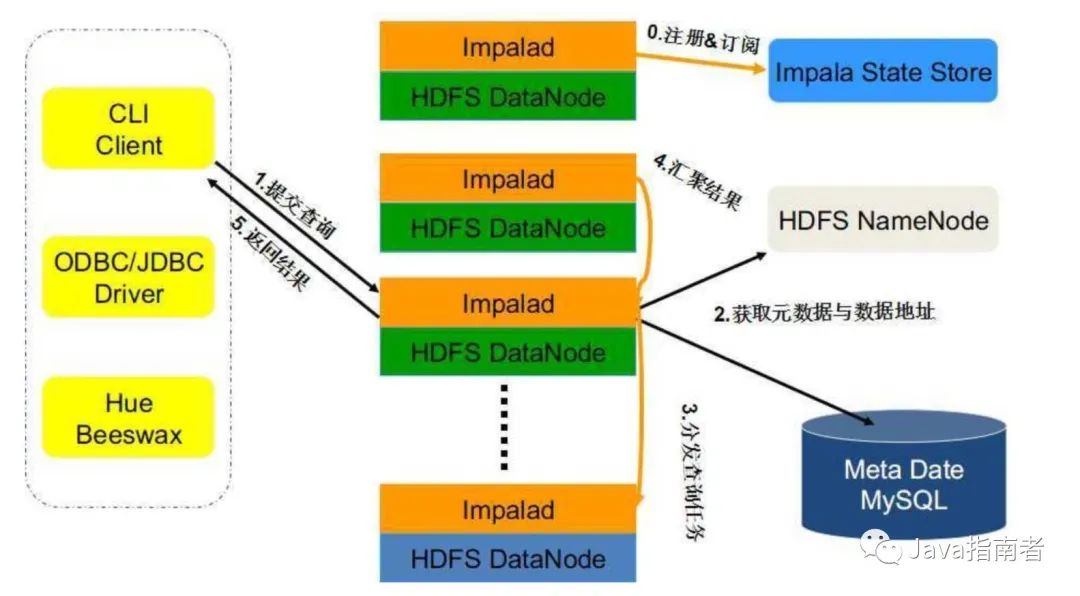
数据处理框架指的就是 OLAP 引擎或者 OLAP 工具,比如 presto、doris、doris、kylin、clickhouse、impala 等等。这些 OLAP 数据处理框架执行查询逻辑一般都会经过客户端发送 SQL 查询、引擎节点解析和分析查询语句、执行查询某个任务、向 client 发送结果集;下图是 impala 执行流程
对什么进行选型
讲了这么多,哪我们 OLAP 技术选型究竟是对什么进行选型;很明显,我们是对 OLAP 数据处理框架进行选型
但是数据处理框架所使用的存储格式对 OLAP 很多方面起到决定性作用;如下图,如果我们选型了 impala(使用 Parquet 作为存储格式),就不能期望对模式演化(schema evolution)有很好支持;再比如,如果选型了 druid(使用作为存储格式),底层查询在存储引擎上的执行过程不能向量化执行,因此在对大数据量、少量列进行聚合计算查询时性能应该是比 impala、presto 差。
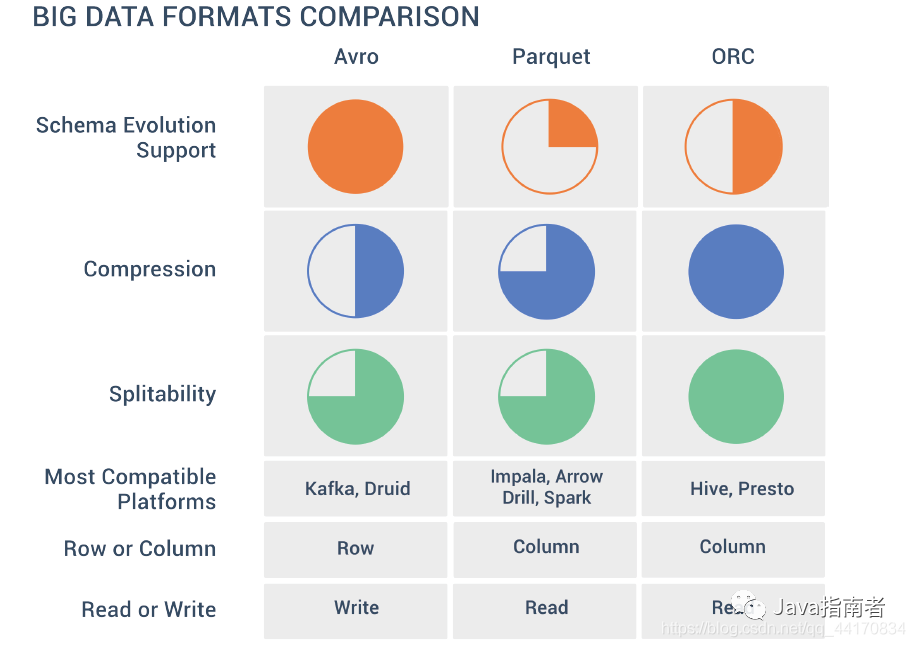
通过数据处理框架所使用存储格式,再结合我们需求可以很大程度缩小选型范围;哪怎么再在这个小范围再进一步去选择符合我们场景的 OLAP 技术呢?在下篇再跟大家讲讲 OLAP 技术分类,通过这些分类我们可以进一步缩小我们选型范围,最终选择合适技术。